In-depth understanding of IPFS (1): Beginner to Advanced Guide
This article is the first in a series of "In-depth Understanding of IPFS" series. This series will help you understand the basic concepts of IPFS. We will try to make this series as boring as possible.
The series is divided into six sections:
● In- depth understanding of IPFS (1/6): Beginner to Advanced Guide: In this section, we will try to explain what IPFS is, why it is needed and what we can do with it. We'll take a brief look at all of the underlying components of IPFS (which will be analyzed in depth later) to see how they work together. If you want a short summary and don't want to know what's under the hood, then this part is for you.
- Technical Guide | Ethereum Wallet Development: Wallet Address Generation Process
- The Uncle Block of the Ethereum Reward Mechanism (Part 2)
- Dry goods | read the solidity programming
● In- depth understanding of IPFS (2/6): What is InterPlanetary Linked Data (IPLD)?: In this section, we will delve deeper into the data model based on content addressable networks. We will explore the details and specifications of IPLD, become familiar with IPLD and use it.
● In- depth understanding of IPFS (3/6): What is the Star naming system (IPNS)?: In this part, we will delve into the naming system of distributed networks. We will study its usage specifications and how it works, and compare it to today's naming system (DNS) to list the strengths and weaknesses of IPNS and DNS.
● Understand IPFS (4/6): What is MultiFormats? In this section, we will discuss why we need MultiFormats, how does it work, and what can you do as a user/developer?
● Deep understanding of IPFS (5/6): What is Libp2p? In this section, we will study the network layer of IPFS and its huge contribution to IPFS. We will explain it through its work, specifications and usage methods so that everyone can understand it more clearly.
● In- depth understanding of IPFS (6/6): What is Filecoin? In this section, we will discuss the incentive layer of IPFS, Filecoin. We studied Filecoin's white papers and implementation specifications, including DSN Distributed Storage Network, replication certification, storage certification, data storage market and retrieval market, and implementation of smart contracts based on the Filecoin protocol. We also discussed some of the flaws in the Filecoin protocol that were not mentioned in the white paper and suggested some improvements to the Filecoin protocol.
I hope you can learn a lot about IPFS from this series . let's start!
When you ask someone about the latest "Avengers" movie, they may not say "in this subdomain on this server, then in this file path, the slash "Marvel" slash "Avenger" Alliance "point mp4" and the like. Instead, they describe the content of the video: “Half of the universe is destroyed by the tyrant…” For humans, this is obviously the most intuitive way to think, but this is not the way we access content on the web today. Nonetheless, distributed protocols such as IPFS use content-based addressing (using file-based content tagging and lookup content) to find content stored on distributed networks. In this article, we'll explore how the entire IPFS works, what different components are involved, and how they work together. To do this, we will add a file to IPFS and then investigate what happens when we add files to IPFS.
Let's first add a photo to IPFS. We add this…
https://unsplash.com/photos/rW-I87aPY5Y
By the way, you must have IPFS installed on your computer system to work with me. Can be installed from here. After installing IPFS, the IPFS daemon must be started (the software communicates with the IPFS network to add and retrieve data from the network). You can start the daemon ipfs daemon in the following way:
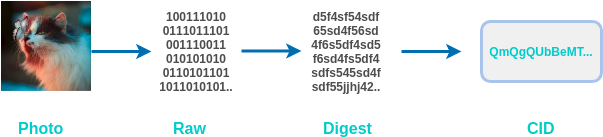
When you add a photo to IPFS, the following happens:
At the terminal I got this:

You can see the last hash value here:
But we didn't see anything related to the middle 2 steps (Raw and Digest). It all happened under the "hood."
When we add an image, we convert the image to Raw that the computer can understand . Now that it has content addressing (which we discussed above), we have to figure out a way by which we can convert this image data into a label that needs to have the uniqueness of the content that identifies it. .
This is where the hash function comes into play.
The hash function takes the data (any data from text, photos, the entire Bible, etc.) as input and gives an output (Digest) whose output must be unique. If we change a pixel in this image, the output will be different. This is its tamper-proof feature that makes IPFS a self-certifying file system. Therefore, if you transfer this photo to someone else, he/she can easily check if the received photo has been tampered with.
Also, you can't know what the input is (in this case, a cat's photo), but only its output (Digest). Therefore, this also ensures the security of the content.
Now we pass Raw Data (raw image data) to the SHA256 hash function and get a unique digest. Now we need to convert this digest into a CID (Content Identifier). When we try to retrieve the image, IPFS will search for this CID (content identifier). To this end, IPFS uses a technology called Multihash.
To understand the importance of Multihash, consider this situation.
You store an image on the internet and you have its CID, which you can provide to anyone who wants to get it. But what if you find that SHA256 is corrupted in the future (which means the process is no longer tamper-proof and secure) and you want to use SHA3 (to ensure tamper resistance and security)? This means changing the entire process of converting photos to CIDs, and the previous CIDs will be useless…
In this case, the above problem may seem like a small problem, but you should know that these hash functions can get billions of dollars. All banks, national security agencies, etc. use these hash functions to ensure that they operate safely. Without it, even the green locks seen next to each site address on the browser will not work.
To solve this problem, IPFS uses Multihash. Multihash allows us to customize the hash hash. Therefore, depending on the hash function used, we can have multiple versions of the CID. We'll discuss Multihash in detail in Part 4 of this series and delve into Multiformat.
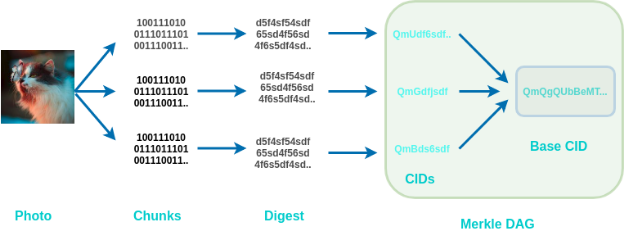
Now that we have added the photo to IPFS, this is not all. The actual situation now is this:
Large files are chunked and hashed into IPLD (Merkle DAG)
If the file is larger than 256kb, we break them down into smaller parts so that all parts are equal to or less than 256kb. We can see this command used by the photo block:
Ipfs object get Qmd286K6pohQcTKYqnS1YhWrCiS4gz7Xi34sdwMe9USZ7u
Then this gives us 15 blocks, each block is less than 256kb. Each of these blocks is first converted to a Digest and then converted to a CID.
{
"Links": [
{
"Name": "",
"Hash": "QmZ5RgT3jJhRNMEgLSEsez9uz1oDnNeAysLLxRco8jz5Be",
"Size": 262158
},
{
"Name": "",
"Hash": "QmUZvm5TertyZagJfoaw5E5DRvH6Ssu4Wsdfw69NHaNRTc",
"Size": 262158
},
{
"Name": "",
"Hash": "QmTA3tDxTZn5DGaDshGTu9XHon3kcRt17dgyoomwbJkxvJ",
"Size": 262158
},
{
"Name": "",
"Hash": "QmXRkS2AtimY2gujGJDXjSSkpt2Xmgog6FjtmEzt2PwcsA",
"Size": 262158
},
{
"Name": "",
"Hash": "QmVuqvYLEo76hJVE9c5h9KP2MbQuTxSFyntV22qdz6F1Dr",
"Size": 262158
},
{
"Name": "",
"Hash": "QmbsEhRqFwKAUoc6ivZyPa1vGUxFKBT4ciH79gVszPcFEG",
"Size": 262158
},
{
"Name": "",
"Hash": "QmegS44oDgNU2hnD3j8r1WH8xZ2RWfe3Z5eb6aJRHXwJsw",
"Size": 262158
},
{
"Name": "",
"Hash": "QmbC1ZyGUoxZrmTTjgmiB3KSRRXJFkhpnyKYkiVC6PUMzf",
"Size": 262158
},
{
"Name": "",
"Hash": "QmZvpEyzP7C8BABesRvpYWPec2HGuzgnTg4VSPiTpQWGpy",
"Size": 262158
},
{
"Name": "",
"Hash": "QmZhzU2QJF4rUpRSWZxjutWz22CpFELmcNXkGAB1GVb26H",
"Size": 262158
},
{
"Name": "",
"Hash": "QmZeXvgS1NTxtVv9AeHMpA9oGCRrnVTa9bSCSDgAt52iyT",
"Size": 262158
},
{
"Name": "",
"Hash": "QmPy1wpe1mACVrXRBtyxriT2T5AffZ1SUkE7xxnAHo4Dvs",
"Size": 262158
},
{
"Name": "",
"Hash": "QmcHbhgwAVddCyFVigt2DLSg8FGaQ1GLqkyy5M3U5DvTc6",
"Size": 262158
},
{
"Name": "",
"Hash": "QmNsx32qEiEcHRL1TFcy2bPvwqjHZGp62mbcVa9FUpY9Z5",
"Size": 262158
},
{
"Name": "",
"Hash": "QmVx2NfXEvHaS8uaRTYaF4ExeLaCSGpTSDhhYBEAembdbk",
"Size": 69716
}
],
"Data": "\b\u0002\u0018Ơ \u0001 \u0010 \u0010 \u0010 \u0010 \u0010 \u0010 \u0010 \u0010 \u0010 \u0010 \u0010 \u0010 \u0010 \u0010 Ơ\u0004"
}
IPFS uses IPLD (IPLD uses Merkle DAG or called directed acyclic graph) to manage all blocks and link them to the basic CID.
IPLD (objects) consists of two components:
● Data data – blobs (binary large object) of unstructured binary data less than 256 kB in size.
● Links link – an array of structures. A link to another IPFS object.
Each IPLD link (in our case, the 15 links mentioned above) has 3 parts:
● Name Name – the name of the link
● Hash hash – the hash of the linked IPFS object
● Size size – the cumulative size of the linked IPFS object, including the size of the link following it
IPLD is based on connected data, which has been discussed by people in the distributed network community for a long time. This is what Tim Berners-Lee has been doing for years, and his new company Solid is working around it.
There are other benefits to using IPLD. To explain this, let's create a folder called photos and add 2 photos (a photo of the cat with a copy of the same photo).

As you can see, both photos have the same hash value (this proves that I have not changed anything in the image copy). This adds a deduplication attribute to IPFS. Therefore, even if your friend adds the same cat photo to IPFS, he will not copy the image. This saves a lot of storage space.
Imagine if I stored this article on IPFS, each of its letters is chunked and has a unique CID, then this article can be composed of letters (uppercase and lowercase), numbers, and some specials. The characters are combined. We will only store each letter, number and character once and rearrange them according to the links in the data structure.
IPFS also has a naming system called the Star naming system (IPNS). To understand its importance, let's assume that you have created a website and hosted it in a domain name. For this example, we will use my website as an example: https://vaibhavsaini.com/
If I want to host it on IPFS, simply add a site folder on IPFS. To this end, I have used wget to download the website. If you are using a Linux-based operating system such as Ubuntu or MAC, then you can try it with me.
Download this website (or any website):
Wget –mirror –convert-links –adjust-extension –page-requisites –no-parent Https://vaibhavsaini.com
Now add the IPFS folder named vaibhavsaini.com:
Ipfs add -r vaibhavsaini.com
You will get the following:
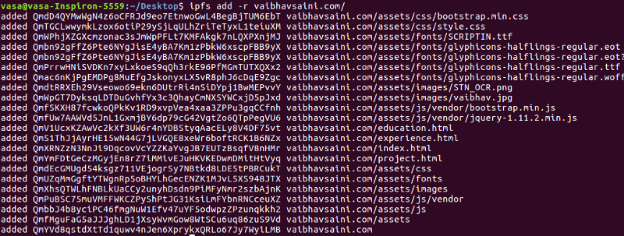
We can see that our website is now hosted on the last CID (ie the CID of the folder):
QmYVd8qstdXtTd1quwv4nJen6XprykxQRLo67Jy7WyiLMB
We can access the site using the http protocol:
https://gateway.pinata.cloud/ipfs/QmYVd8qstdXtTd1quwv4nJen6XprykxQRLo67Jy7WyiLMB/
Suppose I want to change the picture of my profile on the website. As we have already seen above, if we change the input, we will get a different Digest, which means my final "CID" will be different.
This means that every time I update my site, I have to update the hash, and people who have links to my previous site (the above URL) can't see my new site.
This will cause a very serious problem.
To solve this type of problem, IPFS uses the Star Named System (IPNS). Use the IPNS link to point to the CID. If I want to update my website CID, I just need to point the new CID to the corresponding IPNS link (this is similar to today's DNS). We will delve into IPNS in Part 3 of this series.
But for now, let's generate an IPNS link for my website .
Ipfs name publish QmYVd8qstdXtTd1quwv4nJen6XprykxQRLo67Jy7WyiLMB
This may take a few minutes, and finally you will get this output:
Published to Qmb1VVr5xjpXHCTcVm3KF3i88GLFXSetjcxL7PQJRviXSy: /ipfs/QmYVd8qstdXtTd1quwv4nJen6XprykxQRLo67Jy7WyiLMB
Now, if I want to add a new CID, I will use the same command
Ipfs name publish <my_new_CID>
Using this feature, you can access the updated version of my website using the following link: https://gateway.pinata.cloud/ipns/Qmb1VVr5xjpXHCTcVm3KF3i88GLFXSetjcxL7PQJRviXSy
But the above link address is still not easy for humans to read. We are used to the name : https://vaibhavsaini.com. In Part 3 of this series, we will see how to link IPNS to a domain name so that you can see my IPFS hosting site at https://vaibhavsaini.com.
IPFS is also a potential replacement for the HTTP protocol . But why do we have to replace HTTP? It seems to work fine, right? I mean, you can still read this article and watch movies on Netflix, all of which are using the HTTP protocol.
Even if it seems to be good for us, it has some big problems.
Suppose you are sitting in a large classroom and your professor asks you to visit a specific website. Each student present has made a request to the website and responded. This means that the same data is sent separately to each student in the room. If there are 100 students, there are 100 requests and 100 responses. This is obviously not the most effective way of doing things. Ideally, students will be able to use the information they get from each other to more efficiently retrieve the information they need.
If there are some problems in the network communication line and the client cannot connect to the server, there will be a big problem with HTTP. This can happen if the ISP is interrupted, something is blocked by a country, or the content is simply deleted or moved. These types of broken links exist almost anywhere on the HTTP network.
Location-based HTTP addressing models encourage centralization. It's convenient to entrust all of our data to a few applications, but because of this, a lot of data on the web becomes dirty. This makes these providers have tremendous responsibility and authority over our information.
This is where Libp2p comes into play. Libp2p is used for data communication on IPFS networks and discovers other nodes (computers or smartphones). The way it works is that if every computer and smartphone is running IPFS software, then we will be part of a larger BitTorrent network, each of which can act as both a client and a server. Therefore, if 100 students request the same website, they can request website data from each other. Such a system can significantly increase the speed of the Internet if it is implemented on a large scale.
Ok, let's talk about it here. If you can stick to it, then you should be encouraged. well done!
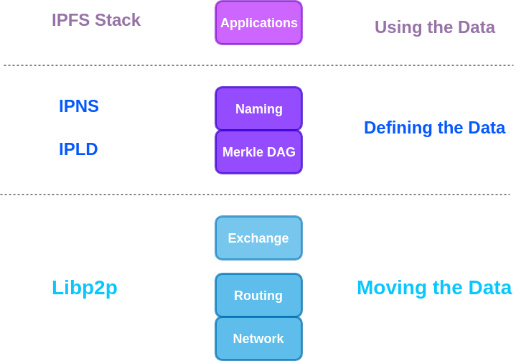
So far, we have learned a lot about IPFS. Let us review:
● IPFS is content-addressable. The data on the IPFS is identified using the CID.
• These CIDs are unique to the data it references.
● IPFS uses a hash function as its tamper-resistant property, which makes IPFS a self-certifying file system.
● IPFS uses Multihash, which allows different versions of CID to be used for the same data (but this does not mean that CID is not unique). If we use the same hash function, then we will get the same CID. We will discuss this issue more in Part 4 of this series.
● IPFS uses IPLD to manage and link all data blocks.
● IPLD uses Merkle DAG (also known as directed acyclic graph) data structures to link data blocks.
● IPLD also adds deduplication to IPFS.
● IPFS uses IPNS to link CIDs to fixed IPNS links. This technique is similar to today's centralized Internet DNS.
● IPFS uses Libp2p to communicate data on IPFS networks and discover other nodes (computers and smartphones), which can significantly increase your Internet speed.
The following is a graphical representation of the IPFS stack:
Original author: vasa
Original link: https://hackernoon.com/understanding-ipfs-in-depth-1-5-a-beginner-to-advanced-guide-e937675a8c8a
Translation: StarCraft Continental Overseas Team
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
