Technical Guide | IPFS Relationship Genealogy, Technical Framework and Working Principle
In the last issue of [Advanced Small Class], we analyzed the many disadvantages of the Internet currently constructed by the HTTP protocol, and introduced the basic concepts of IPFS and how IPFS builds the next-generation Internet. Click the image below to view . Today, mine brother and everyone share the relationship genealogy and technical architecture of IPFS.


IPFS relationship graph
IPFS was launched by Juan Benet (Juan Bennett) in May 2014. In 2015, the project "IPFS" he created won awards and received angel investment in the Y Combinator startup incubation competition, and also established a protocol laboratory.
- Technical Primer | GHAST Rule Upgrade (Part 1)
- Why is Filecoin different? IPFS founder talks about its proof system
- Technical direction: Bandwidth optimization in transaction forwarding (1)
IPFS is essentially a distributed storage and transmission protocol for content addressable, versioned, peer-to-peer hypermedia. The goal is to supplement or even replace the hypertext media transfer protocol (HTTP) used in the past 20 years, hoping to build faster, The era of safer and freer Internet.

When the protocol laboratory team develops IPFS, it adopts a highly modular integration method to develop the entire project like building blocks. Among them, the three modules of IPLD, LibP2P and Multiformats serve the bottom layer of IPFS. And Filecoin is the incentive layer of IPFS, and the value of IPFS application data.

Mutiformats is a collection of hash encryption algorithms and self-describing methods. It has 6 mainstream encryption methods including SHA1 \ SHA256 \ SHA512 \ Blake3B, which are used to encrypt and describe the generation of nodeID and fingerprint data. It is based on existing protocols. Self-descriptive transformation of the value, that is, you can know how it is generated from the value.
libP2P is the core of the IPFS core. In the face of various transport layer protocols and complex network equipment, it can help developers quickly establish an available P2P network layer, quickly and cost-effectively. The main functions of libp2p include: discovering nodes, connecting nodes, discovering data, and transmitting data. It is similar to a real-world courier company. It connects tens of millions of nodes. In addition to distributing data, it is also responsible for finding data.
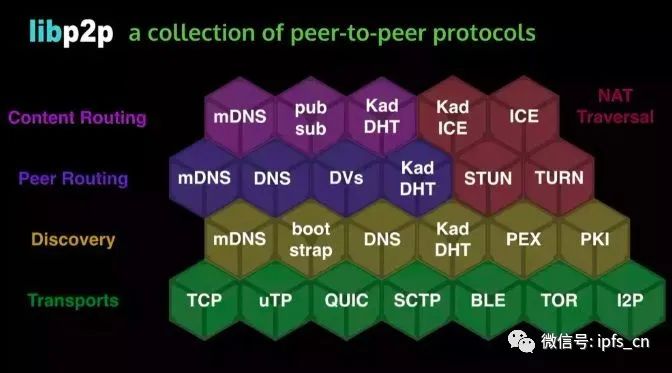
IPLD is a conversion middleware that unifies existing heterogeneous data structures into one format, facilitating data exchange and interoperability between different systems. IPLD now supports block data from mainstream public chains such as BTC, ETH, and EOS. IPLD middleware can unify different block structures into one standard for delivery, providing developers with high standards of success without worrying about performance, stability and bugs. This is also why IPFS is popular among many blockchain projects. the reason.
IPFS uses the functions of these modules and integrates it into a containerized application program, which runs on an independent node and is accessible to everyone in the form of a Web service.

Since IPFS is an open source protocol, everyone can use IPFS for free development. At present, the number of nodes in the IPFS network is not enough, and the network is not stable enough. In order to allow IPFS to be popularized quickly, Protocol Lab created the Filecoin blockchain project based on the IPFS network to encourage miners participating in IPFS nodes and storing data. Filecoin values the data of these applications, and through an incentive policy and economic model similar to Bitcoin, let more people create nodes and let more people use IPFS.
Filecoin is an IPFS economic incentive system, which carries the value transfer of IPFS and maintains the development of the IPFS ecology.
Beginning with the next [Advanced Small Class], we will focus on the introduction of Filecoin.

IPFS technical architecture
IPFS has eight layers of sub-protocol stacks. From low to high, they are identity, network, routing, exchange, object, file, naming, and application. Each protocol stack has its own function and matches each other.

Identity layer and routing layer
The identity and routing layers can be explained together. The generation of identity information and routing rules for peer nodes are generated through the Kademlia protocol. The essence of the KAD protocol is to build a distributed loose hash table (distributed hash table), referred to as DHT, each of which joins this People in the DHT network must generate their own identity information, and then use this identity information to be responsible for storing resource information and contact information of other members in this network.
Just like WeChat business card sharing, if you can't search WeChat directly, if you want to find a person, you can establish a connection by sharing the business card with a friend who has that person's contact information.
Network layer
The network layer is the core layer of IPFS technology. The lib2p used can support any transport layer protocol. The ICE NAT traversal framework integrates STUN, TURN and other types of NAT protocols. The framework allows clients to use various NAT methods to get through the network to complete NAT communication, which is very important for IPFS p2p networks.
Switch layer
The exchange layer is a BT tool like Thunder and eMule. The IPFS team has innovated BitTorrent called Bitswap. It adds a credit and billing system to encourage nodes to share. Users can increase the credit value when sending data to other nodes. Receiving data from other nodes reduces the credit value. If users only receive data without sharing data, the credit score will become lower and lower and ignored by other nodes.
Object layer and file layer
The object layer and the file layer can also be combined. They jointly manage 80% of the data structures on IPFS. Most data objects exist in the structure of Merkle DAG, which provides convenience for content addressing and data deduplication; the file layer is a new data structure, parallel to DAG, and uses the same data structure as Git to support version snapshots.
Named layer
It has the characteristics of self-verification (when other users obtain the object, the fingerprint public key is used for verification, that is, whether the public key used matches the NodeId, which verifies the authenticity of the user's published object, and also obtains the variable state ), And the ingenious design of IPNS is added to make the encrypted DAG object name definable and enhance readability.
Application layer
The core value of IPFS lies in the applications running above. You can use its CDN-like functions to obtain the desired data at a low cost bandwidth, thereby improving the efficiency of the entire application.

How IPFS works
IPFS is addressed based on file content. IPFS assigns a unique hash value to each file (file fingerprint: created according to the content of the file), even if the content of the two files is only 1 bit different, the hash value is also different. So IPFS is based on file content addressing, unlike traditional HTTP protocol based on domain name addressing.



We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Viewpoint 丨 Ethereum 2.0 technology sharing
- Analysis of Cosmos cross-chain solution
- Technical Perspective | How easy is it to implement BTC double payment with the RBF protocol?
- Dry Goods | Basic Principles of Chainlink Predictor
- Technical Guide | A First Look at the ODIN Protocol
- Introduction to Technology | Understanding Bulletproofs of Zero-Knowledge Proof Algorithms: Range Proof II
- Technical Guide | Building IPFS Applications with Node.Js
