Comparison of IPFS and EdgeFS for Secure Edge/IoT Computing Use Cases

Data security is a major challenge for Edge/Fog computing growth. Learn how to overcome the problem by introducing the modern distributed data layer EdgeFS.
We have been clearly demonstrating Edge/Fog computing transformations by reducing bandwidth consumption, improving analysis efficiency, improving the necessary response time for events in the physical world, and not relying on WAN (Wide Area Network) to maximize uptime. . Cellular phones with less reliable reliability like cable TV, and higher security.
In terms of security, the benefits come from protecting assets close to data sources that are never intended to connect to a wider network, let alone the Internet.
- Five major problems read through the PoA consensus algorithm
- Analysis | Pre-selection and pre-submission mechanisms for Byzantine fault-tolerant consensus
- Unlock Bitcoin for more apps, Miniscript yesterday, today and tomorrow!
However, as applications, data, and computing services are pushed away from the central location, data segments must be replicated in more and more distributed networks. With this in mind, data security remains a major challenge for Edge/Fog computing growth.
To address these challenges, we need conceptually new distributed data distribution and access layers that are designed with Edge/Fog security in mind.
Let's compare two open source distributed storage tier designs that might be suitable for data security needs: EdgeFS (http://edgefs.io, Apache license) and IPFS (interstellar file system https://ipfs.io, MIT license) ).
When we design EdgeFS, data security is our number one priority. In EdgeFS, once recorded, the data in any given block cannot be changed retroactively, as this invalidates all SHA-3 hashes in the previous block in the n-ary tree of a similar blockchain and breaks the scattered position. A consensus reached between the two. The same is true about IPFS.
EdgeFS is built on top of the architecture with immutable self-verifying location-independent metadata that references self-validated location-independent payloads.
Although the two storage solutions handle the payload blocks very similarly, the differences in how objects are named and discovered are almost different. IPFS is primarily used for peer-to-peer accounting transactions, while EdgeFS does not make such settings, but instead focuses on the extreme performance of many local or remote content addressable network operations.
Immutable payload block
The end result of placing a block of data into IPFS is to use a strong cryptographic hash to identify and verify it, and a cryptographic hash can be used to find the block to retrieve. This is very similar to EdgeFS, but there are some differences:
IPFS accepts the block and then generates its cryptographic hash. An EdgeFS client (via the CCOW "cloud copy on write" gateway library API) hashes the storage block before requesting it. This avoids the transmission of duplicate payload blocks, also known as deduplication, which is a distributed storage solution. EdgeFS routes the I/O request to the target group and then quickly negotiates within the group to find and dynamically place the new block on the least loaded target. This improves capacity balancing, storage device utilization, also known as dynamic data placement.
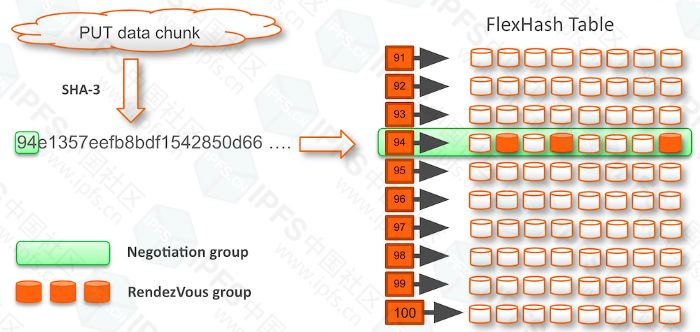
The EdgeFS FlexHash table is a local site construct. It is automatically discovered and resides in the server memory of the local site. FlexHash is responsible for I/O paths and plays an important role in dynamic load balancing logic. Based on the discovered site topology, it defines so-called negotiation target groups, which are typically formed between 8-24 partitioned storage devices to ensure proper fault domain distribution.
Differences in the principle of metadata
The IPFS naming system is still under development, and the examples show that IPFS uses a very different approach to publishing content accessed by name.
IPFS accepts cryptographic hashes of atomic objects and embeds these references into other named objects whose basic function is as a directory.
Each of these directory objects is also immutable, referencing specific freeze-time content. The directory object itself has a cryptographic hash that can be referenced in a higher-level directory. Finally, publish a "root" directory and then point to the directory object mapping with a mutable name. I suspect that this design is affected by the need to provide a highly secure persistence layer for the cryptocurrency ledger algorithm at the expense of general storage flexibility and performance.
EdgeFS takes a different approach, with the goal of enabling shared data repositories for versioned content that can be accessed and updated simultaneously by thousands of tenant-approved users and supports cross-site consistency groups.
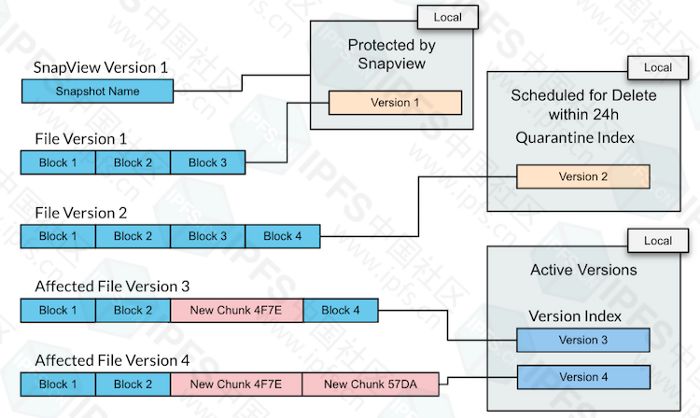
In EdgeFS, information that looks up a storage object by name or other search criteria is supported, always as a metadata record that is independent of the payload. It treats the stored payload as an opaque block, and the organization on the disk does not need to look up references within the block itself, allowing end-to-end encryption of the client driver. That is, it assumes that all payloads are encrypted and never attempts to parse it. Variable metadata information is always stored locally (local site cluster), enabling always-on, immediate-consistent I/O policies without sacrificing flexibility or performance.
Immutable version metadata
By definition, most metadata about a particular version of an object must be immutable. Some metadata can be independent of version content, such as metadata that controls object version retention, local site replication overrides, ACLs, and so on.
One of the advantages of IPFS is that when a variable naming reference is changed to point to a new version, it does not change the storage of the directory object. This is very similar to the way EdgeFS handles variable naming references, which in my opinion is far better than creating explicit versioned names. In EdgeFS, variable naming is always assumed to be local and "re-hydrated" when transmitting from a remote site to a site. This allows cross-regional transfers to remain constant, so global replication can be achieved, effectively avoiding unnecessary network traffic, ie, inline deduplication over the WAN.
summary
The modern metadata storage subsystem has many other features that are required for versioned content storage that IPFS does not seem to address:
Quickly find names in any given folder / directoryPredictable directory or bucket search timesTenant control that controls tenant metadata-driven access and modification of the reference load.
While I acknowledge that the primary and initial goal of IPFS is not to serve Edge/Fog computing use cases, its security and global scalability benefits do meet the requirements. Maybe one day it will meet other needs. But why wait? EdgeFS is now available, meeting the most important requirements for Edge/Fog computing – data security, cost reduction and performance.
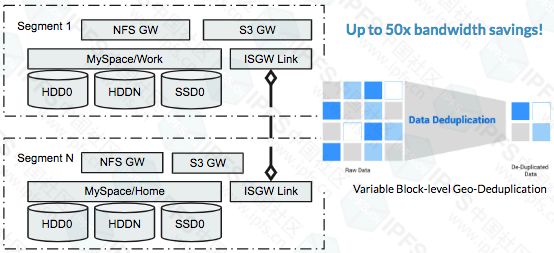
EdgeFS leverages local site resources and presents them as highly available cluster segments that are part of a geographically dispersed data layer. Due to its immutable data structure design, dynamic data placement via UDP-based low latency protocol, built-in multi-protocol storage gateway (S3, NoSQL DB, NFS, iSCSI, etc.) and highly scalable, share-free architecture for local sites Performance is outstanding. Support for applications designed for the Edge / Fog computing era.
EdgeFS leverages locally available site resources and presents them as highly available cluster segments that are part of a geographically dispersed data layer. Thanks to its immutable data structure design, dynamic data placement via UDP-based low latency protocol, built-in multi-protocol storage gateway (S3, NoSQL DB, NFS, iSCSI, etc.) and high scalability, enabling excellent local sites Performance features A shared-nothing architecture can be a true enabler for applications designed for the Edge/Fog computing era.
Original author: Dmitry Yusupov (Nexenta Systems CTO and founder)
This article is compiled by the IPFS Chinese community.
Original link: https://hackernoon.com/comparison-of-ipfs-and-edgefs-for-secure-edgeiot-computing-use-cases-0dgu30zk
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Technical Guide | Teach you to discuss Wasm contract development: (C++)
- Getting started with blockchain | Ethereum 2.0 terminology at a glance
- Defects of the heaviest chain rule: "The Crown Prince" in the "Public Ancestral Blocks"
- Technical Perspectives | Reflections on Citation Dynamic Language Object Models in Virtual Machines
- Technical Guide | Teach you to discuss Wasm contract development
- Getting started with IPFS | 50 questions about IPFS (4)
- How To | Install IPFS and IPFS Clusters on Raspberry PI
