Breaking the blockchain impossible triangle (3) – POS and POW-DAG
In the previous article, we mainly discussed why POWs are not extensible and how to implement scalable POWs. Let’s take a look at the logic again –
1, POW is a fair computing-based random generation method, however, its effectiveness is based on time, that is, when calculating the probability of successfully dig out the block, not only consider your Calculate the ratio m of the total power, but also consider the time t of your effective mining. In other words, although we always say that if a malicious node does not have more than 50% of the computing power, it can't attack Bitcoin. However, time t is not considered here. That is to say, 50% of the establishment here is based on the effective mining of honest nodes.
2, then, what is effective mining? In Bitcoin's POW, only mining on the longest chain is called effective mining. If and when a legal block is dug up, the chain that actually has the legal block becomes the longest chain. At this time, even if you have dug in the original block for a second because you have not come and received a new block, you are actually ineffective mining . But for Bitcoin POW, I haven't thought about avoiding invalid mining from the beginning. The thing it does is to make the calculation of the invalid mining loss negligible compared to the required total power, so we still have nearly 50% safety.
3, then, when is this wasted computing power not to be ignored? There are two situations, a) when the wasted computing power increases; b) when the target computing power is reduced. When the block is enlarged, since the time required for the block to be synchronized becomes longer, so from the time when a miner releases the effective block, the time for other miners who have not yet had time to complete the synchronous mining is also longer, so more The power of calculation is wasted. Reducing the block spacing is equivalent to reducing the target difficulty. Both will increase the proportion of wasted computing power in total computing power, resulting in a decrease in the security of the POW algorithm.
- Video|"8Q" HashQuark Li Chen: PoW spelling power, hard core! PoS fights soft power and diversity!
- Market Analysis: BTC continues to be at $8,000, the main force is more patient than expected
- Market Analysis: BTC continues to shrink, has to change?
3.5, what we need to pay attention to here is that it is not only when the fork is forked, it means that the power is wasted, that is to say, even if the fork is not considered, the safety will decrease as the output increases. But in fact, the more serious damage to safety is the fork, because the fork will cause a certain proportion of the power will be wasted on the lone block. Whatever it is, we all see the same conclusion—the proportion of wasted power increases as the block size B (approxes) increases, decreasing as the block interval s (approxes) increases, while B/s It is precisely the output of Bitcoin. So, the flaw of Bitcoin POW is –
The security of Bitcoin is inversely proportional to the output. As the output continues to increase, the security of Bitcoin POW approaches infinity to zero.
4. Therefore, in order to obtain higher output, we need to improve the POW algorithm of Bitcoin, so that miners can mine more effectively, that is, remove the limitation of POW for effective mining. So how can we mine more effectively? In POW, only mining on the longest chain is effective mining, that is, only the latest block can be synchronized first, that is, all transactions can be synchronized, and effective mining can be carried out, and it is only after the new area is mined. Start synchronizing for the new block, which means that the relationship between the two is interdependent.

5, therefore, in order to improve the Bitcoin POW, we have to remove the POW's security dependence on synchronous transactions, that is, the transaction must be decoupled from the POW. To put it another way, it is absolutely not necessary to limit the mining of miners to the entire book.
The above is the reasoning process of extending the Bitcoin POW. It should be said that each ring inside is necessary – that is to say, any algorithm that uses POW for consensus needs to consider these issues and will be subject to the same restrictions.
Then, we discussed two ideas for parallelizing transmission and POW –
1, the leader chooses: use mining to determine the blocker rather than the content, that is, the transaction. In this case, effective mining does not require synchronization of all transactions, but only "all nodes can synchronize the current correct block", and this is easy to do. However, its flaw is that it is not binding on the malicious behavior of malicious people. Because if we still follow the logic of "discovering a malicious transaction and not accepting and forking", it is equivalent to making the POW dependent on the synchronization of the transaction. Therefore, we only have two choices – a) to punish the malicious blocker by some means; b) to ensure that the blocker does not do evil. The former is the method used by Bitcoin-NG – if there is a blocker in front of it, then the latter player can take all the rewards of the previous blocker through some special transactions. The latter can not only select one outlier, but need to select a lot of outliers, that is, a committee. For example, we select the block publishers of the first 20 blocks (ie, the top 20 miners who successfully calculated the target hash value). Then the committee internally determines a block by the BFT algorithm. The problem to be considered here is that the committee can't have more than 1/3 of malicious nodes (because of BFT), and this can only be guaranteed by probability. For example, when the malicious power in the whole network is less than 1/4. We can guarantee the selection of 20 miners through the large number theorem. The possibility that the number of malicious miners exceeds 1/3 is very small. However, we can’t say that if we only choose 4 miners, then there must be at most one miner. It is malicious. Therefore, in the end, the size of this committee determines the fault tolerance of the system. The larger the committee, the higher the fault tolerance, but because of the BFT, the delay will be even greater.
2, the calculation power on the non-longest chain is also included in the effective calculation power. At this point, we introduced GHOST. In GHOST, the longest chain consensus has been changed to the most subtree consensus, and the miner is not limited to only the previous block, but can point to other lone blocks with a depth of 1, that is, the following structure:
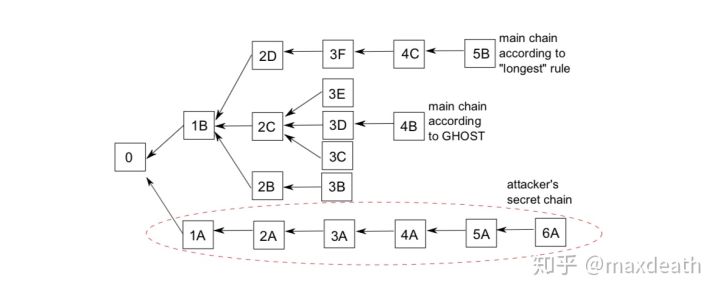 Here we compare the "severeness" of the "subtree", that is, the number of blocks, representing the computing power. According to this rule, the subtree of the lowest attacker is not as heavy as the subtree above, and the subtree of 4B is the heaviest subtree.
Here we compare the "severeness" of the "subtree", that is, the number of blocks, representing the computing power. According to this rule, the subtree of the lowest attacker is not as heavy as the subtree above, and the subtree of 4B is the heaviest subtree.
From the perspective of effective mining, the meaning of GHOST is: Even if the miner does not complete the synchronization of the latest block in time, and causes you to dig up the block after others, your calculation will not be wasted, and it is not easy. Lead to subsequent forks, resulting in waste of computing power.
However, GHOST is still not optimal, because if the time required for synchronization exceeds one block interval, the blocks you dig out may still not be included in the heaviest chain, so the computing power is still wasted. Therefore, if you draw a curve from the perspective of security and output, GHOST will behave like Bitcoin POW in the case of low output, then, as the output increases, then, in a small interval, The security of Bitcoin is declining but the security of GHOST remains the same. In other words, GHOST can boost the output to this range. Then, as the output continues to increase, the curve between GHOST and Bitcoin POW is no different and will eventually become zero.
However, we can generalize the idea of GHOST – for example, we can allow nodes to accept lone blocks of depth 2, followed by lone blocks of depth 3… Finally, all the excavated blocks are not wasted Can contribute to the security of the system. From the results, we will infinitely expand the interval where GHOST security does not change with the output, and finally get a security-independent output algorithm. In terms of implementation methods, in fact, such a system is a DAG.
The reason why I spent so much space and the bitcoin scalability is because the scalability of POS and POW-DAG and the methods they use are largely the extensible bits in the previous section. The natural evolution of the currency POW algorithm, we start with POS.
Proof of interest POS
As we saw in the previous article, the algorithms for scalable POW are basically 3-4 years ago or even earlier. The reason is simple – in academia, most people turn to POS. Here, we skip the battle between license and non-licensing and the dispute between POW and POS, so I will not elaborate on the advantages and disadvantages of POS and POW (this may be a single article I will talk about recently). But the fact is that most of the updated algorithms have chosen POS for the consensus algorithm of the non-licensed chain in academia.
POS, proof of equity, as the name implies, is the method of "the higher the computing power, the greater the probability of excavation is faster" than the POW. It is changed to "the more money, the greater the probability of digging out the block." However, compared to POW, we think of Bitcoin POW. POS is not just an algorithm, but a method of using the equity as a weight for the blocker.
Here, I skip the early peercoin and NXT POS, and also skip DPOS and Ethereum Casper. We only briefly describe some typical and more rigorous academic papers from the perspective of output, random number based POS. : Snow White, Ouroboros, Algorand and Dfinity.
Whether from the perspective of scalability or implementation, these algorithms can be said to be the corresponding choice of the leader of the scalable POW in the POS. Among them, Snow White and Ouroboros correspond to the POS correspondence of Bitcoin-NG, while Algorand and Dfinity correspond to Hybrid Consensus and Byzcoin.
However, there is a question that must be explained first – how the random numbers of these algorithms are generated.

Well…several this explanation can't be finished, so in this case, we assume that there is such a god (random oracle, Random Oracle) can propose a true random number every other time t, then we can Through this random number and the amount of money owned by each person on the current ledger, a weighted lottery is used to determine each round of the blocker…
Careful friends have noticed problems –
Are we trying to mine mine in Bitcoin so much to achieve this? You sent us now with a "God"?
However, the truth is that. In my opinion, the reason why the academic circles turned to POS later was actually to see this question: "This question is not something we have studied for a long time, we can solve it through cryptography. Also costing and time-consuming POW?"
Therefore, in fact, each of the above POS algorithms implements the function of this "God" to some extent under certain assumptions. Therefore, I am directly replacing it with "God" here, and skipping it first. The details of the implementation.
With this "God", we actually no longer have the troubles of the past, that is, we need parallel consensus and transmission troubles, because we can use almost all bandwidth * time for transmission and verification without worrying about the impact. System security. In other words, we can use the simplest cascading structure to set the block as large as possible—for example, how big a block can be synchronized in 10 minutes, and how big it is, without worrying that the consensus time is not enough and the system security is degraded. The problem.

So, since we can use all the bandwidth * time for message transmission, the algorithm of these POS and the scalable POW should be close.
Among them, Snow White and Ouroboros are similar to Bitcoin-NG, and only one leader is responsible for the block. Algorand and Dfinity are similar to Byzcoin and Hybrid Consensus, using a committee responsible for the block. Compared with the two, in terms of output, both have their own merits. The former performs better in a more honest and node-active network, because in an ideal state, this is a system where everyone is out of the block. However, it is prone to empty periods or forks when the nodes are inactive or malicious. The situation leads to a waste of bandwidth and a relatively higher acknowledgment time. Because the latter adopts the committee, this situation will only occur if the entire committee is inactive or malicious, so the probability of occurrence will decrease as the number of committees increases. However, communication between committees, usually using traditional BFT or scalable BFT, requires more time and message complexity, and can not be ignored compared to broadcasting messages to the entire network (if The communication complexity of too many people. The application scenarios of the two will be different. Personally, for the public chain, the output and delay of the latter are more stable due to the complexity of the network environment.
POW+DAG
As mentioned earlier, DAG is an extension of the GHOST idea – but there is an intermediate step before GHOST and DAG:
In GHOST, the uncle block only calculates the power but does not consider the data contained in it. So, if we continue to expand the idea of GHOST, the end result is that no matter how we increase the block size (or reduce the block interval), the power will not be wasted, so we can get more than Bitcoin POW Higher output. However, this result only guarantees that the computing power is not wasted, but the bandwidth used to propagate the blocks on the non-main chain is still wasted. For example, if we increase the block size to 100MB, then there are 3 legal blocks on average in each time period in the network. In the Bitcoin POW, this situation leads to decentralized computing and reduced security. But if the GHOST mode is adopted, this will not happen, but we will eventually need to transfer 300MB blocks every 10 minutes, and only 100MB of transactions will be retained, and the rest will be wasted, which is obviously not We want it.
So, if we choose to keep these two blocks, we get the ideal DAG –
Each miner only needs 1 package transaction; 2, try to synchronize the new block and connect it; 3, mine, and release the block after digging. Then, the end result is that whether it's your packaged deal or your mining power, it will eventually become part of the consensus. (There is a pit here, we will talk about it later)
We can understand DAG from two perspectives:
The first angle, structurally, is no longer a chain, but a graph, but more precisely, it is a strip, such as the following:
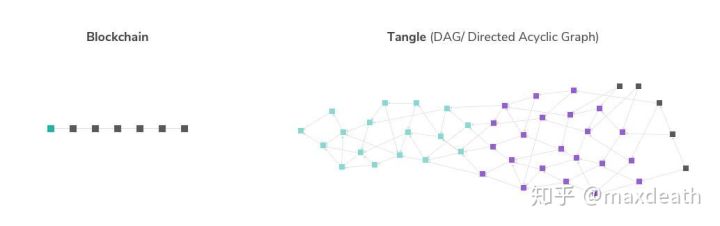 This picture of IOTA (the tangle) is still very image
This picture of IOTA (the tangle) is still very image
This picture can help us to have a very intuitive understanding of the DAG in the blockchain – because DAG (directed acyclic graph) is just a definition, but it has more than one form. From this picture, we can see that the DAG in the blockchain is probably as long as:
1, first of all, it is not a chain, but it is not a wirelessly enlarged tree-like figure, it is more like a tape, and the tape length is time, and the width can be considered as a block generated at the same time. .
2, then, the width actually represents the output of this DAG, when the width is 1 block, we actually get the blockchain. And assuming the width is 10 blocks, we are equivalent to increasing the output of the blockchain by a factor of 10.
3. The difference from the chain structure is that when the miner releases the block, it does not need to synchronize all the blocks in the network, but only needs to synchronize a part of the block. In this picture, all blocks that are before and directly or indirectly connected to it.
4. So, in the end, all the miners will still reach a consensus on all the transactions on this belt, which is the light blue part of the picture. This is what I said in the first part. DAG is not an infinite extension algorithm because it still requires all miners to reach a consensus on all nodes.
5. Finally, the premise that a block is confirmed is that it will not be forked if it has a high probability, unless someone has more than 50% of the power.
So, what is the width of this tape?
The answer is the characteristics of the network itself (such as network speed, topology) and the parameters of the blockchain itself (such as block size, spacing, etc.), while the latter, in the ideal state, should be designed to fully utilize the bandwidth of the entire network. –What is the concept? Let's change the angle:
Suppose you are a miner. The ideal state is that you are sitting on a train (digging a mine) while eating a hot pot (synchronizing blocks), singing songs (validating the transaction), and then mining the release area. In the block, you just sync and verify all the blocks in the network you found before, and during the mining, you find that the new block can be synchronized in the next round of mining…

If all the miners are in an ideal state, then the bandwidth in this network is fully utilized.
However, if a miner often appears: the train is still eating in the hot pot, then the bandwidth is not being used very well, so we can increase the block or reduce the block interval to increase the output. The effect of this increased output in the graph is that more (larger) blocks are created in the same time period, and the tape becomes wider.
Another situation is if there are a lot of miners unable to synchronize all the blocks? Obviously, this time shows that we need to lower the output. But what happens if we don't reduce the output?
First, since the capacity of the network is certain, the number of transactions that will ultimately be confirmed will certainly not increase. But the problem is, because there are too many new blocks, it is difficult for miners to reach a consensus on the newly added blocks. The end result is that this tape will become more and more Wide, not longer and longer. Therefore, most DAGs need to limit such situations, so usually the DAG will give the newly dug blocks a greater weight to encourage the band to develop in a longer rather than a wider direction. At the same time, this can also limit the behavior of malicious nodes deliberately establishing forks from old blocks.
Second, in this case, those miners who cannot synchronize all the blocks in time will not be able to add their blocks to the latest block, so their blocks cannot bring enough weight (because it is too old). It was abandoned by other nodes. In the end, these blocks and computing power will be wasted.
Third, because the network conditions and computing power of the nodes in the network are unequal, there are inevitably some nodes that have not stopped eating after the hot pot has stopped. Some nodes will have the situation that the car is finished with the hot pot. Therefore, in the end we will adjust the parameters of the blockchain so that the entire band is in a state of equilibrium between the two, in order to achieve maximum output and waste of least computation.
Sounds good, isn't it?
DAG seems to be a simple extension of the chain structure. We weaken the correlation between output and security in the chain structure. Finally, we can adjust the parameters and approximate all network capacity to achieve near-optimal output.
It seems that we have not sacrificed anything during this period, isn't it?
Unfortunately, the answer is no.
Sequencing problems in DAG
In fact, blockchain and all BFT algorithms, in addition to reaching a consensus on content (blocks), must also agree on the order of these content. In other words, the order is also an indispensable part of the consensus.
In PBFT, the first round of two rounds of communication is sequencing.
For Bitcoin POW, because of the chain structure, sequencing and consensus are simultaneous—when a miner references the previous block, it naturally indicates the order between the two blocks.
However, in DAG, although all nodes will eventually reach a consensus for all blocks, and because of the directionality of the graph, there is consensus on all the blocks on a branch, but if the two blocks are mutually Can not be directly connected, then the order between the two blocks is not consensus, for example:
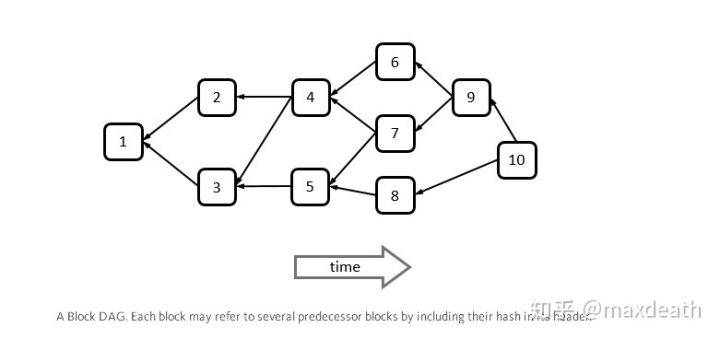 Here, the order between 6, 7, and 8 is uncertain.
Here, the order between 6, 7, and 8 is uncertain.
Some people may ask: Is the order so important?
The answer is: At some point, it may not be that important, which is why IOTA is known as "for IOT" because they know very well that IOTA's algorithm tangle is unorderable, so it cannot be used for digital currency.
Because digital currency needs to be sequenced to determine which of the two conflicting transactions is legal and which is illegal –
As mentioned before, an important step from GHOST to DAG is that we need to include all the transactions of multiple blocks generated at the same time. The two inevitable problems are:
1, repeated transactions will reduce the output, we will talk about it later.
2, conflicting transactions, such as a transaction X said A to pay the money to B, a transaction X' said A to pay the money to C, the two conflicting transactions are included in the consensus, we must necessarily have a consistent The algorithm determines which one is true, and this inevitably involves the order of the problem, but if all the nodes can't reach a consensus on the order of the two, it is impossible to reach a consensus on the legitimacy of the two transactions. The result of the inability to reach a consensus on legitimacy, on behalf of the two transactions, can never be confirmed, in other words, it is not active.
This is a very troublesome issue, so far, there are two ideas:
Idea 1: Sequence by the topology of the following blocks
This is the method that GHOST's team has been trying. From SPECTRE to PHANTOM, they all use the block virtual voting method, that is, the latter block determines who is behind.
They designed a voting mechanism so that the results of the vote can quickly converge to a certain side – assuming that due to chronological or random reasons, the block containing the transaction X is slightly more than the one containing X'. Blocks, then, this algorithm will ensure that the results will become more and more overwhelming toward X over time, eventually converge to X quickly.
But the problem with this design is that there is no guarantee that the result of the vote will be biased towards one side—especially the malicious node can maintain the balance between the two sides with little computational power.
SPECTRE's solution to this problem is: no solution.
SPECTRE made the assumption that this is a virtual currency. If X and X' appear at the same time, then A must sign two conflicting transactions in a short time, then he is a malicious node. Therefore, we do not have to guarantee the activity of such a transaction. That is to say, if a malicious node wants to balance the two almost heavy branches to make it impossible for others to confirm that the two transactions are legal, then go with it, anyway, this is a malicious node transaction.
And for transactions made by honest nodes, we can guarantee activity and confirm the order between any two transactions.
But this assumption has caused the limitations of SPECTRE to make him unable to act as an algorithm for Turing's complete blockchain system, because there is a need for complete ordering. Because smart contracts may need to determine the order of messages published by two different people.
Both Phantom and BlockDAG are committed to solving this problem based on voting. Their main idea is to prove that the graph of honest network composition must have certain characteristics, and can be ordered by the previous virtual voting method. But some malicious nodes create branches that want to destroy the complete order. They must not have these features. Therefore, we only need to discriminate the branches created by malicious nodes by some discriminating method.
However, the method of discrimination they have given is still problematic. Moreover, from a certain perspective, it is actually the second way of complication:
Idea 2: Identify a main chain
In fact, if we can determine a main chain, we can easily sequence all the blocks according to the main chain and a set of deterministic rules.
However, determining the main chain is not easy – because the DAG is long like this:
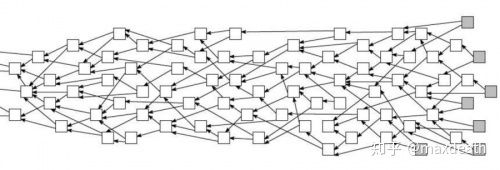
If the network is evenly distributed, then we have a high probability of getting a chain that is almost as long and growing at a constant rate. To confirm a main chain from it, it is almost as difficult as sequencing. Unless we can make some changes in the algorithm, it is easier for the algorithm to converge to a main chain. However, in such a DAG structure, the need to converge a main chain means that the miner needs to synchronize the main chain with priority, and the nodes that cannot be synchronized face the risk of wasted power. From this perspective, under this DAG structure, it is ok to pursue sequencing, but at the cost of lowering the output.
In this regard, Prism has made improvements in this structure – it structurally disassembles the DAG, then uses the traditional chain structure to generate the main chain, and then uses a DAG-like structure to make the block. From one perspective, it solves the DAG sequencing problem, but from another perspective, it is very similar to Bitcoin-NG. The only difference is that the micro block is no longer generated by the leader, but is generated by each node. Connected to the main chain in the form of DAG…
This creates a bridge between POW-DAG and scalable POW.
DAG duplicate transaction problem
Another problem that cannot be avoided in the DAG is the repeated transactions. Especially in the system where all miners share the trading pool, such as Bitcoin, if each node packs its own goods, it will inevitably appear that there are a large number of duplicate transactions in the block generated by the miners, which is completely Losing the meaning of using DAG to turn a chain into a tape – it is true that the block that reached consensus at each time interval changed from one piece to three pieces, from 100MB to 300MB, but if each of these 300MB transactions After being packaged three times, the actual output of the blockchain is equal to no change, but the data that needs to be stored and transmitted is three times more.
Then someone will ask: Will the repetition rate be so high?
But in fact, if you follow the current trading pool structure of Bitcoin, the repetition rate will almost be so high, because all the miners use the same rules to fish from the same pool – and in this case, the output is not only almost Ascension, but also a waste of storage space (because repeated transactions also need to be transmitted and stored to verify that the block is legal).
Therefore, when using DAG, the miner must adopt a different transaction selection mechanism at the same time – either, cancel the trading pool, assign each node nearby or randomly to a miner to be packaged; or, the miner needs to use a random method from the transaction. Chili fishing transaction.
But in fact, both can only cure the symptoms, not the cure –
The former will cause centralization. In other words, if the miner accepting your trade is offline or malicious, and even if it simply does not work, it will cause your transaction to be unconfirmed. The result is that you still need to broadcast your trade to more miners. This again caused repeated transactions.
The latter needs to be a "mineral union's assumption of honestly and randomly selecting transactions from the pool", but this is contrary to "rational miners should give priority to transactions with high transaction fees." If the former is strictly restrained, the interests of miners and traders will be harmed at the same time, because miners may not be able to obtain the best transaction fees, and traders cannot guarantee that their transactions will be packaged by miners faster by increasing transaction fees. Therefore, this move is more like a “planned economy” in the “trading market” to force the allocation of resources.
But in any case, the impact of repeated trades on DAG output is huge – even as a trader, you only send more of your trades to a mine job as an alternative, which will result in 50% of the trades being duplicated, ie the output is reduced by 50%. In other words, the network usage rate that has been greatly improved has been erased by 50%.
(Do you remember one person?)

As one of the earliest DAGs, IOTA naturally thought about this problem, so it canceled the block and miner settings, allowing traders to conduct POW and upload transactions themselves. However, this approach not only brings more serious security risks, but also introduces another setting that leads to repeated transactions. The tangle algorithm assumes that honest nodes will try to improve the speed at which their transactions are accepted, and can even continue on their own. The transaction is followed by an over-the-counter transaction to increase the chances that your trade will be quoted by others. This is in disguise to encourage traders to waste more bandwidth for the transaction.
However, one thing that IOTA has is that it is correct—if in a certain scenario, the miner itself is not taking a transaction from the pool but generating a transaction and packing it up, then there is no problem of repeated transactions.
Comparison between scalable POW and POW-DAG
In fact, although it looks completely different, we have described the two as two different routes in the previous introduction, but the output of the two can be compared from some angle.
For example, take Bitcoin-NG, Hybrid Consensus and Prism as examples.
All three have something similar to the main chain, and also support the full sequence of the message, then a block of the main chain for a round of calculations.
Bitcoin-NG: The leader is responsible for publishing the block and broadcasting the message to the entire network. It cannot fully utilize the bandwidth for message broadcast (because only the leader broadcasts), and at the same time, the output may be affected by malicious leaders.
Hybrid Consensus: The committee is responsible for publishing the block and broadcasting the message to the whole network, which can make better use of bandwidth (randomly selected committee members can broadcast the message to the whole network faster), but must consider the communication redundancy between the committees using the BFT algorithm. I.
Prism: All nodes make their own blocks and use DAG to reach a consensus, which can make the most use of bandwidth, but must consider the problem of duplicate messages.
We have compared the advantages and disadvantages of the former two in different network conditions, but it is more complicated compared with DAG, because the impact of repeated messages on the output is very great, but it depends greatly on the strategy adopted by the miners mentioned above.
In the next article, we will introduce some ideas for extending BFT.
references
Eyal, Ittay, et al. “Bitcoin-ng: A scalable blockchain protocol.” 13th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 16). 2016.
Pass, Rafael, and Elaine Shi. “Hybrid consensus: Efficient consensus in the permissionless model.” 31st International Symposium on Distributed Computing (DISC 2017). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2017.
Kogias, Eleftherios Kokoris, et al. “Enhancing bitcoin security and performance with strong consistency via collective signing.” 25th {USENIX} Security Symposium ({USENIX} Security 16). 2016.
Sompolinsky, Yonatan, and Aviv Zohar. "Secure high-rate transaction processing in bitcoin." International Conference on Financial Cryptography and Data Security. Springer, Berlin, Heidelberg, 2015.
Kiayias, Aggelos, et al. “Ouroboros: A provably secure proof-of-stake blockchain protocol.” Annual International Cryptology Conference. Springer, Cham, 2017.
Daan, Phil, Rafael Pass, and Elaine Shi. "Snow white: Robustly reconfigurable consensus and applications to provably secure proofs of stake." International Conference on Financial Cryptography and Data Security. Springer, St. Kitts, 2019.
Https://dfinity.org/
Gilad, Yossi, et al. “Algorand: Scaling byzantine agreements for cryptocurrencies.” Proceedings of the 26th Symposium on Operating Systems Principles. ACM, 2017.
Sompolinsky, Yonatan, and Aviv Zohar. "PHANTOM: A Scalable BlockDAG Protocol." IACR Cryptology ePrint Archive2018 (2018): 104.
Li, Chenxing, et al. “Scaling nakamoto consensus to thousands of transactions per second.” arXiv preprint arXiv:1805.03870 (2018).
Https://www.iota.org/
Sompolinsky, Yonatan, Yoad Lewenberg, and Aviv Zohar. "SPECTRE: A Fast and Scalable Cryptocurrency Protocol." IACR Cryptology ePrint Archive2016 (2016): 1159.
Bagaria, Vivek, et al. "Deconstructing the blockchain to approach physical limits." arXiv preprint arXiv:1810.08092(2018).
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- DeFi: Is it a new bottle of old wine, or is it a real future finance?
- PoW vs. PoS: Is the PoW consensus mechanism gradually abandoned?
- Analysis on the Supervision of Blockchain
- The conversion of the bulls and bears, the TOP20 mainstream encryption assets are reshuffled soon?
- Market Analysis: BTC oscillates in a narrow range, with the possibility of further adjustments
- Opinion: Why BTC transcends our time
- Increase the number of mainstream users! Foreign media reported that Samsung Pay is preparing to integrate encrypted assets