Learn more about IPFS (2/6): What is Interstellar Linked Data (IPLD)?
This article is a sequel to the "In-depth Understanding of IPFS" series (Part 2), which will help understand the basic concepts of IPFS. If you want to understand what IPFS is and how it works, you should check out the first article.
In the first part of this series, we briefly discussed IPLD. We see that IPLD handles "defining data" in IPFS. In this section, we will delve into IPLD and discuss it:
The meaning of IPLD : What is the philosophy behind it, why do we need it and why is it suitable for IPFS?
How does IPLD work : Explain how IPLD works and how it is coordinated with other components of IPFS?
- An Alternative Perspective of Bitcoin – The Future of Bitcoin
- Medical chain, can health be more secure?
- Billions of dollars flow into Staking activities, these security risks cannot be ignored
Actual use : The actual process is always interesting.
I hope you can learn a lot about IPFS from this series. let's start!
First, the importance of IPLD
IPLD is not only part of the IPFS project, but also a separate project. To understand its importance in the decentralized world, we must understand the concept of connected data: the semantic network.
What is associated data? Why do we need it ?
Semantic Web or Linked Data was created in a pioneering article by Sir Tim Berners Lee in Scientific American in 2001. A term. In the article, Berners Lee explains the vision of the World Wide Web, in which machines can process data independently of humans, enabling a range of new services that transform our daily lives. Data can be analyzed and manipulated by software agents. However, this paper has not been implemented for most web page scenarios that contain structured data, as more and more communities use international semantic web standards (called linked data). To achieve data sharing, semantic networks have become an increasingly important platform for data exchange and integration.
There are many examples of using semantic network technologies and linked data that share valuable information on the network in a flexible and scalable manner. Relevant technologies for semantic networks are widely used in life sciences to facilitate the discovery of new drugs by finding paths between multiple data sets that display drugs and side effects through genes associated with each data set. The relationship between. The New York Times published vocabulary of about 10,000 topics or titles developed over 150 years as link data and expanded its coverage to approximately 30,000 subject tags; they encouraged the development of the use of these vocabularies. Services and connect them to other online resources. By using link data, BBCs make content more easily searchable by search engines and easier to spread through social media links; use supplemental resources and add extra content from music or sports to spread the links. The original input target is exceeded to provide relevant information in an additional context. The home page of the US data.gov website says: "As the network of linked documents evolves to include linked data networks, we are working to maximize the potential of semantic network technologies to enable the disclosure of linked data." Social media sites are using link data to create networks that make their platforms as attractive as possible.
Indeed, we currently have some associated data being used, but we still have a long way to go to harness the true power of connected data.
Imagine if you can reference your latest commit in the git branch to a bitcoin transaction to add timestamps to your work. By linking git's commit, you can view the commit from the Blockchain Explorer. Or, if you can link an Ethereum contract to IPFS, you can modify it and track its changes each time the function executes.
All of this can be done using IPLD.
IPLD is a data model based on a content addressable network (as described in Part 1).
It allows us to treat all hashed data structures as a uniform subset, unifying all data and linked data models into instances of IPLD.
In other words, IPLD is a set of standards for creating decentralized data structures that are universally addressable and linkable. These structures allow us to process data just as urls and links handle HTML web pages.
Content addressing through hashing has become a widely used method of connecting data in distributed systems, from running your favorite cryptocurrency to code commits to network content on the blockchain. However, while all of these tools rely on some common principles, their specific underlying data structures are not interoperable (I can't currently link git commits to blockchains).
IPLD is a single name for all hash-inspired protocols. With IPLD, links can be cross-protocol, and data can be explored regardless of the underlying protocol.
Second, how does IPLD work ?
Before diving into IPLD, let's take a look at the properties of IPLD.
IPLD attributes
Since IPLD allows cross-protocol work, I think it is promising. The key is that IPLD provides libraries that allow the underlying data to interoperate across tools and across protocols by default.
Canonical data model
A separate description model that identifies any hash-based data structure and ensures that the same logical object is always mapped to the exact same sequence.
Protocol independent solution
IPLD integrates isolated systems (such as connecting Bitcoin, Ethereum and git) to make integration with existing protocols simple
Upgradeable
With the support of Multiformats (which we'll discuss in depth in Part 4), IPLD will be easy to upgrade and the content will increase based on your preferred protocol.
Cross-format operation
IPLD objects are represented in a variety of serializable formats (such as JSON, CBOR, YAML, XML, etc.) so that IPLD can be easily used with any framework.
Backward compatibility
Non-intrusive parsers make IPLD easier to integrate into existing work.
The namespace of all protocols
IPLD allows you to seamlessly explore data across protocols and bind hash-based data structures together through common naming.
Now let's take a closer look at IPLD.
Third, deep understanding of the IPLD specification
Be aware that IPLD is not a single specification, but a set of specifications.
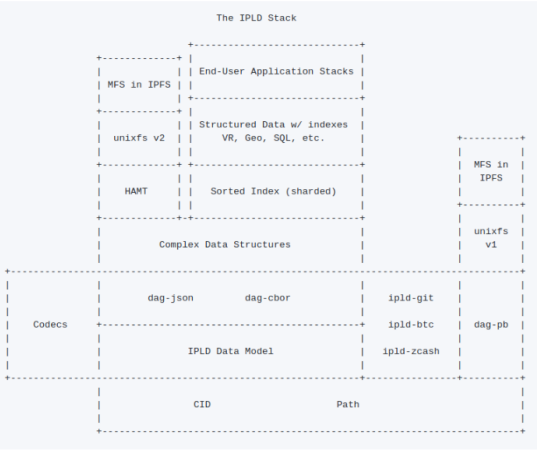
IPLD stack diagram
The purpose of this stack is to enable decentralized data structures, which in turn will enable more distributed applications.
Therefore, many of the specifications in this stack are interdependent.

IPLD dependency graph
These figures show the advanced project specifications for IPLD. Even if you don't fully understand it, it doesn't matter.
To learn more about IPLD, see Juan Benet's wonderful presentation .
Ok, there are enough theoretical things. Let's take a look at the most interesting part of this article.
Fourth, the actual operation of IPLD
In IPFS, IPLD helps to construct and link all data blocks/objects. So, as we saw in Part 1, IPLD is responsible for organizing all the data blocks to form the image of the kitten.
In this section, we'll create a publishing system similar to medium.com and use IPLD to link tags, articles, and authors. This will help you understand IPLD more intuitively, and you can find a complete tutorial on Github.
let's start!
Before creating the publishing system, we will look at the IPFS DAG API, which allows us to store data objects in IPFS in IPLD format. (You can store more exciting things in IPFS, such as the image of your favorite cat, but we only store some simple things for the time being.)
If you are not familiar with Merkle and DAGs, then come here . If you understand the meaning of these terms, then continue…
Create a folder called ipld-blogs. Run npm init and press Enter to see all the questions.
Now the installation depends on:
Npm install ipfs-http-client cids –save
After installing the module, your project structure will look like this:

Fifth, create an IPLD format node
You can create a new node by passing the data object to ipfs.dag, which returns the content identifier (CID) for the newly created node.
Ipfs.dag.put({name: 'vasa'})
A CID is the address of a block of data in an IPFS that is derived from its contents. Whenever someone puts the same {name: 'vasa'} data into IPFS, they will get the same CID as you get. If they type {name: 'vAsa'}, the CID will be different.
Paste this code into tut.js and run node .js
//Initiate ipfs and CID instance
Const ipfsClient = require('ipfs-http-client');
Const CID = require('cids');
//Connecting ipfs instance to infura node. You can also use your local node.
Const ipfs = new ipfsClient({ host: 'ipfs.infura.io', port: '5001', protocol: 'https' });
/*
Creating an IPLD format node:
Ipfs.dag.put(dagNode, [options], [callback])
For more information see:
https://github.com/ipfs/interface-js-ipfs-core/blob/master/SPEC/DAG.md#ipfsdagputdagnode-options-callback
*/
Ipfs.dag.put({name: "vasa"}, { format: 'dag-cbor', hashAlg: 'sha2-256' }, (err, cid)=>{
If(err){
Console.log("ERRn", err);
}
//featching multihash buffer from cid object.
Const multihash = cid.multihash;
//passing multihash buffer to CID object to convert multihash to a readable format
Const cids = new CID(1, 'dag-cbor', multihash);
//Printing out the cid in a readable format
Console.log(cids.toBaseEncodedString());
//zdpuAujL3noEMamveLPQWJPY6CYZHhHoskYQaZBvRbAfVwR8S
});
You will get a CID "zdpuaujl3 noemamvelpqwjpy6cyzhhhoskyqazbvrbafvwr8". At this point, we have successfully created an IPLD format node.
Connect IPLD objects
One of the important features of directed acyclic graphs (DAGs) is the ability to link them together.
The way to represent a link in the ipfs DAG store is to use the CID of the other node.
For example, if we want a node to have a link named "foo" pointing to another CID instance that was previously saved as barCid, it might look like this:
{
Foo: barCid
}
When we assign a name to a field and use its value as a link to the CID, we call it a named link.
The following code shows how to create a named link.
//Initiate ipfs and CID instance
Const ipfsClient = require('ipfs-http-client');
Const CID = require('cids');
//Connecting ipfs instance to infura node. You can also use your local node.
Const ipfs = new ipfsClient({ host: 'ipfs.infura.io', port: '5001', protocol: 'https' });
/*
Creating an IPLD format node:
Ipfs.dag.put(dagNode, [options], [callback])
For more information see:
https://github.com/ipfs/interface-js-ipfs-core/blob/master/SPEC/DAG.md#ipfsdagputdagnode-options-callback
*/
Async function linkNodes(){
Let vasa = await ipfs.dag.put({name: 'vasa'});
//Linking secondNode to vasa using named link.
Let secondNode = await ipfs.dag.put({linkToVasa: vasa});
}
linkNodes()
Use nested links to read nested data
You can use the path to read data from deep nested objects and query.
Ipfs.dag.get allows queries using IPFS paths. These queries will return an object containing the value of the query and any unresolved remaining paths.
The cool thing about this API is that it can also traverse links. Below is an example of how to use a link to read nested data.
//Initiate ipfs and CID instance
Const ipfsClient = require('ipfs-http-client');
Const CID = require('cids');
//Connecting ipfs instance to infura node. You can also use your local node.
Const ipfs = new ipfsClient({ host: 'ipfs.infura.io', port: '5001', protocol: 'https' });
Function errOrLog(err, result) {
If (err) {
Console.error('error: ' + err)
} else {
Console.log(result)
}
}
Async function createAndFeatchNodes(){
Let vasa = await ipfs.dag.put({name: 'vasa'});
//Linking secondNode to vasa using named link.
Let secondNode = await ipfs.dag.put({
Publication: {
Authors: {
authorName: vasa
}
}
});
//featching multihash buffer from cid object.
Const multihash = secondNode.multihash;
//passing multihash buffer to CID object to convert multihash to a readable format
Const cids = new CID(1, 'dag-cbor', multihash);
//Featching the value using links
Ipfs.dag.get(cids.toBaseEncodedString()+'/publication/authors/authorName/name', errOrLog);
/* prints { value: 'vasa', remainderPath: '' } */
}
createAndFeatchNodes();
You can also use this cool IPLD resource manager to explore your IPLD nodes. For example, if I want to see CID zdpuAujL3noEMamveLPQWJPY6CYZHhHoskYQaZBvRbAfVwR8S
I will open this link: https : //explore.ipld.io/#/explore/zdpuAujL3noEMamveLPQWJPY6CYZHhHoskYQaZBvRbAfVwR8S
Now that we have studied the IPFS DAG API, we are going to use IPLD to create our publishing system.
Create a publishing system
We will create a simple blog application. This blog application can:
· Add a new Author IPLD object. The author will have two fields: name and profile (the tag line of your profile).
· Create a new Post IPLD object. The post will contain 4 fields: author, content, tag, and release date and time.
· Use the post CID to read the post.
The following is the code implementation for the above goals:
/*
PUBLICATION SYSTEM
Adding new Author
An author will have
-> name
-> profile
Creating A Blog
A Blog will have a:
-> author
-> content
-> tags
-> timeOfPublish
List all Blogs for an author
Read a Blog
*/
//Initiate ipfs and CID instance
Const ipfsClient = require('ipfs-http-client');
Const CID = require('cids');
//Connecting ipfs instance to infura node. You can also use your local node.
Const ipfs = new ipfsClient({ host: 'ipfs.infura.io', port: '5001', protocol: 'https' });
//Create an Author
Async function addNewAuthor(name) {
//creating blog object
Var newAuthor = await ipfs.dag.put({
Name: name,
Profile: "Entrepreneur | Co-founder/Developer @TowardsBlockChain, an MIT CIC incubated startup | Speaker | https://vaibhavsaini.com"
});
//Fetching multihash buffer from cid object.
Const multihash = newAuthor.multihash;
//passing multihash buffer to CID object to convert multihash to a readable format
Const cids = new CID(1, 'dag-cbor', multihash);
Console.log("Added new Author "+name+": "+cids.toBaseEncodedString());
Return cids.toBaseEncodedString();
}
//Creating a Blog
Async function createBlog(author, content, tags) {
//creating blog object
Var post = await ipfs.dag.put({
Author: author,
Content: content,
Tags: tags,
timeOfPublish: Date()
});
//Fetching multihash buffer from cid object.
Const multihash = post.multihash;
//passing multihash buffer to CID object to convert multihash to a readable format
Const cids = new CID(1, 'dag-cbor', multihash);
Console.log("Published a new Post by "+author+": "+cids.toBaseEncodedString());
Return cids.toBaseEncodedString();
}
//Read a blog
Async function readBlog(postCID){
Ipfs.dag.get(postCID,(err, result)=>{
If (err) {
Console.error('Error while reading post: ' + err)
} else {
Console.log("Post Detailsn", result);
Return result;
}
});
}
Function startPublication(){
addNewAuthor("vasa").then((newAuthor)=>{
createBlog(newAuthor,"my first post", ["ipfs","ipld","vasa","towardsblockchain"]).then((postCID)=>{
readBlog(postCID);
})
});
}
startPublication();
When you run this code, it will first create an author with addNewAuthor, which will return the author's CID. This CID is then passed to the createBlog function, which then returns the postCID. The readBlog function will use this postCID to get the details of the post.
You can also use IPLD to create more complex applications…
Ok, this part is here. If you have any questions, you can ask in the comments.
I hope that you can learn a lot from this article. In the next article, we will delve into the distributed Web naming system IPNS. Stay tuned…
Thanks to protoschool for an excellent interpretation of DAGs.
Thank you for reading.
Original author: vasa
Original link: https://hackernoon.com/understanding-ipfs-in-depth-1-5-a-beginner-to-advanced-guide-e937675a8c8a
Translation: StarCraft Continental Overseas Team
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- The Samsung Galaxy S10 mobile phone is at risk of being hacked, and the security of the encrypted wallet is questioned.
- FCoin's self-help campaign
- On the fall of a 720 million water Dapp in a single day
- Bitland's 50T new mining machine is coming, I heard that it is a lot cheaper than S15.
- After the bitcoin skyrocketed, the market began to oscillate, and the trader’s heart began to sway.
- The Law of Simplicity: McKinsey's Three Advices for Blockchain Innovators
- The evolutionary philosophy of money: every time the evolution of money requires external pressure to advance