Exploring Cross-Chain Communication from the Perspective of Rollup
Cross-chain communication is becoming more important in the blockchain industry. Rollup, a popular layer-2 scaling solution, can facilitate cross-chain communication. This article explores the possibilities of using Rollup for cross-chain communication. Rollup is a layer-2 scaling solution that enables off-chain computation and storage of transactions, reducing the number of transactions that need to be processed on the main chain. By aggregating multiple transactions into a single transaction, Rollup can significantly increase the scalability of the blockchain. Rollup can facilitate cross-chain communication by enabling the transfer of assets and information between different chains. Users can deposit assets from one chain into a Rollup contract and withdraw them on another chain. Rollup can store data off-chain and provide proof of the data on-chain, enabling information transfer between different chains. In conclusion, Rollup has great potential in facilitating cross-chain communication and is expected to play a critical role in enabling it as the blockchain industry evolves.Author: Lisa A., Taiko Labs; Translator: Blockingxiaozou
This article explores different L2 cross-chain message passing methods from the perspective of rollup, focusing on trustless cross-chain communication. We will briefly look at direct state reading, light client, and storage proof methods. We will also delve into proof aggregation mechanisms, trusted third-party cross-chain message transmission, and core ZK cross-chain solutions. Finally, we will see how different L2s achieve cross-chain message passing today.
1. Introduction to Cross-Chain Message Passing
For cross-chain communication, all parties (L2, L3, etc.) must be able to directly access the latest Ethereum state root.
- What is the allure of Sound.xyz, the leader of the music NFT track, with a16z as the lead investor?
- A Quick Guide to Understanding the EU’s New Concept of Web4
- In-depth analysis of MakerDAO’s RWA layout: How does the DeFi protocol integrate real-world assets?
All deposit layers have a “built-in” cross-chain mechanism that can be used to access the L1 state root, which will be passed as a deposit message to L2.
1.1 Two Types of State Root Access
Type 1: Direct State Root Reading — can be completed through opcodes or precompiles. However, it has not yet been implemented, so no proof is required.
Brecht Devos describes a possible method for directly reading the state in a research article: “… we can publish a precompile that can directly call the smart contract on the target chain. This precompile inserts and executes the smart contract code of another chain directly into the source chain. This ensures that smart contracts can always access the latest available state in an efficient and verifiable way.”
There is also a related description in Optimism’s RFP “Remote Static Call Concept Proof”.
Type 2: Proof Generation — i.e., proving statements about one blockchain on another blockchain.
“Proof-based cross-chain message passing” has two methods:
· Trustless cross-chain communication – i.e., without a trusted third party (e.g., using light clients or storage proofs). Trustless methods can be used for both third-party proof generation and cross-chain communication participants to generate their own proofs.
· Sharing proofs between different rollups to ensure cross-chain operations. This method is not discussed in detail in this article, as it is currently in the research and exploration stage and is not considered a widely applicable solution.
1.2 “Cross-Chain Message Delivery with Proof” Method
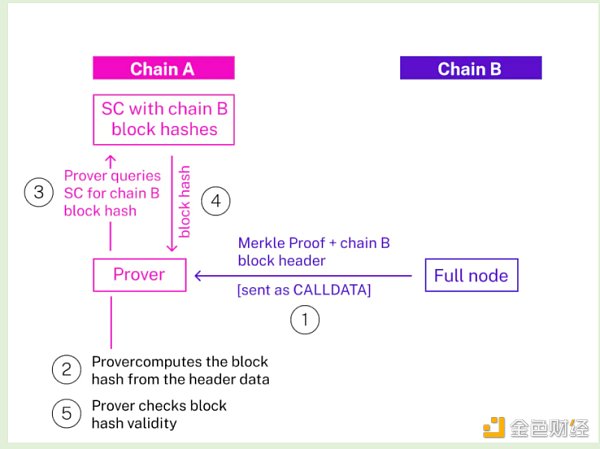
1.2.1 Cross-Chain Message Delivery for Light Clients
Proof of data on chain B
· Obtain Merkle proof data from the chain B full node (if proof of certain historical states is required, an archive node is used);
· Send the block header and proof data corresponding to the chain B block that contains the state we want to verify as calldata to the verifier contract on chain A;
· The verifier contract calculates the block hash value based on the block header data, queries the light client smart contract on chain A (which tracks the block hash value of chain B), and checks if the hash value is valid;
· The proof data is verified based on the bytes32 state root in the block header.
1.2.2 Storage Proof
There are two “workflow” options for storage proof:
· Generate storage proof → use on chain;
· Generate storage proof → generate zk proof → use on chain.
It is also possible for an entity to collect multiple proofs and package them into a single proof (including storage proofs and zk proofs). This is an optional optimization step, and is not discussed here.
Let’s take a look at the three main stages of the “workflow” for storage proof: generate storage proof, generate zk proof, and use on chain.
(1) Generate Storage Proof
· Storage proof allows us to use confidential commitments to prove that certain information exists on the blockchain and is genuine;
· Since the appearance of Merkle trees in 1979, storage proofs have been part of the encryption field. However, vanilla storage proofs are usually quite large. The modern innovation is to combine storage proofs with provable computation to create concise proofs that can be verified on the chain.
To generate a storage proof, a specific data block and its associated Merkle or Verkle path in the Merkle tree must be provided. The path consists of sibling hash values required to rebuild the root hash value using the same hash algorithm.
To verify the storage proof, the receiver can use the provided data and Merkle or Verkle path to recalculate the root hash value. If the recalculated root hash value matches the known root hash value, the receiver can be sure that the data is genuine and is part of the submitted data set.
(2) Generate ZKP (Zero-Knowledge Proof)
However, the Ethereum-type storage proof is about 4kb – it is quite large for publishing the entire storage proof to the target chain, because proof verification will be very expensive. Therefore, it is reasonable to use ZKP (such as ZK-SNARK) for compression, which can make the proof smaller and the verification cost lower.
(3) Unroll ZKP
After obtaining the ZKP, users on the target chain can unroll the proof they obtained (for example, access to historical state through block headers or block hash values).
Unroll can be done in the following ways:
On-chain accumulation: The entire process of reconstructing the block header from the proof is performed directly on the blockchain. Disadvantages: high gas fees, consumes computing resources; advantages: no additional proof time, low latency, because proof does not need to be generated outside the blockchain.
On-chain compression: Remove redundant or unnecessary information from the data, or use data structures optimized for space efficiency. The compressed data is sent to the blockchain and can be decompressed when needed. Disadvantages: compressing and decompressing data may mean additional computation, but this delay may be negligible. The compression algorithm used may have a negative impact on the security of the data; advantages: reduce data costs.
Off-chain storage: Store data off-chain and put specific data blocks on the chain as needed. This is related to solutions that need to store a large amount of data for some reason (such as Ethereum archive nodes starting from the genesis block). Disadvantages: same as on-chain compression; advantages: further reduce data costs.
1.2.3 Trusted third party
A complete cross-chain solution should also involve a cross-message transmission solution with a trusted third party (such as oracle, centralized bridge, etc.).
1.2.4 “Universal” proof system
In the case of using a shared proof aggregation platform mechanism, the message transmission speed can be accelerated by receiving the block hash value settled in the aggregation platform, and the settlement here will also handle the message transmission (but what if the proof aggregation platform has problems?).
1. 2.5 ZK. Some unclear issues regarding cross-chain message passing. Is cross-chain message passing feasible without a trusted third party (which can be a single entity or multiple entities)? What is an effective mechanism for cross-chain message passing? Generally speaking, for Ethereum L2 (which can directly access L1 block hash values) and Ethereum itself, if a chain can run light clients on another chain, it can verify block headers from that external chain, which is sufficient for trustless cross-chain message passing.
Is the ZK circuit used for cross-chain proof generation of an appropriate scale? In some cases, especially when the consensus layer (which needs to verify cross-chain operations) is very large, the circuit used for ZK cross-chain message passing may be several orders of magnitude larger than rollup and on-chain storage, and the computational overhead is also large. It is speculated that this problem can be overcome by a more centralized approach.
2. Examples of cross-chain message passing solutions:
· Succinct Labs uses light clients to verify consensus from the source chain to the destination chain. The specific idea is to have a light client protocol to ensure that nodes can synchronize block headers of the final blockchain state. ZKP is used to generate consensus proofs.
· Lagrange Labs builds non-interactive cross-chain state proofs. The Lagrange proof network is responsible for creating the state root. Each Lagrange node contains a portion of a shard private key to prove the state of a specific chain. Each state root is a Verkle root of a threshold signature, which can be used to prove the state of a specific chain at a specific time. The state root is completely generic and can be used in state proofs to prove the current state of any contract or wallet in the chain.
· Herodotus uses ZKP storage proofs to provide smart contracts with synchronized access to on-chain data from other Ethereum layers. For verification, it uses native L1<>L2 message passing to synchronize block hash values between Ethereum rollups.
· =nil; Foundation (Mina, L1) allows smart contracts on Ethereum to verify the validity of Mina state. It generates a specially purposed state proof, which is low cost to verify on Ethereum (the cost of performing local Mina proof on Ethereum is high). Assuming (at some point in the future) apps can directly use Mina’s proof generation tools to verify the validity of cross-chain transactions. =nil; Foundation also has a Proof Market, where users/projects can primarily buy/sell SNARK proofs, which allow trustless data access.
· Axiom: If Axiom has generated a ZKP for the ledger up to the present time, it does not need to generate a ZKP for a specific data block. It can pass this ZKP to the chain (as a Relayer), and even provide access to that ZKP.
3. Cross-chain Message Transmission in L2
Disclaimer: For most L2s, cross-chain message transmission is still developing. All analysis below is based on open source information. That is to say, the solutions mentioned in the article may be in the exploration and testing stage, and rollup may ultimately adopt other methods.
(1) Taiko
· Taiko stores the block hash value of each chain. For each pair of chains, it deploys two smart contracts to store each other’s hash values. In the example of L2←→L1, the hash value of the peripheral block on L1 is stored in the TaikoL2 contract each time an L2 block is created on Taiko. The same operation is performed in the case of L1←→L2.
· The latest known Merkle root on the target chain can be obtained by calling getCrossChainBlockHash(0) on the TaikoL1/TaikoL2 contract, and the value/message to be verified can be obtained. By using the standard RPC call eth_getProof request on the “source chain”, the sibling hash value of the latest known Merkle root can be obtained.
· Then, they only need to send them to verify them based on the latest known block hash value stored in the “target chain” list. The verifier will obtain a value (a leaf on the Merkle tree) and sibling hash values to recalculate the Merkle root and check if it matches the root stored in the block hash value list on the target chain.
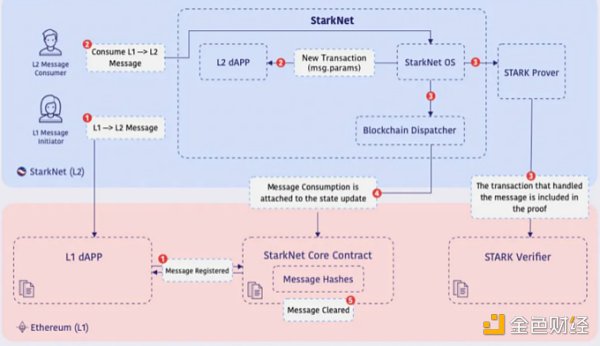
(2) Starknet
Starknet uses storage proof for trustless cross-chain message transmission.
L2→L1 Message Transmission Protocol
· During the execution of a Starknet transaction, the contract on Starknet sends an L2→L1 message.
· Then, the message parameters (including the recipient contract on L1 and the relevant data) are attached to the relevant state update (main storage tree).
· L2 messages are stored on the L1 of the smart contract.
· An event is emitted on L1 (storing the message parameters).
· The recipient address on L1 can access and use the message by re-providing the message parameters as part of the L1 transaction.
· Cross-chain messages are stored in the main tree.
L2 → L1
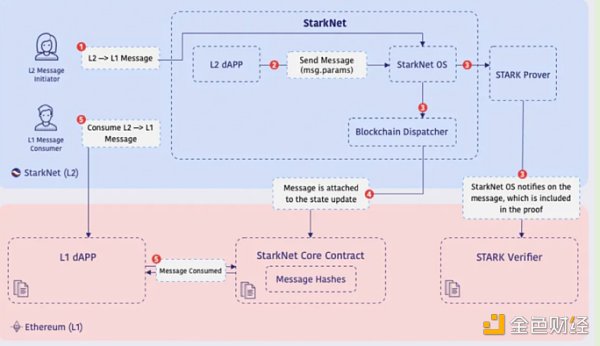
L1 → L2
(3) Optimism
· The communication between L1 and L2 is implemented by two special smart contracts called “messengers”.
· For transactions from Optimism (L2) to Ethereum (L1), it is necessary to provide a Merkle proof about the message on L1 after the state root is written. After the proof transaction becomes part of the L1 chain, the error challenge period begins. After this waiting period, any user can “finalize” the transaction by triggering a second transaction on Ethereum, which sends the message to the target L1 contract.
· Cross-chain messages are stored in the main tree.
(4) Arbitrum
· Retryable tickets are the specification method used by Arbitrum to create L1-to-L2 message passing, which initializes L1 transactions for messages to be executed on L2. A Retryable can be submitted on L1 by paying a fixed fee (depending only on its calldata size). The main state tree is used for cross-chain communication with custom data formats in smart contracts. Submitting a retryable ticket on L1 is separable/asynchronous from the execution on L2. Retryables provide atomicity between cross-chain operations. If the L1 transaction request submission is successful (i.e., no rollback), then there is a strong guarantee for the execution of Retryable on L2, which will eventually succeed.
· Arbitrum has two trunks: the Nitro chain is maintained in the format of Ethereum’s state tree and is a Merkle tree. The Assertion Tree stores the state of the Arbitrum chain confirmed by “assertion” on Ethereum. The rules for advancing the Arbitrum chain are deterministic. This means that for a given state of a chain and some new input values, there is only one valid output. Therefore, if the proof tree contains multiple leaves, at most one leaf can represent a valid chain state.
· The Outbox system of Arbitrum allows arbitrary L2-to-L1 contract calls, i.e., messages initiated from L2 and eventually executed on L1. L2-to-L1 messages (also known as “outgoing messages”) have many similarities with Arbitrum’s L1-to-L2 messages (Retryable), although there are some obvious differences. A part of the L2 state of the Arbitrum chain, which is the Merkle root of all L2-to-L1 messages in the chain history, is included in the proof of each RBlock. After the proof of the RBlock is confirmed (usually about a week after the proof), the Merkle root is published to L1 in the Outbox contract. Then, the Outbox contract allows users to execute their messages.
(5) Polygon zkEVM
· The Bridge SC of this zkEVM uses a special Merkle tree called Exit Tree for each network participating in communication or asset trading.
· It uses a Merkle root (in a separate state tree), and a bridging architecture diagram can be found on Github.
· The deployment of the zkEVM Bridge SC underwent several changes based on the Ethereum 2.0 deposit contract. For example, it uses a specially designed append-only Merkle tree, but adopts the same logic as the Ethereum 2.0 deposit contract. Other differences relate to the basic hash value and leaf nodes.
· The main feature of the Polygon zkEVM Bridge smart contract is the use of the Exit Tree and the Global Exit Tree, where the root of the Global Exit Tree is the main source of truth status. Therefore, L1 and L2 have two different Global Exit Root Managers, and the Bridge SC has a separate logic.
(6) Scroll
· The bridge contract deployed on Ethereum and Scroll allows users to pass arbitrary messages between L1 and L2. On top of this message passing protocol, we also built a trustless bridging protocol to allow users to bridge ERC-20 assets between L1 and L2. To send a message or funds from Ethereum to Scroll, users call the sendMessage transaction on the Bridge contract. The relayer indexes this transaction on L1 and sends it to the Sorter to be included in the L2 block. The process of sending messages back from Scroll to Ethereum on the L2 bridge contract is similar.
· Cross-chain messages are stored in a regular message queue. Sorters ingest cross-chain messages from this queue and add them to the chain as regular transactions.
(7) zksync Era
Disclaimer: This section only concerns zksync Era, which may differ from cross-chain message passing on the ZK Stack, a modular framework for building sovereign ZK rollups.
· Each transaction package has a separate L2->L1 message.
· It is impossible to send transactions directly from L2 to L1. However, you can send messages of arbitrary length from zkSync Era to Ethereum and then use an L1 smart contract to process the received messages on Ethereum. zkSync Era has a request proof function that returns a boolean parameter indicating whether the message was successfully sent to L1. Retrieve the Merkel proof containing the message by observing Ethereum or using the zks_getL2ToL1LogProof method of the zksync-web3 API.
· For L1→L2, zkSync Era smart contract allows the sender to request transactions on Ethereum L1 and pass the data to zkSync Era L2.
· Bridge contract: https://github.com/matter-labs/era-contracts/blob/main/ethereum/contracts/bridge/L1ERC20Bridge.sol
4 , Conclusion
Cross-chain communication is essential for blockchain applications that require large-scale adoption, such as cross-chain social recovery wallets described in Vitalik Buterin’s article. Most of the current cross-chain solutions are designed for L1←→L2 to cover withdrawal functions. These solutions can be extended to cover more blockchains. However, more advanced cross-chain communication solutions can be implemented, such as “direct state reading” without the need for proof or “storage proof” without trust. There is still room for improvement in cross-chain communication for most L2s.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- After launching an upgraded application, OKX Hong Kong has recorded over 10,000 new user registrations within a month.
- A Guide to Flashbots Protect Upgrade: How to Speed Up Private Transactions
- Layer1 Protocol Galactica Network Introduction: Can it fundamentally solve the witch attack problem?
- Ribbon Finance Governance Proposal: Consolidating Ribbon Finance and Aevo
- Messari: Solana’s Q2 2023 Performance
- In-depth analysis of MakerDAO RWA layout, how DeFi protocols integrate real world assets
- AltLayer: How to perform decentralized Rollup state verification using Beacon Layer?