DID Identity System General Knowledge (Part 1)
DID Identity System Basics (Part 1)Introduction
The emergence of Web3 based on blockchain technology has gained significant momentum, largely driven by people’s expectations of its ability to counteract the privileges of commercial organizations and involuntary censorship. It aims to safeguard the rights of each participant by replacing human governance with code. However, the current situation shows that the various solutions offered by the industry, such as allowing users to freely register wallets for interaction, not only lead to frequent occurrences of witch attacks and phishing attacks without accountability but also erode the confidence of the Web3 community, compromising the privacy and asset security of Web3 users. It also prevents Web3 users with on-chain reputation but without assets from enjoying high-quality financial services (similar to offline credit lending models).
The exploitative behavior of the “strong exploiting the weak” in Web2 and the traditional society’s “bad money drives out good money” is replicated in Web3. Even the data sovereignty (SSI) advocated and believed by Web3 (which is also one of its attractive features to users) is repeatedly hindered on the path to implementation. This is because users’ privacy data is either stored on centralized servers of decentralized projects or publicly displayed on the blockchain in its entirety, without actual protection of security and privacy. It even brings greater economic losses compared to Web2, and once it suffers, it is almost irreversible. Moreover, due to the lack of appropriate regulatory support, the identity of malicious attackers is difficult to identify and hold accountable.
In this context, Web3 realizes that visualizing the reputation of identity subjects, contract recommendations based on identity, and introducing appropriate regulations are indispensable for its sustainable development. Based on this fundamental awareness, the concept of decentralized identity, consisting of “Decentralized Identifiers (DIDs) + Verifiable Credentials (VC),” is gradually becoming clearer, providing a solution for the construction of an identity system in the Web3 society.
- Rollup as a Service Economic Mechanism Analysis How can service providers increase profits?
- Interpreting Unibot related data
- Summary of the 9 key points of Ethcc consortium chains, beware of the assumption of honest majority, integration of Cosmos and Ethereum ecosystems…
In brief, the development of identity systems has evolved from a centralized identity managed and controlled by a single authoritative institution, to a federated identity where user identity data has a certain degree of portability and enables cross-platform logins, such as the cross-platform login of WeChat and Google accounts. It then progressed to a preliminary decentralized identity that requires authorization and permission for identity data sharing, such as OpenID. Finally, it advanced to a self-sovereign identity (SSI) that truly allows individuals to fully own and control their data – typically referring to a decentralized identity system with privacy and security based on DID+VC construction. Decentralization is gradually replacing centralization, and decentralization no longer involves central data storage and collection.

Status of Identity Privacy Data
Identity and its related information are often used to prove “who I am” and “whether I meet the specific requirements to enjoy a certain service.” For example, educational requirements when looking for a job, asset certification when purchasing a house or applying for a bank loan, and whether we meet the conditions to become a VIP customer of a certain entity or virtual service provider, etc. Many scenarios require the use of identity information.
In real life, people’s identity information is recorded in the government system and verified in various life scenarios by presenting corresponding documents and certificates. In the Internet world, our identity is represented by account passwords, and the behavioral data based on this is recorded by the data storage system of the corresponding service provider.
They have the following similarities:
-
User data is saved by third-party organizations (they cannot control identity-related information themselves);
-
Users cannot freely use their own data (thus unable to determine who has the right to access their identity information and unable to control the authorization scope of visitors).
Because when users need to connect to social, gaming, financial, shopping, and other activities around the world through the Internet, these identity information needs to be uploaded to a platform without reservation, and the online game identity data and social identity data generated by users are also stored in the servers of giants. In other words, users only have the right to view but not the right to delete, add, or trade their data according to their own wishes. The unrestricted exposure of these data to institutions poses considerable privacy and security risks. After all, the phenomenon of institutions using privileges to steal user data seems to be common in Web2.
At the same time, the relatively independent data systems between organizations force user data to be fragmented and stored in inaccessible systems, making it difficult for users to view, call, and parse their data in its entirety. One of the prerequisites for implementing SSI is that users can control their own privacy data, that is, have data sovereignty – the right to custody and use of data. DID achieves this.

DID – Returning Data Sovereignty to Users
What is DID
In simple terms, a decentralized identifier (DID) is a string-form URI with global uniqueness, high availability, resolvability, and encryption verifiability. It is beneficial for any application that benefits from self-managed, encryption-verifiable identifiers, such as personal identity, organizational identity, on-chain activity history, IoT scenarios, etc. It can also be used to identify other entities, such as products or non-existent things like ideas or concepts.
Many blockchain platforms like Ethereum and Polygon are paying attention to DID, but they are currently in the experimental stage and no one has provided a systematic solution. The most commonly used DID standards come from W3C (World Wide Web Consortium), the world’s largest web specification development organization, and DIF (Decentralized Identity Foundation), with W3C standards being more widely used.
DID and VC are closely related. W3C VC’s commercial deployment extensively uses DID to identify individuals, organizations, and things, and provides a certain degree of security and privacy protection. Without permission, no other party can access, use, or disclose the identity data of the DID subject.
Users have full control over their DID, generated according to a specific algorithm, and not fully granted by a single institution. A DID can be resolved into a DID document stored on the blockchain, which includes information such as authentication keys, agreement keys, delegation keys, assertion keys, and server endpoint links for interacting with the DID subject. These keys can be understood in a popular sense as signatures we use for different purposes in life, and the signed documents (purposes) may be confidentiality agreements, delegation letters, or authorization letters allowing someone to use your personal information, etc.
It is precisely because of this public key infrastructure that the DID+VC identity system allows users to better protect their data and choose whether to share and how to share data, as only the owner of the private key has full authorization of the DID. This is similar to how assets are controlled by private keys in blockchain.
On a side note, this can also lead to the following problems:
-
It is very difficult to recover lost private keys;
-
Once your private key is stolen, malicious activities such as impersonation can lead to improper behavior on your behalf.
Therefore, all users have the responsibility to securely backup their private keys and mnemonic phrases.

VC – Trustworthy Online Identity Information
VC is a more in-depth element of the identity system than SBT.
In May 2022, Vitalik Buterin, co-founder of Ethereum, Glen Weyl, a researcher at the Microsoft Chief Technology Officer’s Office, and Puja Ahluwalia Ohlhaver, a strategist at Flashbots, jointly released “Decentralized Society: Finding Web3’s Soul,” which sparked discussions about SBT (SoulBound Token). As a result, the concept of decentralized identity has gained more attention.
SBT can to some extent replace VC in building social relationships in Web3. Protocols such as EIP-4973, EIP-5114, ERC721S, and EIP-3525 represent the imagination of SBT application forms. However, the inherent limitations of SBT prevent it from forming a complete decentralized identity system:
-
Firstly, SBT is still fundamentally a token.
A token points to a wallet address, rather than an identity identifier that can represent an identity. Anyone who can obtain a wallet address can view the SBTs owned by the wallet owner, leaving no privacy. More importantly, we do not want social contract entities to be wallets rather than identities, as transactions are only part of social activities.
-
Secondly, SBT relies on the existence of a blockchain.
Although it can prove identity in multi-chain compatible environments such as EVM, it is powerless in cross-ecosystem, cross-platform, and even off-chain scenarios.
-
Lastly, SBT also has limitations in terms of presentation and application scenarios.
Similar to NFT, existing SBTs only have two presentation forms: fully displayed and fully hidden, and do not have comprehensive privacy protection for data. Although there are efforts to aggregate SBTs in the industry, the information presentation forms of different projects are not unified, so they can only be displayed on whiteboards, making them difficult to read and not user-friendly.
Even now, it is possible to selectively disclose SBTs – that is, to partially disclose information in SBTs according to needs. However, it should be noted that this partial information is still disclosed in plain text without modification or concealment. This raises a problem: when users need to prove their identity, they must partially expose the privacy data in SBTs. After multiple exposures, these privacy data can still be collected, organized, and analyzed to form a complete user profile, thus threatening privacy and security. This is similar to the Web2 profile. Just think about when you open Taobao and see push advertisements that are similar to the furniture store category you just browsed, or Taobao always pushes products of corresponding styles, price ranges, and preferences based on your consumption habits. It’s like being trapped in an information cocoon. Not everyone always likes to be confined in an information cocoon; it can limit your information exploration and, in more serious cases, restrict your cognition.
So as we can see, the SBT is short-lived, and the scenarios where it can be widely and deeply used are very limited. We have questioned the idea that “SBT can meet the complex identity data interaction needs of the future Web3 society.”
On the other hand, the DID+VC solution effectively resolves the three limitations of SBT mentioned above, ensuring that the ultimate control of publishing, holding, and controlling DID and VC remains in the hands of the users through cryptographic and other technical means. And through a series of technologies and protocols, it guarantees that:
-
The identity system can be used across chains, platforms, and even off-chain;
-
The identity information display scheme is unified, and there is no need to use different display schemes according to different scenarios;
-
Even customized products can be developed on top of the DID protocol.
(Note: As for NFT, the author believes that it cannot be compared with VC, because NFT represents ownership, and this ownership can be changed, transferred, and traced. VC carries information related to identity, which is unique to you and cannot be transferred.)
【 What is VC 】
VC is a descriptive statement issued by a DID (such as a trusted institution, a DAO organization, a government system, a business institution) about another DID (such as a user, a partner), endorsing certain attributes. It is generated and verified based on cryptography, used to prove that the owner has certain attributes and that these attributes are true (such as identity, ability, qualification) [1]. These authentication results can also be recorded in other VCs stored on platforms like Arweave and IPFS. All relevant information is open, verifiable, searchable, and permanently traceable, and anyone can independently verify it to ensure the authenticity and trustworthiness of the credential content [2]. These VCs can also be deployed on various major public chains and interact with other ecosystem applications. Only the DID subject who has ownership of the VC can control who can access and how they can access their VCs.
Note that in the above paragraph, we mentioned two types of VCs. One is used to store user’s private data [1], which we call personal VC here; the other is used to store the verification of personal VCs [2], which we call result VC here. There is an issue here: currently, most of the verifiable credentials are stored in centralized databases or blockchains that do not have the ability to provide privacy protection. This is not a problem for result VCs [2], but it is unacceptable for personal VCs [1].
So how can we ensure the storage security and privacy of VCs that contain personal private data? This involves the storage methods of VCs:
【 Storage Methods of VCs 】
There are currently three main methods:
-
Stored and backed up locally by the user.
This is similar to recording private keys on a notebook or using programs that are not connected to the Internet. However, similarly, once lost, it is almost impossible to retrieve. Users need to bear more responsibility when enjoying more sovereignty.
-
Encrypted and stored in user-controlled cloud storage.
This method is different from Web2, where data is stored directly on centralized servers owned by internet giants. Access, use, and deletion permissions for encrypted VCs can only be operated by the owner who holds the corresponding DID private key. Of course, users still need to keep their DID private key or mnemonic phrase safe.
3. Store publicly available VC information on decentralized storage platforms.
This allows for traceability and verification of information, and the ownership of this information still belongs to the VC owner.
It is emphasized here that regardless of the method, users should make backups of VCs and private keys.
【 Presentation Method of VC 】
Let’s delve deeper. More attentive readers may realize that even if we achieve privacy and security in storage, if we cannot present VCs in a way that “reveals no privacy information but lets the other party know that I meet their conditions,” then the information we disclose is still fully exposed on the network, right? Doesn’t it bring us back to the previous discussion of SBT/NFT information being traced, collected, and forming a complete user profile, disrupting our daily lives and economic activities?
This kind of data presentation without privacy protection is not what SSI pursues!
This is also the entry point for the currently hotly debated ZKP (Zero-Knowledge Proof) technology.
There are various technologies for achieving privacy, such as Secure Multi-Party Computation, Homomorphic Encryption, Zero-Knowledge Proof, etc. However,
-
Secure Multi-Party Computation requires more than n participating parties and has significant usage limitations at the individual user level, but it is the cryptographic foundation for implementing many applications such as electronic voting, threshold signatures, and online auctions.
-
Homomorphic Encryption often requires higher computational time or storage costs and is still far behind in performance and strength compared to traditional encryption algorithms.
-
Zero-Knowledge Proof does not have the limitations of the above two methods and can make the network highly scalable through multiple iterations, but the only drawback is that it has a higher development threshold.
ZKP is currently the most attention-worthy technology in terms of privacy security and network scalability in Web3. It can help users prove certain attributes or qualifications without revealing any information, or it can simply provide a “yes” or “no” response to the service provider. The emerging zCloak Network has set a good example in this regard, achieving fine-grained control over the display of identity information. It has four VC presentation methods: ZKP Disclosure, Digest Disclosure, Selective Disclosure, and Full Disclosure.
In other words, based on ZKP technology, users can choose to disclose all, part, or none of their information, or obtain a “DeFi expert” label through covert data analysis to display their abilities and qualifications. At the same time, this allows service providers to identify whether users fully meet the criteria for their business objectives. This not only greatly protects the privacy and security of user data, but also respects users’ diverse disclosure preferences.
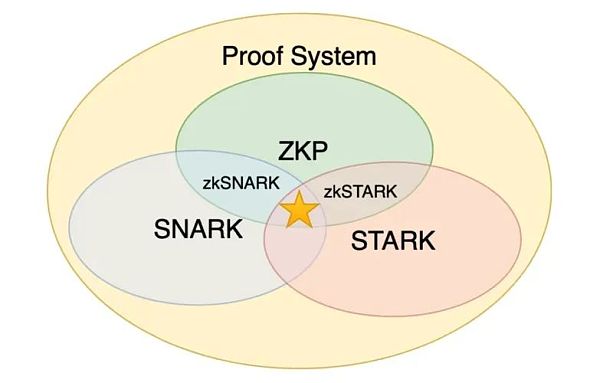
* An Analysis of ZKP
ZKP is currently divided into two systems: SNARK (Scalable Transparent Non-interactive Argument of Knowledge) and STARK (Succinct Non-interactive Argument of Knowledge). Both can be used to create proof of validity, and the main differences are explained in the following table:

SNARK:
-
The proof size is very small, so the verification time is short. Therefore, the gas fee required to process SNARK proofs on blockchains like Ethereum is relatively low, which is a major advantage.
-
However, it relies on non-standard security assumptions and requires a trusted setup phase. If there are issues during this phase, it may compromise the security of the system.
In comparison, STARK:
-
Relies on weaker security assumptions, is completely transparent, does not require a trusted setup phase, and is resistant to quantum computing (i.e., it has very high security).
-
It is also more versatile and has better adaptability to parallelization, eliminating the need for circuit customization for different scenarios. This can greatly save development costs and simplify the development process, unlike SNARK.
(Therefore, we can see that currently, SNARK is more commonly used for cross-chain and Layer 2 scaling, while STARK is more commonly used for privacy data protection. The former has smaller proofs, shorter verification time, and lower gas fees, while the latter has extremely high security and is more conducive to development. On June 20th, Ethereum co-founder Vitalik Buterin pointed out in his latest article “A Deeper Exploration of Cross-L2 Read Prioritization for Wallets and Other Use Cases” that zero-knowledge proofs (ZK-SNARK) are a very feasible technical choice for implementing cross-chain proofs, and zk-SNARK will be as important as blockchain in the next 10 years.)
Let’s use a scenario to illustrate the applications of these two. Suppose we want to implement a privacy voting system on the blockchain. This system requires verifying whether users have voting rights, but without revealing their identities:
-
If we prioritize efficiency and gas fees, then SNARK may be a better choice because it can generate smaller proofs and has faster verification speed. However,
-
If we care more about transparency and security, then STARK may be a better choice. Although its proofs are larger and verification takes longer, it does not require a trusted setup phase and is based on weaker security assumptions.
Generally speaking, SNARK and STARK each have their own advantages, and the specific use of which technology depends on the specific needs and scenarios of the application.
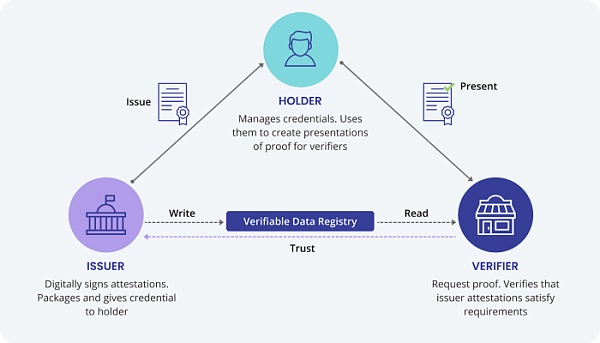
Participants in the DID identity system
They mainly include VC holder, issuer, and verifier.
The holder is the owner of a certain DID and the holder of the VC. They are the only ones authorized to share their credentials and the only ones authorized to choose individuals or organizations with whom they are willing to share their identity information.
The issuer is the issuer of the VC, usually played by a trusted organization, such as DAO, government, industry associations. It should be noted that even if the issuer creates and issues the VC, he does not own the right to use the VC, because it requires the corresponding private key of the DID to authorize the signature to use it, and the issuer does not own the private key of the holder. However, for some types of VCs, the issuer has the right to revoke them. For example, if a community member is found to be malicious, the DAO community can revoke the honorary certificate previously issued to him, or the traffic management bureau has the right to revoke the digital driver’s license issued to a driver when dealing with violations.
The verifier is the verifier and recipient of the VC. They can only verify the corresponding DID and VC and know whether the holder has certain attributes or meets certain conditions (such as user compliance) only with the authorization and consent of the holder, so that the holder can enjoy the services they provide with limited conditions through their DID.
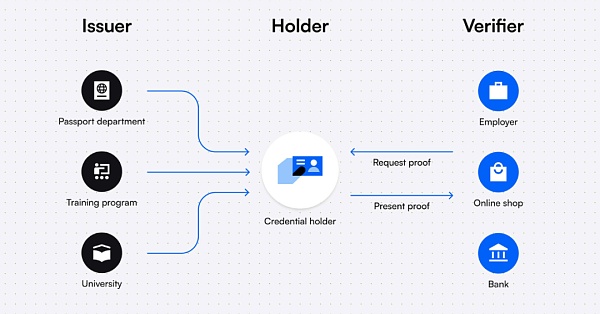
Let’s take an example to understand the relationship between the above three:
(Web 2) For example, when conducting background checks for new employees, the company needs to verify the job application information of potential new employees to determine whether they have the corresponding educational background, whether their previous work experience is true, and whether they are legal citizens, etc. At this time, the company is the verifier, the educational institution that issues educational certificates and the former employer who issues professional certificates are the issuers, and the new employees who hold these certificates are the holders.
(Web 3) For example, a community proposal of mockDAO requires only community members with Level>2 to participate in voting. In this process, mockDAO needs to verify the member certificates (VCs) issued in advance to confirm whether they meet these conditions. At this time, mockDAO is both the issuer and the verifier, and the community members who hold the member certificates are the holders.
Why do we need a decentralized identity system with DID+VC
The DID+VC identity system has a wide range of applications. Here, the author provides six commonly used application scenarios in Web3:
1. Universal and secure login
Users can directly log in to all platforms through a DID, and VCs authorized by platforms or contracts can control users’ access rights. This can break down barriers between platforms and no longer requires different “account + password” for logging in to different platforms. At the same time, users can freely show different VCs to platforms to prove certain conditions, improving user login experience and willingness to disclose information.
In addition, the commonly used wallet login in Web3 results in the interaction between the wallet and the platform being disclosed on the chain, which may stimulate some platforms to provide discriminatory services to users based on on-chain data such as financial status. Using DID login can prevent this from happening.
2. KYC Authentication
From a longer-term and broader perspective, all real-life or online scenarios involving identity information can use DID – for example, many online services, including some exchanges and wallets in the encryption industry, require us to scan and upload identification documents to complete KYC authentication – they usually require the verification of identity with cumbersome documents and electronic records, which are expensive, time-consuming, and may result in the leakage of user privacy, and it is also possible for service providers to be unable to verify and prove authenticity.
However, in the DID identity system, service providers verify user eligibility through VC with the user’s permission. The user’s sensitive information can be selectively or completely hidden, or partially or fully shared. Therefore, compared to traditional KYC authentication, it is more trustworthy and greatly reduces communication costs between users and organizations.
Even in real life, the DID+VC identity system can help loan companies easily verify applicants’ financial credentials while also respecting the user’s desire to maintain the privacy of certain data; in employee due diligence, it is convenient for employees to access qualification materials and properly store them, ensuring that the materials are not tampered with during circulation, and it can also avoid the situation where it is difficult to verify the authenticity of information due to inconveniences in the verification process, and so on.
3. Community Governance
(1) Protecting privacy while managing community identity and contribution data:
Many platforms and communities in Web3 adopt a centralized model to manage the identity and contribution data of members. Even if some organizations try to put them on the chain, Gas fees will still become a significant cost for organizational operations. After being on the chain, the content cannot be modified even with the owner’s permission, and the owner’s privacy is difficult to protect. Associating authorization keys and protocols with the DID+VC identity system can facilitate and discreetly manage identity and contribution data, fully protecting the data sovereignty and privacy of owners.
(2) Efficient governance of DAO
The example mentioned earlier about the mockDAO voting qualification certification also illustrates how efficient management of organizations such as DAO can be achieved based on the DID+VC identity system, saving the comprehensive costs of project parties, and providing users with a more concise and smooth operating experience. Since the custody and usage rights of VC are entirely in the hands of users, community members can also use VC to prove their contributions to a certain project or DAO, greatly reducing their communication costs with the organization.
4. Anti-Sybil Attack
A Sybil attack refers to a small number of people simulating human behavior by controlling a large number of robots in order to interfere with the operation of an organization and profit from it. This type of attack is easily seen in many airdrops and voting governance. The DID system can ensure that VC is only issued to real and valid users, and users can only participate in these activities by presenting and verifying credentials, while also ensuring privacy is not compromised.
5. Anti-phishing Attack
When the mnemonic phrase and private key are kept confidential, a user’s digital assets are usually secure. However, hackers can launch attacks by taking advantage of human errors or centralized platforms, such as spreading false information through Discord, email, Twitter, or trading platforms, or misleading users through counterfeit websites. In addition to being vigilant, carefully verifying transaction information, and protecting sensitive account information, it is crucial for users to timely verify whether unknown information originates from a genuine organization. This verification process involves:
(1) Confirming the authenticity and validity of the organization that publishes the information, ensuring it is not counterfeit or deactivated;
(2) Confirming that all content in the information originates from the genuine and valid organization.
Regarding the first point, from a use case perspective, users can learn about the legal basis and official identity information of an organization’s existence through trusted yellow pages similar to “Tianyancha,” or trust the authenticity of an organization’s public account and its published content through the “verified” badge on major social media platforms. However, both of these methods are manual, centralized, and inefficient authentication processes. Platforms also cannot timely update the development, deactivation, or change of ownership status of projects, nor can they verify whether statements made by departing or departed high-level executives represent the organization’s intent.
From a technical perspective, the authenticity and validity of identity can be verified through a certificate authority’s (CA) public key infrastructure (PKI) system or the PGP and Web of Trust personal key system developed by Phil Zimmermann. The former is completely centralized and limited to the SSL/TLS encrypted communication of websites. Various HTTPS websites use this type of certificate for website identity verification. The latter requires prior knowledge of the PGP public key of the interacting party, which may raise security and scalability concerns. Moreover, there is no clear method to check the authenticity and validity of identity, no punishment mechanism for incorrect authentication, and the use of cryptographic principles and command-line operations make it extremely user-unfriendly for ordinary users, making it difficult to empower general organizations or individuals with reputation and form network effects.
Regarding the second point – “confirming that all content in the information originates from a genuine and valid organization” – in the face of massive information, especially information related to wallet and asset interaction, both Web2 and Web3 require a valid verification path to help organizations and celebrities promptly refute rumors and assist users in timely verification, in order to maintain reputation and protect information and asset security.
Web3 has always lacked anti-fraud identity verification methods and paths for expressing verifiable information that can solve the above two problems. It was not until the emergence of the DID+VC identity system that a solution was proposed for them.
Because a subject’s DID can be completed with KYB and KYC certifications, its history can be recorded and verified through VCs. However, in this authentication, recording, and verification process, apart from the user and the trusted public institution that issues VCs, no one knows the user’s private personal data.
Alternatively, for organizations that are sensitive to KYB, they can authorize an official attribute of a DID by associating it with their public official channels, thus making information published only through that DID more credible (although it cannot be fully legally protected, reputation is also a very important factor in social acceptance), making users more willing to trust the information they publish, and helping to identify genuine and fake DIDs.
-
Driving the development of DeFi
All user on-chain activities can be written into VC, gradually accumulating their own on-chain credit as an important attribute of their identity, and also providing convenience for users to obtain third-party services. The DID+VC identity system can reflect users’ on-chain economic behavior in a way that protects their privacy, and record, verify, and present it in the form of a VC. This system can help DeFi determine the on-chain financial credit of organizations or individual users, and also help users obtain credit loan services similar to traditional finance. The token collateralization model may be weakened or replaced, bringing better liquidity and capital efficiency to the current DeFi ecosystem.
At this stage, the expansion of DeFi credit business is mainly limited by the identification of on-chain identities corresponding to real identities. If DeFi wants to accurately and effectively interact with users’ off-chain financial data to help evaluate their on-chain credit and even recover on-chain default behaviors, KYC authentication is inevitable. However, this may make the natives of Web 3 feel uncomfortable due to privacy risks and ethical risks of certification agencies.
On the other hand, it is difficult to judge and measure the credit level of Web3 users, which has also become one of the main reasons hindering the realization of low collateral rate credit business in DeFi. Therefore, it can only guarantee the safety of the project’s own funds by increasing the user’s collateral rate or over-collateralization, but at the same time, it reduces the capital utilization efficiency of the DeFi ecosystem, weakens the overall liquidity of the encryption ecosystem, and also excludes most cryptocurrency users who want to leverage credit. However, for this group of people, they apply for loans precisely because they lack funds or collateralizable assets, and due to the maturity and application scope limitations of the off-chain credit system, they may have difficulty obtaining the desired credit limit due to insufficient credit records in the real world.
The DID+VC identity system can potentially provide a solution to the above problems in DeFi credit business. By using VCs that are fully controlled by users and have multiple presentation capabilities, it can (1) reduce the cost for credit institutions to collect and verify past credit data, and even if future DeFi interactions with off-chain data are subject to mandatory KYC authentication; it can (2) guarantee users’ privacy demands during the data verification and presentation process. Apart from the trusted institutions that authenticate KYC and the institutions that authenticate the corresponding financial data, and the users themselves, no one knows any relevant privacy data of the users. If there is a leak, there is also a clear pathway for corresponding information accountability. In this way, DeFi applications can easily provide targeted services to different users, such as verifying users’ past on-chain and off-chain credit situations through their DIDs and verifiable digital credentials. If the repayment record is good, they can obtain low-interest credit loans or low-collateral loans.
Conclusion
The DID+VC identity system is the cornerstone of Web3’s journey to the masses.
As mentioned at the beginning, our expectations for blockchain, or Web3, stem from its ability to resist privilege and involuntary censorship. However, this does not mean that trust is completely unnecessary. We simply want to weaken or eliminate trust in central institutions that may betray or tamper with our information. We want to achieve this through data sovereignty. But at the same time, we also need credible institutions with legal obligations and responsibilities, such as public security and government, to verify the authenticity and credibility of various organizations and individuals in the network, as well as the authenticity and credibility of information and objects. We need them to supervise various entities (organizations, individuals, information) in the network to prevent and monitor fraud events caused by identity forgery, to implement legal accountability procedures afterwards, to cut off the chain of information leakage, and to recover some or all of the economic losses. All of this requires regulatory support and the implementation of KYC and KYB. Even if a person can have multiple DIDs, we only have one real identity. Only when multiple DIDs of a person are associated and authenticated with their real unique identity in reality, can we effectively eliminate fraud events caused by information theft in both Web2 and Web3. Only then can the data of Web2 be used in some way in the world of Web3, and only then can the application scenarios of on-chain DIDs be enriched. During the transition period when humans enter the cyber world, DIDs will carry the mapping of Web2 identities and social relationships into the Web3 world.
Of course, whether it is secure multi-party computation, homomorphic encryption, or zero-knowledge proof, if KYC certification based on these encryption technologies can be realized on a large scale by credible institutions with legal responsibilities, it can be said that Web3 is safer than Web2 because currently, some of our KYC certifications and very important identity privacy data are controlled by many commercial institutions. And when the DID of an organization or individual has a certain degree of recognizability in the network, more readable DIDs can endorse them. Of course, this road is very long, and other solutions may emerge during this process, so let’s not discuss it in detail for now.
The DID identity system, through cryptography and the technical interaction logic of the system, allows users to have ownership of their own identity data, breaking through the pain points of information misuse in traditional Internet, and increasing the cost of “wrongdoing” for organizations and hackers. While giving users data sovereignty, it also gives users a sense of security. It allows people to see the dawn of the ideal DeSoc digital society in Web3, where “code replaces governance”. It can integrate user identification problems in various tracks such as DeFi, DAO, and GameFi, solve on-chain KYC privacy protection issues, reform community governance methods, and prevent witch and phishing attacks. It makes Web3 a society that is safer than Web2, more inclusive of users, and more respectful of user rights and intentions.
Of course, the realization of this beautiful vision still requires a set of standard cross-chain, cross-platform, and even off-chain protocols to support it. It also requires the recognition of countless users, platforms, and even offline institutions, as well as the formation of network effects for usage.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Encrypted VC Why We Invest in Unibot
- ETHCC in the eyes of Arbitrum developers Scalability is a false demand, and it is still too early for a shared L2 sequencer.
- Investigation Confirms Cryptocurrency is the Future of France
- CZ Reissues Article from 6 Years Ago A Journey of a Thousand Miles Begins with a Single Step, Start Entrepreneurship from Small Matters
- LianGuaintera Capital Partner The Core Advantages and Ecological Status of Cosmos
- Opinion Chinese game teams are more suitable for exploring web3 compared to the West.
- AI economy may find an outlet in Web3.