4D long texts talk about decentralized storage
Author: Chen Yi-hsin
Source: HashKey Hub Community
Editor's Note: The original title was "4D Decentralized Storage"
Summary
Decentralized storage is a storage business model that uses distributed storage technology to store files or file sets in pieces on disk space provided by different vendors. It advocates strong privacy protection, low storage costs, data redundancy backup storage, high speed and other value propositions, open source applications and algorithms, and only by fully implementing the above claims can large-scale replacement of centralized storage be possible. It helps to avoid single points of failure and the value transfer of data. The architecture of decentralized storage is TCP / IP protocol, blockchain, decentralized storage protocol and application layer in order from bottom to top. Among them, the TCP / IP protocol corresponds to the network layer of Layer 0, including the network topology and the propagation mechanism of transactions; the blockchain belongs to Layer 1, which is an encryption infrastructure from bottom to top (usually algorithms such as SHA-256), Storage certification mechanism (consensus mechanism); decentralized storage protocol (service layer) includes storage protocol (on-chain), retrieval protocol (off-chain), identity protocol (on-chain), content distribution agreement, incentive agreement, etc., including Layer 1 And the smart contract and script files of Layer 2; the top layer is the application layer, including client software and acceleration software.
Decentralized storage differs from centralized storage in terms of storage space sources, bandwidth sources, security, usage methods, industry development status, and other dimensions, resulting in their scale and performance far less than centralized storage systems. Although projects such as IPFS make up for their different shortcomings through different "decentralized" design methods, and the total scale of storage on the entire network is expanded by giving tokens to uploaders and storage nodes, the interests of the project party and users are inconsistent. The disadvantages of cost structure and other factors make the development of decentralized storage into a bottleneck and stagnation. Based on the actual situation, this article provides reference suggestions for decentralized storage to realize its value proposition.
- Looking ahead to 2020 | Coinbase: What have cryptocurrencies experienced over the past 10 years?
- SheKnows End of Year Debate | Talking about Bubble Discoloration? Layout of blockchain, capital will never sleep!
- Blockchain landing application 2019 statistics: government affairs and finance occupy half of the country, and China's blockchain landing volume has reached the world
1 Decentralized storage background and value proposition
1.1. Background generated by decentralized storage WEB 3.0 advocates "data-centric, data value and privacy protection", and decentralized storage plays a vital role in it, where data security and privacy protection correspond to data redundancy Storage and backup functions, and the value of data corresponds to the value transfer of file sharing. In terms of data security, compared with individuals, companies tend to pay more attention to the security and privacy of company data. The data stored in the cloud by the enterprise is often the company's secret. Once a lot of data is leaked, it is likely to put the company in a disadvantaged position in the market competition. The traditional physical storage method of company data is not enough for large enterprises to support mass data storage. Demand; In terms of data value sharing, more and more people hope to obtain corresponding exchange value while sharing resources. For example, platforms such as the People's Congress Economic Forum and Himalayan need to exchange for legal currency or points when sharing knowledge and documents, while most Baidu web disks and Thunder are value-free transfers, they are only for download speed, etc. Performance charges a membership fee, and the seed of the shared content does not get the value gained by sharing the file. In recent years, the global and domestic cloud storage market has developed rapidly, from GB level to TB level and then to PB level. There are more and more types of file storage, and the amount of file data is also increasing.

Figure 1: The rapid development of the global cloud storage and domestic cloud storage markets
Data source: China Industrial Information Research 2012-2017, the global cloud storage market maintained a high compound growth rate of more than 20%, while the domestic cloud storage market growth rate remained at 85% -110%. According to the prediction results of many institutions, the global cloud storage market is expected to reach more than 100 billion US dollars in 2022.
Although the size and users of the cloud storage market are growing rapidly, the centralized storage market has four major shortcomings: the inability to protect copyright, the security of data, the risk of service providers stopping operations at any time, and the lack of value of data.
Whether it is a third-party centralized storage of companies such as Amazon, or the company itself stores user data, from a legal perspective, users do not have the possibility of expecting them to disclose data information. Especially in the era of the business model where data is king, companies with accurate data will restructure all industries, control data sources or obtain data at a lower cost than competitors, and their competitiveness will be significantly higher than their competitors . Therefore, competitors often find ways to obtain data, and leaking or selling user data can often give data storage service providers huge benefits.
After user data is collected, centralized storage exposes user data to huge risks (leakage, hacking, etc.). The CSO counted the 18 most significant user data breaches since 2000, especially in the last two years, and the magnitude of the data breach has also increased exponentially, whether it is external factors such as hacking attacks or malicious internal causes of centralized storage. . For example, India's 1 billion citizenship database, Aadhaar, was exposed to cyber attacks, Facebook Cambridge Analytica, and more.
Figure 2: Major user data breaches in the 21st century
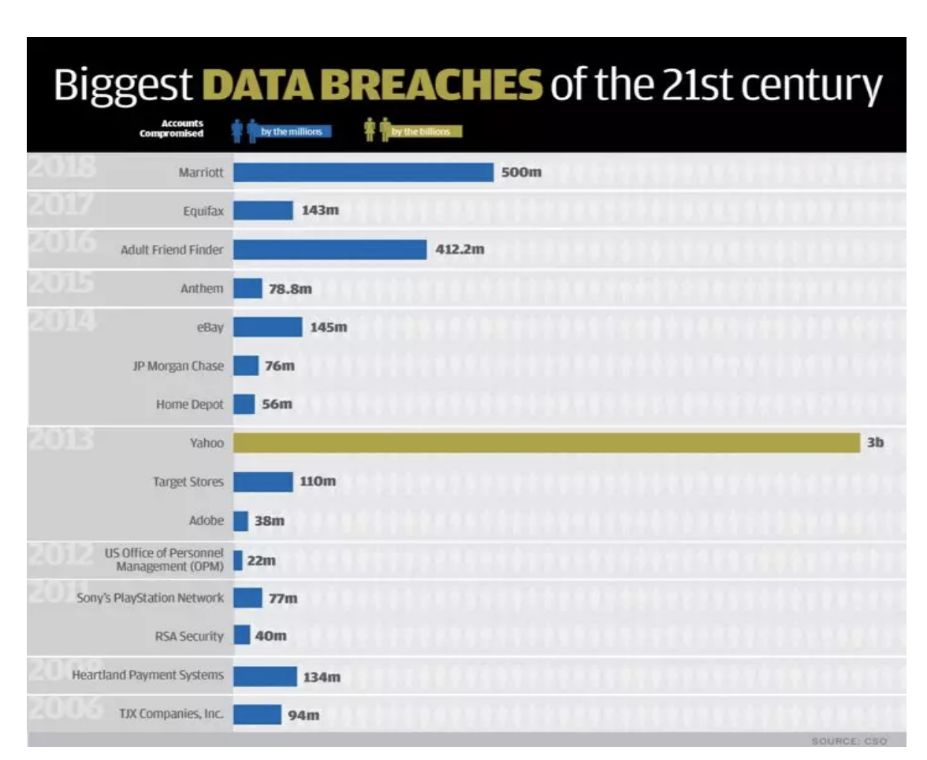 Data source: CSO From this, the business model of decentralized storage came into being.
Data source: CSO From this, the business model of decentralized storage came into being.
Decentralized storage is based on blockchain technology. Through the decentralized architecture, the advantages of centralization and decentralization are combined to explore the balance between efficiency and fairness, so as to improve the security of storage. The centralized processing of the storage and API interfaces has greatly improved the TPS of the storage network on the basis of the existing public and alliance chains; and by implementing incentive measures for seed nodes or file uploaders, their data can be valued.
1.2. Connotation and Extension of the Definition of Decentralized Storage
The business organization of the storage market can be divided into centralized storage and decentralized storage. Centralized storage is the complete storage of data on a server developed by a centralized organization, while decentralized storage is the distributed storage of data slices on multiple independent storage vendors. The technical implementation of the two is usually embodied by distributed storage. Distributed storage is a data storage technology. It stores data on multiple independent machines and devices in a distributed manner, and implements redundant storage of data through erasure coding technology. The distributed network storage system adopts a scalable system structure, uses multiple storage servers to share the storage load, and uses location servers to locate storage information, which solves the bottleneck problem of a single storage server in a traditional centralized storage system and improves the reliability of the system. , Availability and scalability.
It should be noted that distributed storage is just a technical way of storage, and centralized or decentralized storage is the business model of storage. Because the device server and storage provider have a one-to-many relationship, that is, a storage vendor can control multiple storage nodes, decentralized storage must use distributed storage technology; however, centralized storage can use distributed storage technology It is also possible not to use distributed storage technology.
Figure 3: Demonstration of distributed storage technology in decentralized storage and centralized storage
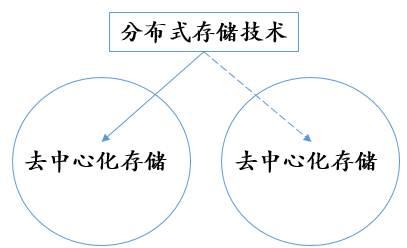
1.3. Value Proposition of Decentralized Storage
Decentralized storage represents the fundamental change in the efficiency and economy of large-scale storage. Its value proposition is mainly reflected in the following aspects:
(1) Enhance security and user privacy. Decentralized storage encrypts data not only for users and software terminals, but also performs encryption processing on all links of the storage network, and protects user privacy through methods such as private network access keys and zero-knowledge proofs.
(2) The algorithm and code of the storage platform or network must be open source. Since the storage service on the 2C side has been seized by most centralized markets, and due to the higher entry barriers in the early stage of open source projects, most of them are concentrated on the 2B side. Only open source code can make the improvement of communities and applications form an effective positive feedback effect. If the algorithms and code are not transparent, the storage network will be centralized in disguise.
(3) Prevent data loss through redundant backup. Data is stored on different nodes, and data redundancy is used to prevent data loss (additional copies are stored in the event of data storage or transmission errors).
2 Architecture and Operation of a Decentralized Storage System
2.1. The working principle of decentralized storage In the file sharing method, the decentralized storage system file sharing method is completely different from the centralized storage. After uploading large files in the centralized storage system, the files are stored as a whole or in slices. Or distributed network or server, it needs its highly efficient development and operation team to maintain its operation. However, decentralized storage must use distributed storage technology. After the initial seed node (the node that originally had the full file resource) sliced a large file, it generated multiple Pieces, each of which was stored on a different node. In general, each general node downloads a single piece of Piece and uploads it to the decentralized storage network. After other nodes download, it becomes the seed node of this piece of Piece. In the process of multiple nodes sharing each other's piece of Piece, it is possible to achieve the removal of Piecee from the initial seed node. Outside the node sharing, and the number of nodes in the file sharing network is constantly expanding. Therefore, when other conditions remain the same at the same time, as the number of downloads increases, the speed of downloading the same content is faster. Therefore, the decentralized storage system makes up for the shortcomings of the slow transmission speed of the centralized storage system, while overcoming a single point of failure and ensuring data security. Figure 4: How Decentralized Storage Works
Data source: HaskKey Hub
2.2. Architecture of Decentralized Storage
Decentralized storage architecture has four components from the bottom up: network protocol (TCP / IP), blockchain or distributed ledger, decentralized storage protocol and applications. Among them, the network protocol corresponds to Layer 0; the blockchain or distributed ledger corresponds to Layer 1's underlying encryption and consensus mechanism; the decentralized storage protocol corresponds to Layer 1's incentive mechanism design and identity protocol, and Layer 2 The smart contracts, scripting languages, and API interfaces that interface with various applications are directly connected to various service applications, which are generally presented in the form of APIs or smart contracts; the applications correspond to the application layer of Layer 2 [1].
Figure 5: Decentralized storage bottom-up architecture levels and corresponding
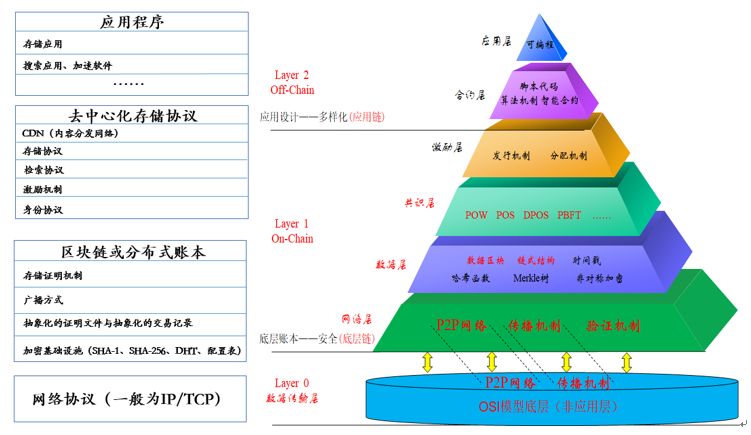 Data source: HashKey Hub
Data source: HashKey Hub
2.2.1. Network protocols and network layers
Network protocols include TCP / IP network protocols, storage networks, and propagation mechanisms. The way the network topology is structured and designed often represents the way in which the system's value goals are achieved, and determines the efficiency of its propagation and verification mechanisms.
The topology of the storage network can be a P2P network or a decentralized network with intermediary service providers or operators with several alliances (this network topology is defined as a non-P2P network), but it does not include a single or oligopoly center A distributed storage network based on multiple servers built by a storage service provider.
Figure 6: Non-P2P networks and P2P networks

Note: The left side is a non-P2P network, and the right side is a P2P network Data source: https://dwz.cn/6RvaeCgQ
2.2.2. Blockchain or distributed ledger
The blockchain or distributed ledger of a decentralized storage system generally includes encryption infrastructure, transaction records, broadcast methods, and storage certification mechanisms.
For the encryption infrastructure, the encryption method is generally encrypted by a hash function, including algorithms such as SHA-1, SHA-256, or Allocation Table, which is connected to Merkel root. After the data is encrypted at each link, Then, through the distributed hash table (DHT, Distributed Hash Table), tracking server (Tracker) and other methods, the primary network (Key-seed file address) to retrieve the shared network of specific storage content.
For the proof-of-storage mechanism (PoS, Proof-of-Storage), it is generally proved that the server has stored the specific download content and the integrity of its data at a specific time without downloading the content, thereby reducing the fraud of malicious nodes. space. It includes Proofable Data Possession (PDP) and Proof-of-Retrievability (PoR), but different projects have improved the consensus mechanism for different evil motives and methods. For example, IPFS uses the Proof-of-Replication (PoRep) and Proof-of-Spacetime (PoSt) methods to curb witch attacks, generative attacks, and exogenous attacks, respectively [4].
For transaction records, transaction records are generally encrypted in an abstracted form and recorded on the chain. The occurrence and recording of transaction records must be completed after the storage certificate is completed, and the file name, time stamp, file type and other information are combined into a block header and stored. On the chain.
2.2.3. Decentralized Storage Protocol
Decentralized storage protocol is the core of the whole system, including storage protocol, retrieval protocol, incentive mechanism and identity protocol. Among them, the incentive mechanism and identity protocol are at their lower layer, generally in Layer 1 (on the chain); the storage protocol and retrieval protocol belong to the service layer, which contains various smart contracts and script files, which determines the design of related applications. Generally, it is in Layer 2 (off-chain). Due to various factors such as different positioning of decentralized storage projects and different stages of development, the design of decentralized storage protocols in different dimensions is quite different.
In terms of the identity protocol, it is divided into the identity of the storage user and the identity of the node. The storage user's identity is generally presented as the formation of a decentralized identity (DID), but there are special cases of BitTorrent's centralized identity. Users only have the control, permission, and income rights over their own identities and their related data only in the case of providing minimal personal information that satisfies the function; node identities are generally hashed in the retrieval process. The form is stored on the chain, and the tracking node or hash table can effectively query the seed node of a specific file or file set. The general expression is a URL.
In terms of storage protocols, the agreement states that user nodes download their interested files or file sets from seed nodes by paying tokens or free of charge, while their counterparty nodes earn tokens by providing storage space (purchase or lease) or bandwidth resources. Or get a higher probability of obtaining accounting rights, and then form a two-way smart contract or transaction order. First, the file or file set needs to be sliced. After the process in section 2.1, the storage disk space is provided by all nodes in the content sharing network (Swarm) with relevant shards. All the steps in the storage protocol are performed on the chain, including the generation of orders, the verification of the consensus mechanism, and the transfer of value.
In terms of retrieval protocols, decentralized storage retrieval protocols are generally implemented off-chain, and are developed, maintained, and operated by centralized institutions. Only in the case of a token economy, its value transfer is still performed on-chain. Records are abstracted and encrypted and recorded on the blockchain or distributed ledger. The retrieval method generally searches the seed node and the shared network through the node identity (URL format), and connects the downloader with a centralized retrieval server and DHT (distributed hash table) to perform resource retrieval. DHT is an improvement on Tracker's retrieval method. It uses Key (a hash string generated by the hash function to retrieve the content) to retrieve specific content, and greatly improves the retrieval efficiency.
Figure 7: DHT retrieval principle
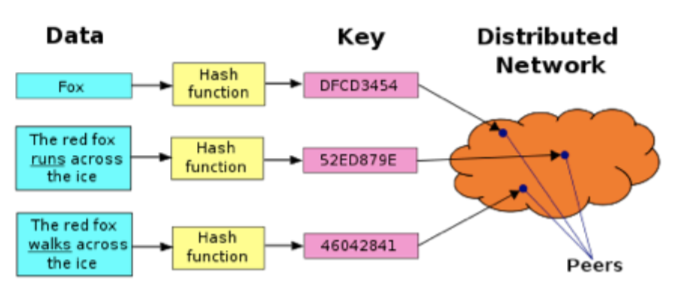
Data source: https://dwz.cn/hKCgNhEY
2.2.4. Application layer The application layer generally includes storage client software (including storage functions and retrieval functions), acceleration software, and user agent programs. Profitability is achieved through SaaS (Software-as-a-Service). Application software and its related infrastructure are in Layer 2 (off-chain). The client software generally interacts directly with the user. It is essentially a data sensor that records the user's behavior in the storage network, evaluates its conversion rate, the number of active users (daily and monthly), and search history. Provide effective reference for the future development and operation of the project. Through the DID (Decentralized Identity) mode, the nodes can minimize data exposure, so that the decentralized storage client can only picture the user's storage behavior based on the function, and does not reflect anything other than the storage and retrieval functions Data information.
3 Comparison of Decentralized Storage and Centralized Storage
3.1. Comparative Analysis
Figure 8: Centralized storage vs. decentralized storage

Data source: HashKey Hub
3.1.1. Differences in storage space and bandwidth sources
Centralized storage refers to a business model in which a single or oligopoly third-party organization uses its own server to provide large-scale data storage services to the outside world; decentralized storage refers to the interconnection of a large number of ordinary PC servers through the Internet as an external storage service.
The source of centralized storage space is a storage cloud developed and operated by a designated storage service provider, such as the servers of Amazon S3, Alibaba Cloud, and Huawei Cloud. The download bandwidth is provided by the service provider. The source of decentralized storage space is A large number of PCs, mobile terminals and other devices that can provide storage space, all nodes in the shared network of the same file or file set can provide bandwidth for their download.
3.1.2. Differences in use
Due to the different sources of storage space, the file storage and retrieval methods are completely different.
In terms of storage , centralized storage is developed and operated by a centralized storage service provider, so the file storage capacity is large enough to store large amounts of data and store files (whether text, voice, video, etc.) as a whole. Into the cloud, there is no need to slice and deduplicate the files; decentralized storage is relatively scattered due to the storage providers (service providers or individuals), and the corresponding matching optimization algorithm is required in the redundant storage space To find the best storage space provider (that is, the fastest storage and the right storage space). And in order to ensure that the stored data will not be lost due to external factors such as single point attacks or failures, witch attacks, etc., the decentralized storage system slices the files after encryption processing, and decentralizes the storage to the disks of different storage providers. In space.
In terms of content retrieval, centralized storage accesses stored data in the form of an account paradigm, and connects to the Tracker by entering an HTTP URL to search for specific storage content; decentralized storage because the data is scattered and stored in different Nodes, it is necessary to use a DHT distributed hash table to generate a hash string from each node's link using a hash function, so its download speed increases as the number of downloads increases. However, it also results in a large amount of data redundancy, which easily causes waste of storage space resources (such as disks) and bandwidth.
3.1.3. Differences between security and privacy protection
Decentralized storage and centralized storage have their own advantages and disadvantages in terms of security and privacy protection. The advantages of decentralized storage are mainly reflected in the following two aspects:
On the one hand, decentralized storage avoids risks such as a single point of failure and the disconnection or unavailability of some nodes. Because the shared network of decentralized storage is a P2P network, and the shared network of centralized storage is a centralized network centered on a service provider, the former is not easily affected by a single point of failure and the server is disconnected. Attacked by hackers.
On the other hand, decentralized storage prevents users' specific storage content from being leaked for subjective reasons. Decentralized storage uses zero-knowledge proofs and asymmetric encryption to place hash-encrypted strings at the bottom of the block and connect to Merkel root, so that the shards of the stored content are encrypted. Any other Nodes, including operators, cannot see the specific content of the storage; while centralized storage systems such as Amazon S3 can be seen by the account content paradigm, which can be seen by specific content service providers, leading to large-scale cloud leaks and frequent cloud security events, and user privacy Cannot be effectively guaranteed.
But the disadvantages of decentralized storage are also obvious. When the non-permissive blockchain technology is used to implement the decentralized storage mode, due to the block-wide broadcast and time stamp technology, all participating nodes know that a node is storing data at a specific moment, and as the nodes The interaction frequency is increased, and the full node can easily find the block in which the transaction occurred, thereby revealing the identity behind the hash value, and using an algorithm to infer the storage balance of the requestor or store. Coupled with decentralized storage, if each fragment is generally 64-512KB, once most storage space of the storage network is in the hands of a few storage vendors, it will be easier to crack than the entire file storage.
3.1.4. Differences in storage fee structure
Due to the differences in the storage and retrieval methods of centralized storage systems and decentralized storage systems, there is a difference in pricing of service charges between the two.
The charging standard of the centralized storage system is to charge storage fees based on the size of the stored data files on a monthly, quarterly, or annual basis, and implement a certain promotion strategy (free trial period, etc.) for the storage fees. For example, Amazon S3 charges a storage fee of $ 0.03 / GB per month; Alibaba Cloud uses differentiated pricing for individuals and businesses: the individual charges are 10 yuan / GB per month, and the enterprise charges 2.5 yuan / GB per month.
Since most decentralized storage network platforms are in the early stages of project operation and most products are in the development or MVP phase, they attract user traffic with low storage costs. However, compared to centralized and relatively fixed service costs, in addition to storage costs, decentralized storage also has retrieval costs, handling fees, and transaction costs. Therefore, decentralized storage is only suitable for cold data storage, and its cost is much lower than centralized storage when the amount of retrieved data is small. For hot data, the cost of frequent retrieval may be higher than the cost of centralized storage. For decentralized storage, the storage sharing network must be accompanied by an increase in search popularity while expanding the scale, and an increase in search popularity must be accompanied by an increase in search costs, which is a problem and challenge to a certain extent.
3.1.5. Usability differences
In terms of availability, centralized storage has significant advantages in the current state.
On the one hand, the file storage form of centralized storage uses the entire copy upload, and its data integrity is better than that of decentralized storage. Generally, the measure of availability is the number of complete copies of a file (or set of files) directly available to the client. For example, for a seed node, because it has uploaded a complete content resource, its availability is 1, and for a decentralized storage shard, different Pieces are stored on different nodes. The availability of a single node in the shared network is usually less than 1.
On the other hand, centralized storage is operated by one or oligopoly service provider and maintains the sustainability of its shared network. The duration of a specific shared content network is longer. The validity of its HTTP URL is permanently valid without the uploader actively deleting it; decentralized storage is relatively short-lived in terms of the sustainability of the availability of stored content, mainly due to the lack of an effective incentive mechanism.
3.1.6. Differences in storage file size and type
Centralized storage has no restrictions on the size and type of stored files, and can upload and store both video, audio, and documents, which has significant advantages.
Decentralized storage has different file types and sizes suitable for different projects. For example, Storj defines small files as less than 1MB and large files as more than 4MB. Obviously, the larger the file, the more difficult it is to slice. Some decentralized storage networks can only store text documents and images, while others can store video and audio, resulting in a relatively fragmented market.
Decentralized storage can reduce the risk of data failure and interruption, while improving the security and privacy of object storage. It also enables market forces to optimize lower-priced storage at a higher price than any single provider can afford. Although there are many ways to build such a system, any given implementation should address some specific responsibilities. Based on our experience with petabyte storage systems, we have introduced a modular framework to consider these responsibilities and build our distributed storage network. In addition, we describe the initial implementation of the entire framework. For large files (generally larger than 1GB), too many strings are generated by hash encryption, so that users cannot remember their hash strings, which leads to the decline in the acceptability of users for decentralized storage.
3.1.7. Differences in download speed evaluation methods
There is a significant difference in the evaluation of download speed between decentralized storage and centralized storage.
Centralized storage provides users with bandwidth to download through a centralized server. As long as the membership fee or membership level is paid, the download speed can be significantly increased. For example, when users use Baidu web disk, the download speed is only 200KB without a member. / s, and in the case of becoming a member, the download speed is as high as 2-5MB / s, and there will also be a limited speed measure; the download speed of decentralized storage depends on its contribution, that is, the number of content fragments currently uploaded by the node With other conditions unchanged, the larger the number of seed nodes, the larger the number of downloads, the more uploaded content, and the faster the download speed. At the same time, free-riding nodes that "download only, not upload" are appropriately penalized in the form of speed limit [5].
3.1.8. Differences in development level
The centralized storage market dominates and is in the mature stage; decentralized storage is still in the initial stage, and the technical architecture and system are not yet mature.
From the perspective of industry cycle theory, the development stages of the industry are divided into the start-up period, growth period, mature period, and recession period. The total revenue of the storage market has reached more than US $ 13 billion. Centralized storage has now formed an oligopoly competition pattern in the first half of 2019. It is dominated by giants such as Dell Technology, H3C, IBM, Lenovo, Huawei, etc. The storage company's market share reached 62.9%.
The Sia, BitTorrent, IPFS and other decentralized storage projects are still in the development stage, and the progress is relatively slow. The total storage space of the developed Sia and Storj is only 2PB, and the actual space used is only the total network storage Less than 40% of it is far from the revenue of centralized storage.
Figure 9: Storage market share distribution
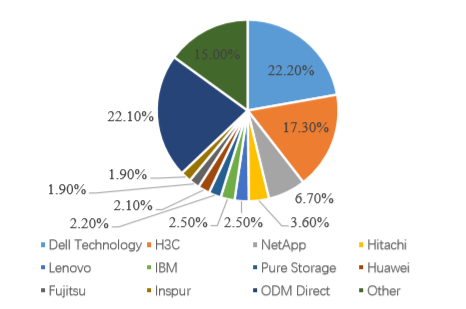
Data source: http://www.cnbp.net/news/detail/22363
3.2. Challenges of Decentralized Storage
Compared with centralized storage, although decentralized storage has certain advantages in privacy protection and security, there are still many shortcomings in terms of technology, governance, and incentive mechanisms, such as the weakened user experience for large files and the cost of There are contradictions between scale and efficiency in the design of stability and incentive mechanism. Therefore, in the future, the decentralized storage market needs to gradually improve by introducing stable fee pricing, establishing appropriate incentive mechanisms, etc., while maintaining the advantages of security and achieving both scale and performance. Next, we will briefly analyze the existing decentralized storage projects and evaluate their advantages and disadvantages accordingly.
A brief analysis of 4 decentralized storage projects
4.1. Representative projects
At present, the decentralized storage projects that have been deployed cannot be classified from a single dimension. Each project has its own characteristics and can only be roughly divided. According to the mode of function implementation, projects represented by BitTorrent, IPFS and Lambda are more inclined to content-based file sharing networks, while projects represented by Sia, Storj, and MaidSafe are more inclined to provide electronic network disks.
BitTorrent is the earliest decentralized storage project, but because most of it lacks an incentive mechanism, only a small part of it has introduced the BTT economy of the TRON network, so it is the prototype of the decentralized storage model; IPFS is the financing quota for decentralized projects The largest, with a cumulative financing amount of up to $ 257 million, stimulates peer-to-peer storage through block rewards, fees and service fees, and matches the supply and demand of storage through an optimized Kademelia algorithm; Lambda introduced the TBB economy on the basis of IPFS By reducing the entry barriers of storage miners by pledged TBB tokens; Storj and Sia are more inclined to provide electronic network disks and do not require actual storage, as long as sufficient storage space is provided to mine; Sia is through built-in smart contracts This method provides a space for negotiation and communication between different nodes in a P2P storage network.
Figure 10: Comparison of representative decentralized storage projects

(2) Working principle
The working principle of BitTorrent is not different from the general decentralized storage protocol. As explained in section 2.1 above, the file is sliced, and each Piece is divided into multiple blocks with a size of 64-512KB. Each block generates a hash. The string is then encrypted using the SHA-1 algorithm and distributed to each node in the shared network (Swarm) of the file or fileset. Peer nodes with complete files are seed nodes, others are non-seed nodes. Then, all nodes in the shared network transmit file resources to each other, so that more nodes become seed nodes, and 2 nodes outside the shared network are selected by the Opitimistic Unchoked algorithm to expand the shared network.
(3) Project structure
Figure 11: BitTorrent bottom-up architecture diagram
Data source: HashKey Hub
BitTorrent's architecture is arranged using a "P2P + centralized" two-tier model, where the storage sharing network uses the P2P model, and the retrieval protocol uses a centralized retrieval model. Its index file suffix is ".torrent". In terms of retrieval, as described in Section 2.2.3 of this article, BitTorrent retrieval uses the encrypted link as the identity of the node, and uses the hash distribution table to connect to the tracking server to efficiently retrieve specific stored files or file sets. Among them, the Torrent file consists of two parts, Announce and info. Announce is the URL required for retrieval, and its data type is string. Info is a dictionary-type data whose index includes Name (content name), Piece Length (each The byte size of the slice, except for the last slice, is equally divided), Pieces (each Piece encrypted with SHA-1 hash to facilitate hash verification), length or files (whether the content is a single file or a file set).
In terms of storage, a specific Torrent file is sliced and stored on different nodes. Before that, the Tit-for-Tat (TFT) incentive mechanism must be used to filter the nodes in the content sharing network. BitTorrent divides all nodes in the content sharing network into choked nodes and non-blocked nodes. Only non-blocking nodes have sufficient speed or bandwidth to download or upload the content, while blocking nodes cannot transmit content. Nodes will be determined as blocked by the following three situations:
(A) Nodes that have contributed too little or have hitchhiked too much (only download but not upload) and are therefore blacklisted;
(B) the receiving node is itself a seed node;
(C) A node whose storage space is full.
Under the incentive mechanism of the TFT (Tit-for-Tat) algorithm, on the one hand, the blocking node is confirmed in the content sharing network according to the above determination method. The other nodes in the sharing network are non-blocking nodes, and then 2 random samples are taken out. Nodes outside the shared network act as Optimistic Unchoking nodes. On the one hand, the Leech behavior of nodes in the shared network is curbed; on the other hand, it is beneficial to the expansion of the shared network.
(4) Project evaluation
As the earliest distributed storage project, the BitTorrent project has been more successful in the design of incentive mechanisms and shared networks, and it has been generally favored by users through a free model, and the more people download through the P2P network, the faster the speed Quick target.
But BitTorrent still has some room for improvement. First, BitTorrent can only confine the incentive mechanism to the same content sharing network, and lack effective incentives for users to maintain the availability of content after downloading. Second, due to the open source of BitTorrent's protocol, piracy is rampant, and even through this The spread of violent and pornographic content on the Internet has led to the ban on the use of BitTorrent in some countries (such as France) that value intellectual property rights; in addition, BitTorrent is unfair to nodes that contribute high bandwidth. When other conditions remain the same, The higher the bandwidth, the longer the delay of the TFT algorithm, and the lower the marginal increase in download speed [7].
Figure 12: Download speed decreases as bandwidth increases
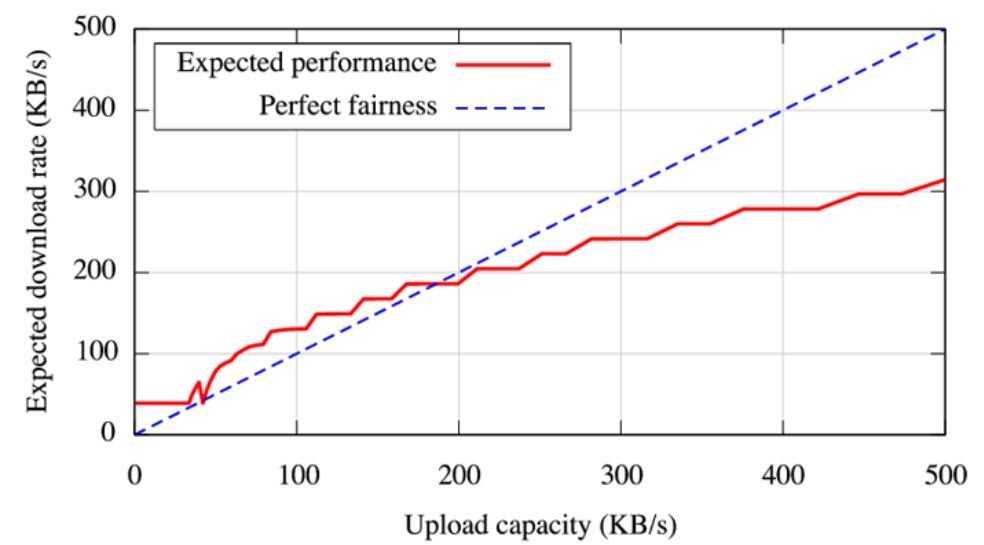
Data source: http://bittorrent.org/bittorrentecon.pdf
4.3. IPFS-the project with the highest financing limit (1) Project introduction
IPFS is essentially a low-level open source file transfer protocol designed to complement or even replace the HTTP URL-based retrieval protocol. Its token is Filecoin. Although Filecoin has not yet been officially listed or issued on the exchange, Filecoin futures went online as early as August 2017. Filecoin has received more than 250 million US dollars in financing since its launch, and its financing amount far exceeds other decentralized storage projects. The project is currently in the development stage. Protocol Labs is still in the development stage for the Filecoin incentive mechanism and economic model.
(2) Project structure
Figure 13: Bottom-up IPFS architecture

Data source: The lowest level of the HashKey Hub architecture is Libp2p, which includes the routing layer (network protocol) and the switching layer (P2P network) to ensure that data can be transmitted point-to-point on the point-to-point network. The upper layer is Multiformat, which is used to encrypt data and abstract the data into a format on the chain.It is essentially a collection of protocols for future systems. Addresses, encoded values, serialized values, network transport streams, and packet network protocols to achieve interoperability and avoid being locked up.
The next layer is the Filecoin protocol as an incentive layer, which includes the on-chain storage market, off-chain retrieval market, and the Filecoin blockchain [4]. In the storage market, miners rent or purchase storage space by staking Filecoin, then users initiate directed storage requests to them, generate bid (user) and ask (miner) two-way orders, and perform PoRep (proof of copy) and PoSt (proof of time and space). Finally, the user obtains effective storage (the storage size after completing the two types of consensus), and the miner receives the storage fee. Note that regardless of the order, transaction record, or value transfer of Filecoin, all is completed on the chain. In the search market, users first initiate a search request, then the miner obtains a search order and provides a search service. Finally, the user obtains the service by paying Filecoin. Note that only the value transfer of Filecoin is recorded off-chain, and the rest are completed off-chain. As for the Filecoin blockchain, it is divided into Orderbook, Transactions, and Allocation Table. The bottommost configuration table is connected to Merkel root to encrypt the information on the chain, which is used to store the digital signatures of both parties, to ask the miners and accept their responses; the transaction records are used to implement the value transfer function of Filecoin; the order book is used To record storage orders.
Figure 14: The bottom-up Filecoin architecture
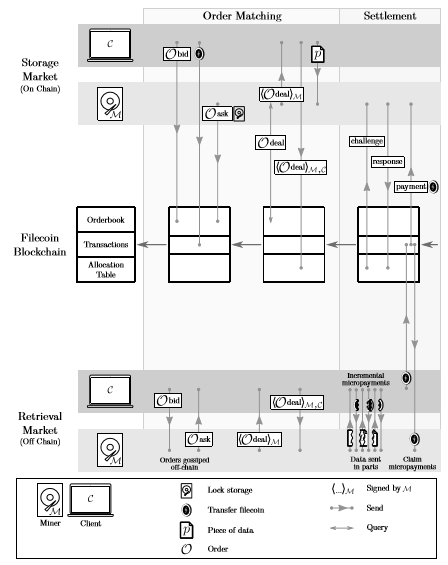
Data source: "Filecoin White Paper" IPLD includes a naming layer, an object layer, and a file layer, which are used to define and find data, thereby realizing the process from file naming to programming to retrieval. For the naming layer, IPFS uses IPNS to lock to its latest state in the case of file name changes. It uses a self-certification method to assign a variable namespace to each user (the path is / ipns /). Users can Publish an object signed with your own private key under this path. When other users obtain the object, you can check whether the signature matches the public key and the node ID (the link generated before IPFS). For the object layer, IPFS uses Merkle DAG technology to build A directed acyclic graph data structure is used to store object data, usually referenced by a Base58-encoded hash. The data structure has the characteristics of content addressability, tamper resistance, and deduplication; for the file layer, it will be larger than 256KB. Data file is divided into multiple blocks (256KB each), the data type of each block is a blob object, the list object is composed of several blob objects (may be repeated), and Tree is a json format from name to hash value Mapping table, because Tree is smaller than blob, which facilitates retrieval through DHT. (3) Project evaluation
IPFS uses PoRep and PoSt's proof in governance to effectively curb speculative actions such as witch attacks, generative attacks and exogenous attacks, and by forcing the purchase of GPU miners, PoSt can prove every 45s whether "any node is in this particular A file of a certain size has been stored at the moment. "Each file slice (Piece) retains a root hash value through the Merkel tree, which greatly reduces data redundancy. However, as the project is in the initial public beta stage, the following points are worth exploring:
(A) The IPFS market is very niche, only for private storage (because of limited capacity), and due to the high mining cost of GPU miners, households cannot directly participate in storage mining and can only participate in the retrieval process and earn Taking service fees is only attractive to large-scale mining pools or partnership storage vendors, which is not conducive to the concentration of the entire network's total storage in a small number of storage vendors or mining pools, and it is easy to fall into the oversupply of Filecoin;
(B) If the amount of data is large (more than 1TB), users must remember and retain multiple root hash values, which is not conducive to user experience. How to control the churn rate of a few home users will become a challenge for the development of IPFS;
(C) Compared with BitTorrent, even if IPFS is initially stored free of charge, the retrieval fee is determined by the popularity of the data. It does not provide permanent storage. It only rents storage space, high storage costs and retrieval costs, and high investment (GPU mining machine). User threshold is extremely high;
(D) The IPFS network does not have a P2P node for a specific server, and the efficiency needs to be further strengthened;
(E) Failure to adequately curb the behavior of storage miners uploading large amounts of junk data as effective storage;
(F) The PoRep consensus mechanism determines that the entire network cannot be verified. Only paid storage can be used for mining. If the scale is increased, since the block production rate of Filecoin is equal to the effective storage of the mining node divided by the total storage capacity of the entire network, The difficulty of mining will increase greatly, it will not be able to earn income, and it will easily fall into a price war.
4.4. Lambda-IPFS-based extension
(1) Project introduction
Lambda is a blockchain data storage infrastructure. It is realized by logically decoupling and separately implementing Lambda Chain and Lambda DB. It provides infinitely expandable data storage capabilities through Dapp, and realizes multi-chain data collaborative storage and cross-chain data. Management, data privacy protection, data holding proof, distributed intelligent computing and other services.
(2) Project structure
Lambda includes Lambda Chain (homogeneous multi-chain chain system), Lambda DB (homogeneous multi-chain chain system), Lambda Agent (probe system that provides memory data storage, performance monitoring, security monitoring, and Metrics data upload capabilities), Lambda P2P (provides data retrieval function) [8]. Lambda adopts the architecture design of chain library separation for two reasons:
(A) Because the blockchain system update results in a fork, the main data processing capabilities are placed on the database (Lambda DB);
(B) Ensuring its scalability through functional sub-chains, thereby achieving privacy protection (based on multi-authority agency attribute encryption) and data holding certificates (PDP, Provable Data Possession).
Figure 15: Lambda architecture with chain library separation

Data source: "Lambda White Paper" (3) Economic design The Lambda project uses LAMB and TBB double-layer tokens to implement incentive and punishment measures for storage mining and pledged storage respectively. Among them, LAMB is a native token that is used for block reward distribution, circulation, payment of transaction fees and settlement of ecological application fees; TBB is a storage space asset of the storage network, whose main role is to pledge and anchor the interests of storage assets.
There are five main roles in the Lambda network: storage miners (providing storage space), verification nodes (responsible for operating and maintaining the consensus network), storage asset market makers (providing storage resource liquidity for storage miners), and partner nodes (responsible for ecology Construction, does not participate in the storage network), block-producing nodes (selected by the verification node in combination with the pledged capacity and selected by weight, responsible for the packaging of block data and the initiation of consensus) [9].
There are two types of block rewards: For storage and mining, 43% of block rewards are given to miners and their verification nodes; for pledged mining, 50% of block rewards are given to miners and their verification nodes. The block packaging revenue of the two is based on the number of votes collected by the verification node to determine the packaging block revenue (1% -5% of the total block reward), the community revenue accounts for 2% of the total revenue, and the validator can customize the commission fee rate.
When the verification node double-signs the block, signs less than 500 of the nearly 10,000 blocks, and pledges less than 666.66TBB, it will be punished by "deducting the pledged TBB and submitting verification node candidates".
(4) Project evaluation
Lambda is deployed in a centralized manner on storage market makers and databases in a decentralized manner, which greatly improves the data throughput of the entire network and greatly enhances the network's future scalability. It is essentially an extension and expansion of the IPFS project, and it lowers the threshold for use by introducing the TBB mortgage storage mechanism, but it is still not conducive to home users participating in storage mining.
However, Lambda still has some questions. For example, Lambda through the NPoS (Nominated Proof-of-Stake) and PDP (Provable Data Possession) storage certification mechanisms can not prove that storage miners maliciously store a large amount of junk data, thereby increasing its packaging probability to earn LAMB behavior. "Blackening", and even the entire network's total storage share cannot be fully diluted, making the 51% attack difficult, and the majority of the mining revenue is concentrated in the hands of a small number of people, leading to a substantial decline in user storage requirements and pledge requirements, leading to LAMB gradually oversupply, which caused LAMB to fall sharply and depreciate against the US dollar.
4.5. Storj-Distributed storage protocol based on ETH network
(1) Project introduction
Storj is a distributed cloud storage protocol based on Ethereum, developed by the for-profit company Stroj Labs. It aims to use unused hard disks and bandwidth to allow any node on the P2P network to negotiate, transfer data, and verify the integrity of the data. Availability and retrieval, data retrieval, value transfer, storage nodes collect rent by providing storage space, while their counterparties pay for rent by renting disk space. At present, Storj's total global storage capacity has exceeded 150PB, the storage cost is $ 0.015 / GB per month, and the bandwidth cost for downloading 1GB is $ 0.05.
(2) Storj protocol architecture
Storj protocol includes file slice processing, Storj network, PoR certification mechanism, payment protocol, and broadcast protocol. For the same content sharing network, nodes are divided into storage nodes, satellite nodes and uplink nodes [10].
In terms of storage nodes, they earn Storj tokens by renting disks and providing bandwidth. If they do not pass the random review, the node will be removed from the storage node pool. They do not pay for the initial transmission of storage data (bandwidth entry). Nodes find that paying any fees effectively curbs the behavior of storage nodes deleting original storage data for more storage space (extending the duration of the availability of the content sharing network). The storage node will allow the administrator to configure the maximum disk space and bandwidth usage of each satellite within the last 30 days, and refuse to operate without a valid signature after tracking the above 2 indicators.
In terms of file slicing and encryption, for a specific file set bucket, each file can be retrieved according to a specific path. For each file, first divide it into multiple segments (the segment size is user-defined). If a segment is smaller than the size of its metadata, it saves storage space. This segment is called an inline segment. After encryption by the AES256-CTR algorithm, the encrypted hash string is split into multiple stripes, and each stripe performs erasure coding (by adjusting the proportion of the original data block and the check data block to improve the network node's (Fault-tolerant ability to improve data security), the erasure code segments of the same index are spliced to form a Piece. Finally, each Piece is distributed to different nodes in the shared network, and different file fragments are retrieved through pointers.
On the Storj network, in order to enable the leased nodes and storage nodes to negotiate and interact, Storj built the contract and negotiation system on the Kademlia distributed hash table to minimize the confirmation information required for transmission. By enhancing the core Kademlia function, pass Ping (confirm whether the node is online), STORE (store the hash value on DHT), FIND_NODE (find the node with storage space on DHT), FIND_VALUE (find the hash value on DHT) This kind of information promotes communication between different nodes. First, if a node wants to join a file sharing network, it must first create a public key private key pair. The Kademlia node ID must be the same as the public key hash string encrypted by SHA-256, so each node ID is also a valid Bitcoin address, and the information must be verified with a digital signature before sending the information.
In terms of consensus mechanism, Storj implements PoR (Certificate of Retrieval) in the form of "question-reply" to ensure that the remote host does store specific file fragments and verify the integrity and availability of the file. Storj uses the Merkel root and Merkel tree depth indicators to verify whether the number of elements in its leaf set is equal to the depth of the Merkel tree, and the hash value provided will recreate the stored root. By implementing a simple Tit-for-Tat model, if the storage node fails the audit or cannot prove that it still has data, the tenant node does not have to pay; if the tenant goes offline or fails to pay on time, the storage node can delete the data, and Find new contracts from others.
Figure 16: How Storj file storage works
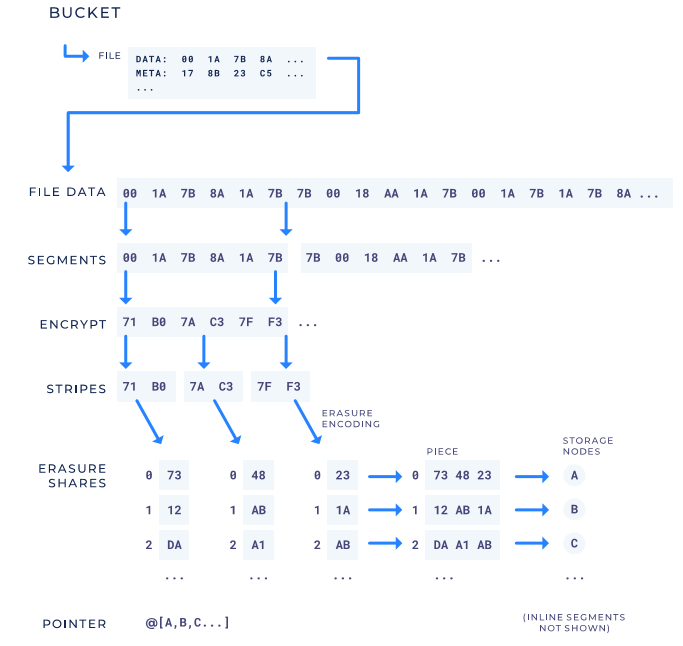
Data source: "Storj White Paper" Figure 17: Stroj node classification 
Data source: HashKey Hub
(3) Project evaluation Storj technically achieved compatibility with Amazon S3 and other storage formats through the Bridge client, and avoided large fluctuations in storage costs through the dollar-denominated standard, and its storage costs were far lower than centralized storage Platform, and optimized the retrieval mode through Kademlia algorithm, greatly reducing the redundancy of data and waste of resources.
But some places are still questionable. First of all, due to the high volatility of Storjcoin, the block rewards received by storage nodes fluctuated greatly, which could not guarantee more users to provide more storage space in the long run. Second, due to the lack of effective measures to extend the duration of file availability maintenance, this will not be conducive to the expansion of the shared network. Furthermore, with Filecoin joining the market, Storj does not have significant competitive advantages and financial advantages. More importantly, Storj essentially completes the docking of storage resources, lacks an effective content addressing method, is not conducive to file sharing (such as movies, audio, etc.), but is only suitable for large-scale data storage (such as monitoring data, transaction data Wait).
4.6. Sia-a variant application of BTC in decentralized storage
(1) Project introduction
Sia is a distributed cloud storage protocol that is developed and operated by Nebulous. It tends to compete with existing storage solutions on the P2P and 2B side. Sia supports the formation of contracts between peer nodes of the storage network and pricing for downloading specific storage content. It aims to let the leased nodes lease the appropriate storage space in a cheaper and faster way, and promote the leased nodes and leased nodes through Siacoin economic design. The two sides reached an agreement. At present, the total storage space capacity of Sia is only 2PB, the stored space is only 206TB, and the storage node is 333, and the cumulative total download is only 1.2MB.
(2) Project structure
In terms of transaction structure, Sia transactions include the protocol version number, Arbitrary Data (arbitrary data fields to facilitate data retrieval), miner rewards, Inputs (revenue funds), Outputs (expenditure funds), document contracts, storage certificates, digital signatures (all Inputs should be digitally signed) [11]. Sia completely avoids the script system by using the MN multi-signature scheme in all transactions, reducing complexity and the possibility of attacks. The input of each block header must come from the output of the previous block header, so the input of the block must be the hash value of the output of the previous block header, and the output contains its Merkle root; Siacoin's spending condition is "Time lock has exceeded And sufficient designated public keys to add their signatures ", the number of signatures, the public key group, and the time lock are written to the leaf nodes of the Merkle tree, and the Merkel root of the tree is used as the address sent by Siacoin, and the transaction parties can choose Disclose the number of public keys and the number of signatures.
In terms of file contracts, a file contract is a storage agreement between a storage node and its customers. The file is fragmented into multiple hashes and hashed to generate its Merkel root (the core of the contract), the root hash, and the file. The total size can be used to verify stored evidence. The contract further specifies duration, frequency of challenge and payment parameters ( rewards for valid proof, rewards for invalid or missing evidence, and maximum number of proofs that can be missed ). The challenge frequency specifies the number of submissions of the storage certificate. Submitting a valid certificate during the challenge period will trigger a transfer transaction; if no valid certificate is provided within the duration, the contract will be sent to the "missed certificate" address (effectively preventing DDOS attacks). The "maximum number of proofs that can be missed" in the payment parameters is a threshold. If the number of missed proofs exceeds this threshold, the contract is invalid.
As for the storage certificate, the storage certificate only needs the identity (hash value) and proof data of the contract. First, the original file fragments are stored in the leaf nodes of the Merkel tree. The generated hash root will be compared with the previously generated root hash. If the two are the same, it can be proven that these fragments are indeed derived from the original file. . By letting the client specify a high challenge frequency, Sia imposes a lot of punishment on the lost evidence, so as to prevent any attack below 50% of the entire network's total computing power, and curb private mining. On the other hand, because the user node has the right to reject any transaction, when a malicious miner extorts a high transaction fee in the name of "whether to store the storage certificate on the chain", the user can directly terminate the transaction.
(3) Project evaluation
The Sia protocol is essentially a variant application of BTC in decentralized storage, but its mechanism design is still questionable in some places. In terms of Siacoin's economy, the number of Siacoin issues is increasing, but its growth rate is decreasing (the initial block generates 300,000 Siacoin, and each subsequent block is reduced by 1 Siacoin until it is reduced to 30,000 blocks, on average 1 block is generated every 10 minutes), which leads to a larger depreciation with the increase in the number of Siacoin, leading to large fluctuations in its storage costs. For the mining system, with the devaluation and spamming of Siacoin, miners with strong computing power will have disproportionate advantages, and eventually the number of mining people will drop significantly, which is not conducive to motivating the participation of miners. Therefore, Sia is far lower than Storj in terms of storage scale and transaction efficiency, let alone compared with BitTorrent.
5 Prospects for Decentralized Storage
On the one hand, the storage costs of decentralized storage networks are highly volatile. For example, projects such as Sia, MaidSafe, and Lambda have large fluctuations in their tokens and the irrational design of the token issuance mechanism can easily lead to over-issuance of tokens, leading to a long-term downward trend in their token prices, which in turn leads to storage and retrieval costs Unstable, resulting in a high user churn rate. On the other hand, data retrieval is not free, making the fee structure unreasonable. Although the storage cost of a decentralized storage network is much lower than that of centralized storage, for example, Storj's storage cost is only $ 0.015 / GB per month, which is much lower than Amazon's $ 2.5 / GB per month. However, if you consider the retrieval cost or For the frequency of data retrieval and invocation, the cost of decentralized storage is likely to be higher than the cost of centralized storage.
(2) Short-term behavior of project parties caused by conflicts of multiple interests
In order to overcome the lack of scalability such as traditional unlicensed blockchains (such as BTC, ETH, and EOS), a considerable part of decentralized storage projects adopt a decentralized approach, such as the intermediation of Lambda in storage asset market makers Off-chain processing with off-chain Lambda DB and Filecoin retrieval protocols. However, the interests of the project party and the user are inconsistent in many cases, resulting in short-term behavior of the project party. The expansion of the storage network scale and the fairness of transactions are often contradictory.For example, the project side of Filecoin designed the probability of successful mining based on the proportion of effective storage to the total storage of the entire network in order to expand the storage scale of the entire network in the short term. The power of mining has weakened, and nodes with high storage space can obtain higher returns and returns than linear increments, and the project party itself may play a role with high storage space, distorting the values of decentralized storage projects.
(3) Dilemma in designing the inflation rate for token issuance
The business goal of a decentralized storage network is to attract more users to provide more storage space and maximize the utilization of storage space. The premise of achieving this goal is to ensure the high liquidity of the token and not to let its value. Stable, but this is often contradictory. If the inflation rate of token issuance is low, the issuance of tokens will decrease in a certain period of time in the future, it will easily cause the token to appreciate, and storage network participants tend to hoard tokens to achieve asset appreciation, which is not conducive to Maintaining the high liquidity of the storage market, the total storage capacity of the entire network will be suppressed; if the inflation rate of token issuance is high, the issuance of tokens will increase in a certain period in the future, which can easily cause tokens to exchange against fiat currencies ( (Usually the U.S. dollar) has shown a trend of depreciation for a long time, so the revenue generated by the miner's coinage transaction will be greatly reduced, resulting in the miner's investment in buying disks being higher than the revenue generated by providing storage space. Making ends meet, which leads to higher barriers to entry. Currently, projects such as MaidSafe, Storj, Sia, and Lambda are in a second dilemma.
(4) How to quickly dilute the concentration of total storage across the entire network
In the initial stage of decentralized storage projects, the total storage of the entire network will inevitably be concentrated in the hands of a few storage vendors, and most of them will participate as partners. Large-scale centralized storage of the entire network is prone to 51% attacks, regardless of whether the attacker is a single storage vendor or a mining pool, or even "collusion". As a result, the share of storage held by most home users is getting lower and lower, leading to the deterioration of the storage blockchain from "non-permissive" to "permissive", leading to a decline in demand for its tokens and a long-term depreciation trend. Significantly weakened, even the loss of large storage vendors.
5.2. Development Recommendations for Decentralized Storage
Aiming at the development bottleneck of decentralized storage in Section 5.1, we provide the following reference suggestions for the layout of future decentralized storage projects:
(1) The introduction of a stablecoin mechanism stabilizes fees;
(2) Search should be free of charge;
(3) When Hash encryption is used, the root hash value on the block header is highly correlated with the root hash value of the previous block header, so that other nodes in the shared network with specific storage content have a stronger incentive to verify their stored files. Completeness and availability;
(4) Design a reasonable consensus mechanism so that the probability of block generation is linearly and positively related to increasing the total effective storage;
(5) Reduce the barriers to entry for storage and allow home users to participate in the storage network as storage miners. Do not allow too much total network-wide storage to be concentrated in the hands of a few storage vendors. It is recommended to use absolute storage space. Values implement effective rewards rather than proportions.
references
[4] "Filecoin White Paper": https://filecoin.io/filecoin.pdf
[5] E. Adar and BA Huberman. Free riding on gnutella. First Monday, 5 (10), 2000
[6] "BitTorrent White Paper": https://dwz.cn/dKuhcIRR
[7] Bram Cohen. Incentives Build Robustness in BitTorrent. [email protected]. 2003
[8] "Lambda Technical White Paper": https://dwz.cn/yktCaGCp
[9] Lambda Economic White Paper: https://dwz.cn/ftm1Wl6d
[10] "Storj V3 White Paper": https://storj.io/storj.pdf
[11] "Sia White Paper": https://sia.tech/sia.pdf
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Can Andrew Yang's White House Crypto Party be held successfully in 2020?
- Comment: Regulatory sandbox and blockchain coexist and help innovation
- Supervision stick, giant "encirclement and suppression", how does the crypto industry redeem itself?
- Interviewed 800 crypto traders in 75 countries around the world. What did they find?
- Ethereum implements Muir Glacier upgrade, V god praises Sparkpool mining pool
- A New Decade of Digital Currency Trading: Looking at the Past to See the Future
- Dry goods | Can quantum computers really destroy blockchain networks?