Artificial Intelligence and Work Automation
AI and Work AutomationAlmost everyone in the tech industry agrees that generative AI, large language models, and ChatGPT represent a generational shift in what we can do with software and what we can automate with software. There is less consensus on other issues related to large language models— in fact, we are still researching and debating what the focus of those debates should be— but everyone agrees that there will be more automation, and new types of automation. And automation means jobs, and people.
The pace at which this is happening is also incredibly fast: just six months after its launch, ChatGPT already has (apparently) over 100 million users, and data from Productiv suggests that it is already one of the top ten “shadow IT” apps, meaning apps that employees use without formal approval. So, how many jobs will this take away, how fast, and will there be new jobs to replace them?
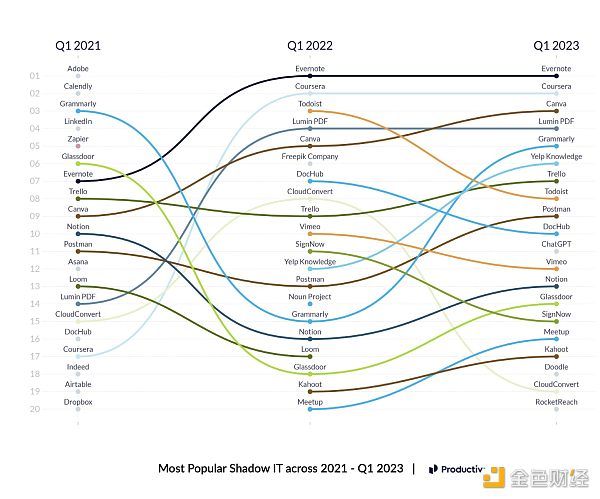
Most popular shadow IT apps in recent years
- Jay Chou’s ‘Fantasy Music Universe’ is here. Would you buy the 30 yuan digital collectible key?
- Bankless Why does the US Treasury Bond Trigger the Widespread Adoption of RWA?
- GameFi caught in controversy Is it a bubble that will eventually burst or a completely new game mode?
First of all, it is important to remember that the process of job automation has been going on for 200 years. Every time we go through a wave of automation, a whole category of jobs disappears, but new categories of jobs are also created. There will be pain and dislocation in this process, and sometimes new jobs will be allocated to different people in different places, but over time, the total number of jobs does not decrease, and we become more prosperous.
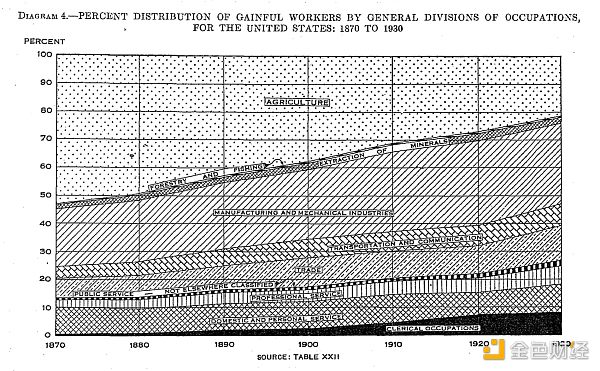
US Census by industry, 1870-1930
When this happens in your generation, it is natural to worry that there will be no new jobs this time. We can see some jobs disappearing, but we cannot predict what the new jobs will be, and often they don’t exist yet. Based on experience, we know (or should know) that new jobs have always appeared in the past, and these jobs are also unpredictable: in 1800, no one predicted that a million Americans would work in the “railroads” in 1900, and in 1900, no one foresaw that “video post-production” or “software engineer” would become job categories. But just because it has always been this way, it is not enough to believe that it will still be the case now. How do you know this time will be the same as before? Will it be different this time?
At this point, any first-year economics student will tell us that answering this question in this way falls into the “lump of labor” fallacy.
The lump of labor fallacy is the mistaken belief that the total amount of work to be done in society is fixed, and if machines take on some of the work, then there will be less work left for humans. However, if it becomes cheaper to manufacture a pair of shoes with machines, then shoes will become cheaper, and more people will be able to afford them, leaving them with more money to spend on other things, and we will find that we need or want new things or new jobs. Efficiency improvements are not limited to shoes: generally, they spread outward through the economy, creating new prosperity and new job opportunities. So, while we don’t know what the new jobs will be, we know this pattern, which not only explains why new jobs will always appear, but also why it is inherent in this process. Don’t worry about artificial intelligence!
I believe that the fundamental challenge facing this model today is the claim that for the past 200 years, automation has been enhancing human capabilities.

“Barge Haulers on the Volga,” Ilya Repin, 1870-73. (Note the steamboat with smoke appearing on the right horizon.)
As humans, we started as laboring beasts and then progressed upwards: first automating our legs, then our arms, then our fingers, and now our brains. We initially engaged in farm work, then blue-collar work, then white-collar work, and now we have even automated white-collar work. There is nothing left to automate. Factories have been replaced by call centers, but if we also automate call centers, what is left for humans to do?
To address this issue, I believe it would be helpful to understand another segment of economic and technological history: Jevons’ Paradox.
In the 19th century, the British Navy relied on coal to power their ships. At that time, Britain had abundant coal supplies (it was the Saudi Arabia of the steam age), but people were concerned about what would happen when the coal ran out. Well, engineers said, don’t worry because the efficiency of steam engines will increase, so we will use less coal. But Jevons said, no: if we make steam engines more efficient, their operating costs will be lower, and we will use more steam engines and employ them for new and different things, so we will use more coal. Innovation can be linked to price elasticity.
For 150 years, we have been applying Jevons’ Paradox to white-collar work.

Typewriter replacing manual copying

Adding machine replacing manual bookkeeping
The future of work that doesn’t exist yet is hard to imagine, but it is also difficult to imagine that some past jobs have already been replaced by automation. In Gogol’s writings, employees in the 1830s spent their entire careers copying documents, one by one, entirely by hand. They were human photocopy machines. By the 1880s, typewriters could produce clear and readable text at twice the speed, and duplicating machines could provide six free copies. Typewriters meant that the output of a single employee could increase by more than 10 times. Decades later, adding machines made by companies like Burroughs did the same for bookkeeping and accounting: you no longer had to pick up a pen to do addition, but could use a machine, saving 80% of the time and avoiding mistakes.
What impact does this have on the employment of clerks? The result is that more clerks are employed in society. Automation combined with Jevons’ Paradox means that more job opportunities are created.
If a machine can perform the work of 10 clerks in the past, then you may reduce the number of clerks, but you may also use these people to do more things. Jevons tells us that if something becomes cheaper and more efficient, you may do more of it – you may do more analysis or manage more inventory. You may build a different and more efficient enterprise, which is possible because you can automate business management with typewriters and adding machines.
History is constantly repeating this process. This is CC Baxter played by Jack Lemmon in the movie “The Apartment” in 1960. He uses Friden’s electronic adding machine, which was exciting fifty years ago when adding machines had just appeared.

Electronic Adding Machine
In this scene, each person is a cell in a spreadsheet, and the entire building is a spreadsheet. Once a week, someone on the roof presses F9, and they start recalculating. But they already have computers, and by 1965 or 1970, they bought a mainframe and abandoned all the adding machines. Did the white-collar jobs collapse? Or, as IBM promoted, did computers add an extra 150 engineers to you? What impact did the PC revolution and the accounting department in a small box have on accounting 25 years later?

IBM claims that having a mainframe is equivalent to having an additional 150 engineers

Advertisement for desktop accounting system: One small box replaces an accounting department
Dan Bricklin invented the computer spreadsheet in 1979: before that, “spreadsheets” were paper-based (you can still buy them on Amazon). He tells some interesting stories about the early use of spreadsheets: “People would tell me, ‘I did all this work, and my colleagues think I’m great. But I’m actually lazy because I only spent an hour doing those things, and the rest of the time I’m resting. Others think I’m a genius, but I’m just using this tool.”
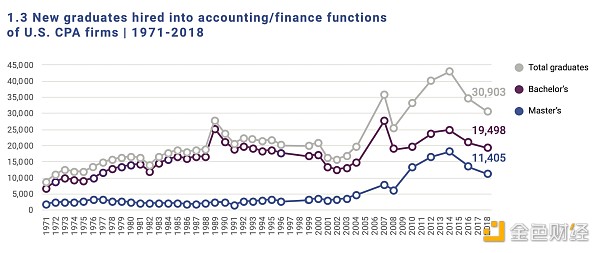
After Excel and PCs appeared, the number of accounting positions increased instead of decreased
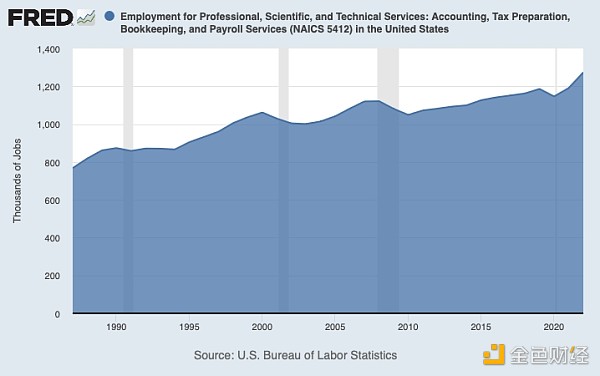
Accounting, bookkeeping, payroll services, and tax services related job positions in the United States from 1990 to 2020
So, what impact did Excel and PCs have on accounting positions? The number of accounting positions increased.
Will the spreadsheet allow you to take a break 40 years later? Actually, no.
You may not believe it, but before the advent of spreadsheets, investment bankers did work long hours. Thanks to Excel, Goldman Sachs employees were able to complete all their work and leave the office at 3 p.m. on Fridays. Now, with large language models, they only need to work one day a week!
New technologies often make things cheaper and easier, but this may mean that you can do the same things with fewer people, or you can do more with the same people. It also often means that you change what you do. At first, we made new tools fit into old ways of working, but over time, we began to change the way we work to fit the tool. When the company where CC Baxter worked purchased mainframe computers, they initially automated existing work processes, but over time, new business operations became possible.
Therefore, all of this implies that by default, we should expect large language models to disrupt, replace, create, accelerate, and increase employment opportunities just like SAP, Excel, mainframes, or typewriters. It’s just more automation. Machines can enable one person to do ten times the work, but you still need that person.
For this view, I believe there are two counterarguments.
The first is that maybe this is indeed more similar to the changes we have seen from the internet, personal computers, or PCs, and perhaps it will not have a long-term impact on net employment, but this time it will happen faster, so the pain will be greater and the adjustment will be more difficult.
The development speed of LLM and ChatGPT is definitely much faster than that of the iPhone, the internet, and even personal computers. The Apple II was launched in 1977, the IBM PC was launched in 1981, and the Mac was launched in 1984, but it wasn’t until the early 1990s that the number of PC users reached 100 million. However, just six months after its launch, ChatGPT already had one billion users. You don’t need to wait for telecom companies to build broadband networks or for consumers to buy new devices. Generative artificial intelligence is built on a whole technology stack that has been built over the past decade: cloud computing, distributed computing, and numerous machine learning technologies. For users, it’s just a website.
If you think again about the meaning of these charts from Productiv and Okta (using different methods), your expectations may be different. Both companies report that their typical customers now have hundreds of different software applications, and enterprise customers have nearly 500 software applications.
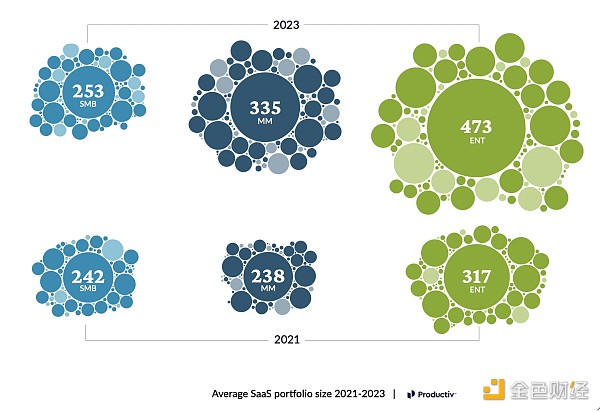
The number of SaaS applications owned by small and medium-sized enterprises and large enterprises continues to grow.
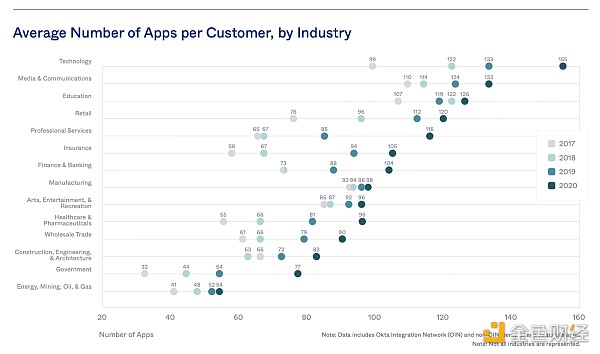
The average number of apps in different industries is also growing (per customer).
However, the adoption rate of cloud computing by enterprises accounts for only one-fourth of the workflow.
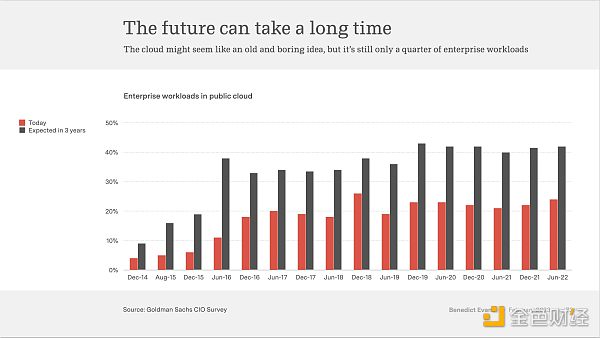
The path to cloudification is still long.
What does this mean for the generation of artificial intelligence in the workplace? Regardless of what you think will happen, the time required will be measured in years, not weeks.
The tools people use to do their work, and the tasks that may now have a layer of new automation to share the workload, are very complex and specialized, integrating a large amount of work and institutional knowledge. Many people are trying out ChatGPT to see what it can do. Maybe you are one of them. But that doesn’t mean ChatGPT has replaced their existing workflows, replacing or automating any of these tools and tasks is not a small matter.
There is a huge difference between a stunning demonstration of transformative technology and something that others can use in a large and complex company. When you visit a law firm, it is rarely just to sell a GCP (Google Cloud Platform) translation or sentiment analysis API key: you need to wrap it up in control, security, version control, management, customer permissions, and a whole host of other things that only legal software companies know about (many machine learning companies have recognized this in the past decade). Companies can’t just buy “technology”. Everlaw doesn’t sell translation, and People.ai doesn’t sell sentiment analysis—they sell tools and products, and artificial intelligence is usually just a part of it. I don’t think text prompts, “start” buttons, black boxes, and general text generation engines can be products. Products take time.
At the same time, it takes time to purchase and manage large and complex tools, even if these tools have been developed and found product-market fit. One of the fundamental challenges of starting an enterprise software startup is that the funding cycle for startups is 18 months, while the decision cycle for many enterprises is 18 months. SaaS itself speeds up this cycle because you don’t need a deployment plan to enter the enterprise data center, but you still need to purchase, integrate, and train, and there are good reasons for companies with millions of customers and tens or hundreds of thousands of employees not to make sudden changes. It takes time to get to the future, and the world outside of Silicon Valley is complex.
The second counter-argument is that ChatGPT and the LLM paradigm shift are part of a shift in abstraction layer: it looks like a more general technology. Indeed, that’s why it’s exciting. They tell us that it can answer any question. So, you can look at the 473 enterprise SaaS applications in that picture, and then say that ChatGPT will disrupt everything and fold many vertical applications into one prompt box. This means it will evolve faster and be more automated.
I think this is a misunderstanding of the issue. If a law firm partner wants a first draft of a document, their requirements for parameter adjustments will be completely different from those of a salesperson handling claims for an insurance company. They may use different training sets and, of course, a bunch of different tools. Excel is also a “general purpose” tool, as is SQL, but how many different types of “databases” are there? This is one of the reasons why I think the future of large language models will shift from prompts to GUIs and buttons – I think “prompt engineering” and “natural language” are contradictory. But regardless of which one, even if you can run everything as a thin layer of encapsulation on top of a large base model (and there is no consensus or clarity on this point yet), these encapsulations also take time.
In fact, although some may think that large language models will encompass many applications along one axis, I believe that as startups peel off more use cases from Word, Salesforce, and SAP, they may also unleash a wave of new unbundling on other axes. At the same time, they will establish a bunch of larger companies by solving problems that no one realized before a large language model gave them the capability to solve. After all, this process explains why large companies now have 400 SaaS applications.
Of course, the more fundamental problem is error rate. ChatGPT can answer “any question,” but the answers may be wrong. It is called an illusion, fabrication, lying, or nonsense – the “overconfident college student” problem. But I think this kind of thinking framework is not helpful: I think the best way to understand this is that when you enter certain content into the prompt box, there is actually no requirement for it to answer the question. Instead, you want to ask “what kind of answers people might give to such questions?” You ask it to match a pattern.
So if I ask ChatGPT4 to write my own biography and then ask it, it will give different answers. It will say that I attended Cambridge, Oxford, or the London School of Economics (LSE); my first job was in stock research, consulting, or financial news. These are always correct patterns: the correct type of university and the correct type of job (it has never said that I attended MIT and then my first job was in catering management). For the question of “what kind of degree someone like me might get and what kind of job they might do,” it gives 100% correct answers. For this question, it is not doing a database query: it is creating a pattern.
This image was generated by MidJourney, and you could generate similar content. The prompt is “a photo of advertising professionals discussing creativity on a workshop stage at the Cannes International Creativity Festival, by the beach.”

The image almost perfectly matches the pattern – it looks like a beach in Cannes, the clothing of these people resembles advertising professionals, and even the hairstyles are appropriate. But it doesn’t know anything, so it doesn’t know that people don’t have three legs, it just knows that it’s unlikely. This is not “lying” or “fabricating” – it is matching a pattern, just not perfectly.
No matter what you call it, if you don’t understand this point, you will run into trouble, just like this unfortunate lawyer did. He didn’t understand that when he asked for precedents, he was actually asking for something that looks like a precedent. He got something that looked like a precedent, but it wasn’t a database.
If you do understand this point, then you have to ask a question: what is the use of an LLM? What is the use of automating undergraduate or intern work (which can be repetitive patterns you might want to check)? The last wave of machine learning gave you countless interns who can read anything for you, but you have to check. Now we have countless interns who can write anything for you, but you still have to check. So what’s the use of this infinite number of interns? Ask Dan Bricklin – we’re back to Jevons’ paradox.
Obviously, the topic leads to General Artificial Intelligence (AGI). The real fundamental rebuttal to everything I just said is to ask, what if we had a system with zero error rate, no illusions, and could actually do anything that humans can do? What would happen then? If we had that, you might not need a machine that can do the work of ten regular accountants who know how to use Excel – you might just need that machine. This time, things might really be different. The previous waves of automation meant that one person could do more, but now you don’t need that person anymore.
However, as with many AGI questions, if you’re not careful, this could become a vicious cycle. “If we have a machine that can do anything a human can do, without any of these restrictions, will it do everything a human can do, without these restrictions?”
Well, indeed, if that’s the case, the problem we might encounter could be even bigger than the middle-class employment problem. But are we already close to that? Perhaps even if you spend weeks carefully watching three-hour YouTube videos of computer scientists arguing about this question, the conclusion you’ll come to is that they don’t really know either. You might also think that this magical software will change everything and surpass the complexity of real people, real companies, and the real economy, and can now be deployed in weeks instead of years. This sounds like classic technological determinism, but it has turned from utopia into dystopia.
However, as an analyst, I tend to lean towards Hume’s empiricism rather than Descartes’ philosophy – I can only analyze what we can know. We don’t have general artificial intelligence yet, and without it, we will only have another wave of automation, and we seem to have no a priori reason to explain why this wave will necessarily be more painful than all the previous ones.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 10 Tips for Web3 Entrepreneurs
- Notice on the Issuance of the Three-Year Action Plan for the Innovative Development of the Metaverse Industry (2023-2025)
- Founder Team Explains EigenDA Bringing Scalable Data Availability to Rollups
- Three executives resign, Binance faces challenges.
- Bankless Partner David Burning Man Exploration – Unstoppable DAO Experiment and the World’s Largest Networked Nation
- Will Micro-Rollup be the next wave when applications become Rollups?
- One of the biggest competitors of Maestro and Unibot, how does Banana Gun perform in terms of data?