How does the Interplanetary File System (IPFS) decentralize the network?
Source: https://www.maketecheasier.com/how-interplanetary-file-system-decentralize-the-web/
Author: Andrew Braun
Translation: Interstellar

- Getting Started with Blockchain | 42 Most Frequently Asked Questions and Answers About Blockchain
- Bitcoin cash double payment statistics triggers zero confirmation dispute
- Babbitt Column | Analysis of different types of token supervision
Suppose you are downloading the latest memes and you patiently wait for the download to complete. Memes are of course fire, so you send a link to your friends. They get the files from your phone and start sharing with friends. At this point, memes exist on dozens of devices, so when new users get a link, they actually end up connecting to several other people and getting some snippets from each, making the download almost instant of. Thanks to the interstellar file system, a very real, easy-to-use system could become the key to our faster and more democratic Internet. As mentioned above, the basic idea is that the user equipment will store, index, and deliver data that currently resides on a centralized server. If this sounds a bit like cryptocurrency, then you're right-Juan Benet, the person behind the project, described IPFS as "in a sense, done on the site … the impact of Bitcoin on money."
What is the interstellar file system?
If you know how BitTorrent or any other P2P (peer-to-peer) technology works, then you will be most of the way to understand what IPFS is doing. It sends files (including the HTML, CSS, and JavaScript files that make up most websites) and files between user devices, just as if you were perfectly legal to torrent music in the public domain.
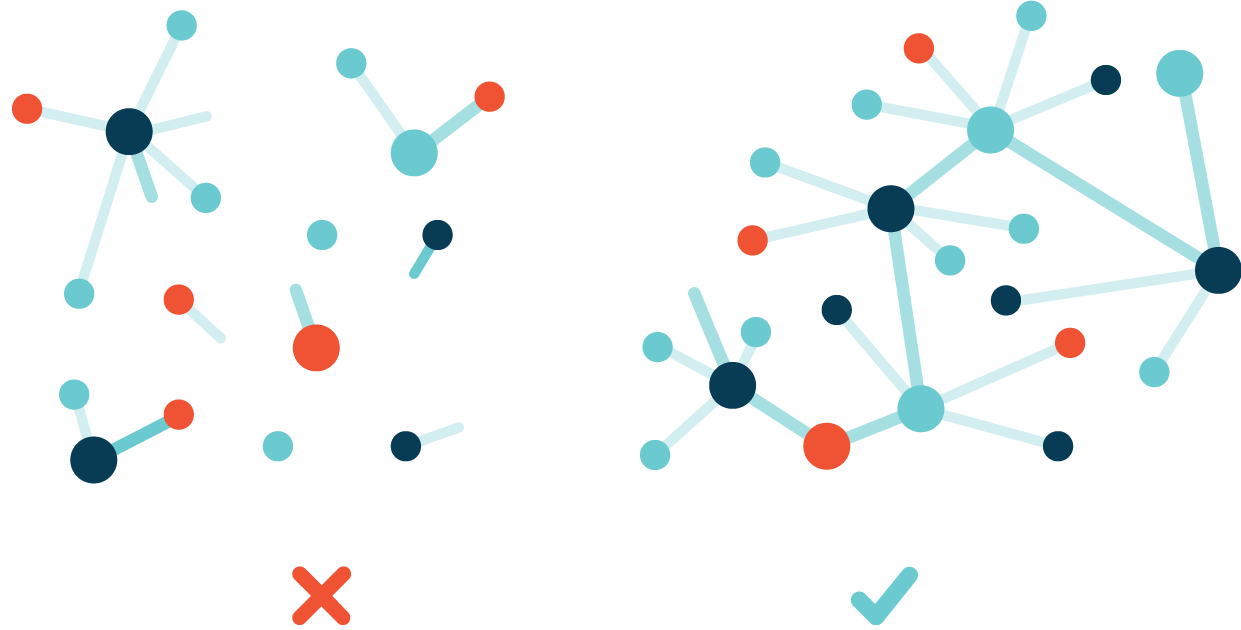 This means that you don't need to check if the server is connected to the site to see it, but just to see if someone nearby is storing the page (or part of it) and you are connected to the page. After downloading the page, your device will also store it for a while so that others can get it (or part of it) from you. This may sound complicated, but it is actually much more efficient than our current system that uses the HTTP protocol to send data through a single server-client pipeline.
This means that you don't need to check if the server is connected to the site to see it, but just to see if someone nearby is storing the page (or part of it) and you are connected to the page. After downloading the page, your device will also store it for a while so that others can get it (or part of it) from you. This may sound complicated, but it is actually much more efficient than our current system that uses the HTTP protocol to send data through a single server-client pipeline.
Why is it great?
Compared with the traditional Web, IPFS has some great advantages:
- Faster and more efficient content delivery: You can download files from brochures located closer to you to minimize travel time and bandwidth.
- Decentralized: No single source can control or access the data.

- Information retention: Since there is no single server that stores all data, it cannot disappear and take away all your GeoCities websites.
- Faster, more stable connections in poorly connected areas: As long as the content you want is downloaded to an accessible location, there is actually no need for long-distance connections, which is useful or sporadic for sporadic areas Connection.
- Resistance of the censorship system: not yet perfect, but better than the centralized model.
How it works: short version
Now anyone can use the IPFS network because it is very easy to use. This is what happened:

- When you add a file to IPFS, the file is divided into multiple blocks, each block is run through an algorithm and assigned a unique ID. The entire file including these block IDs is also assigned an ID. Initially, your machine will be the only place where people can get files, but other nodes (machines) can also extract and distribute it.
- If the network finds that some of your data is the same as what is already stored in it, it uses that data only, without adding a copy. Suppose you want to host the "Deluxe Edition" of a recorded album. Ten of the songs are the same as the album you have already recorded, but two of them are new, so when you add them to IPFS, the system will identify duplicate tracks and use the existing ID, adding only the new ID to two New song.
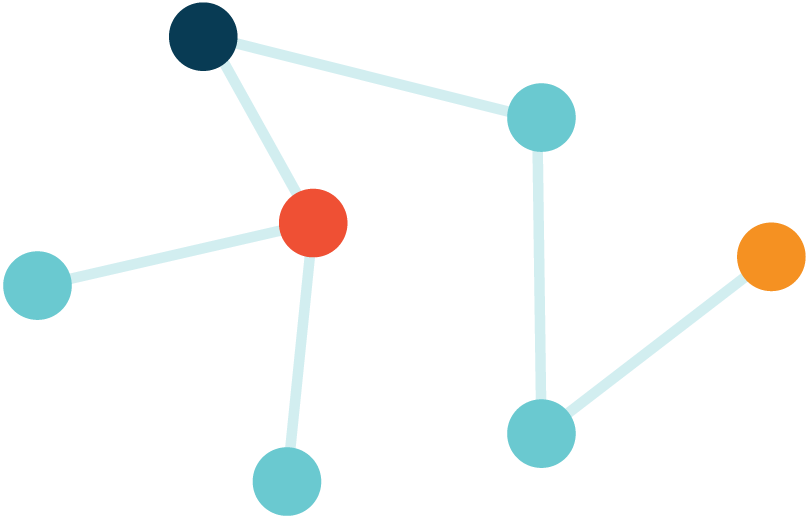
- Each node on the network stores some data (probably the data that the node wants to distribute and the data that the node has recently opened) and a part of the index, which can help people find where to find content on the network.
- If you want to open a file, ask the network to find its ID and connect you to anyone who owns the file. The naming system named IPNS helps translate human-readable names into machine-readable IDs that the system will search.
Simpler translation: IPFS names each piece of data, lists where it is stored at any given time, and helps devices send data directly to each other.
Working principle: technical version
IPFS has three main functions: content addressing provides identity for data, Merkle-DAG provides structure for data, and distributed hash tables tell you where to find it.
Content addressing: what, where not
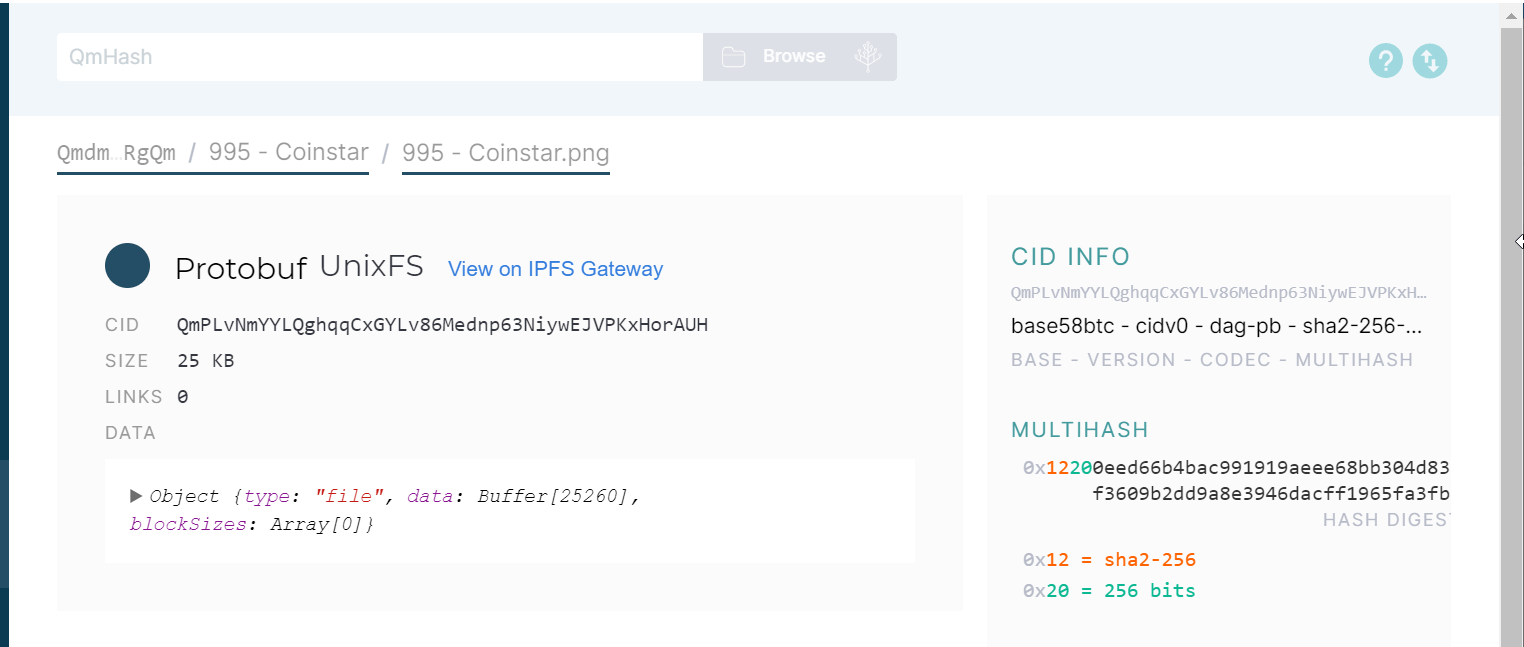
Most of our current content has location-based addresses (C: / Users / Username / Documents, 192.124.249.3, etc.) that tell us where to find the data. In systems with decentralized content, this does not work because the content can be stored almost anywhere, so systems such as IPFS and BitTorrent use "content addressing" instead.
A content addressing system works by running a block of data through an algorithm, which assigns a unique ID, or hash. Each identical copy of the file will have the same ID, which means that when IPFS looks for it, it can find every instance stored on the network.
Merkle-DAG: everything has a CID and they are all connected
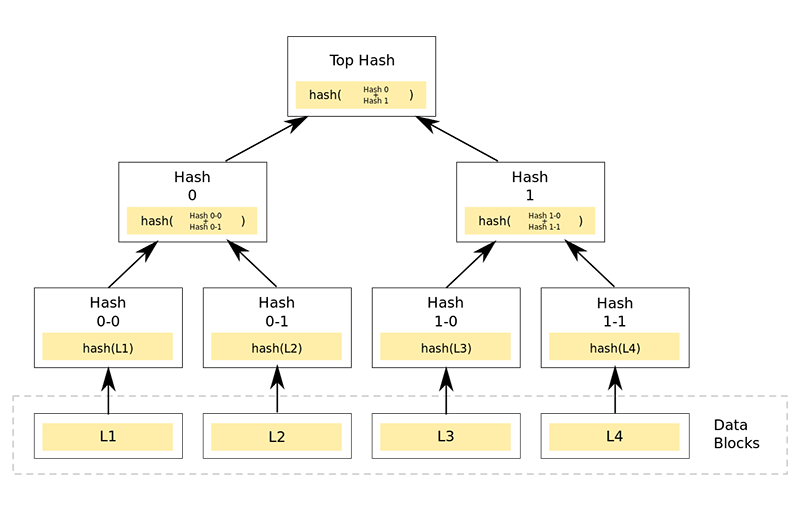
Although it sounds like a German political party, Merkle-DAG (Directed Acyclic Graph) is actually a way to organize data. In this system, each piece of data has its own content ID (CID): folder, file, data block inside the file-including everything. This means that files can be split into different parts, authenticated and reassembled.
The IPFS document describes it as "all the way" because everything can be broken down into a collection of data that CID can recognize. A folder's CID directs you to the collection of files and folder CIDs, and then its CID directs you to other CIDs (also with their own CID) that represent other content. Any change in any file will cause its hash value to change as well as the hash value of its folder.
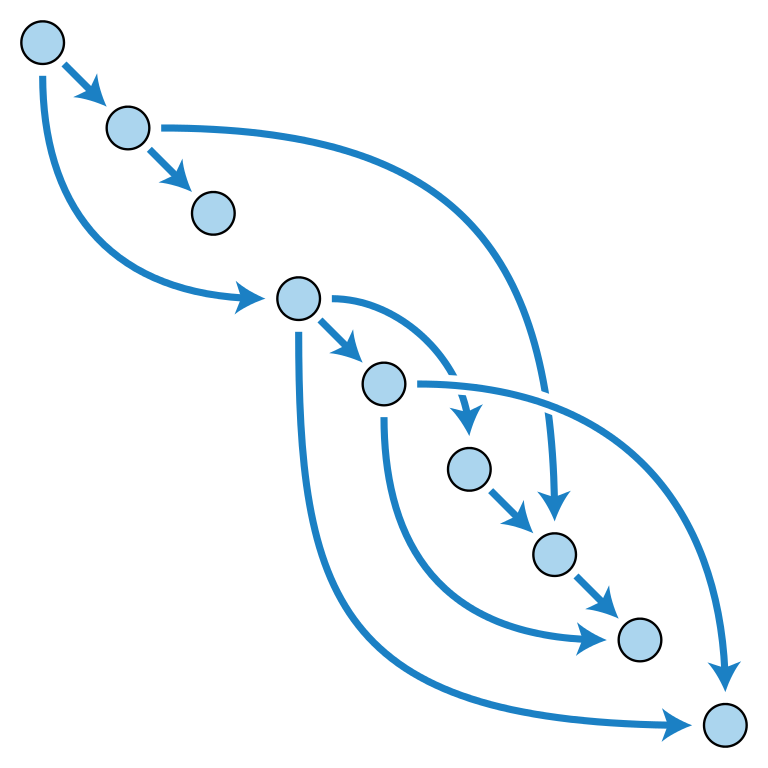
Data doesn't actually exist here-it just tells you where to find all the data and how to put it all together once you have them. Merkle-DAG essentially provides structure for all these IDs, very similar to the file system on your computer.
Distributed hash tables: how IPFS locates content
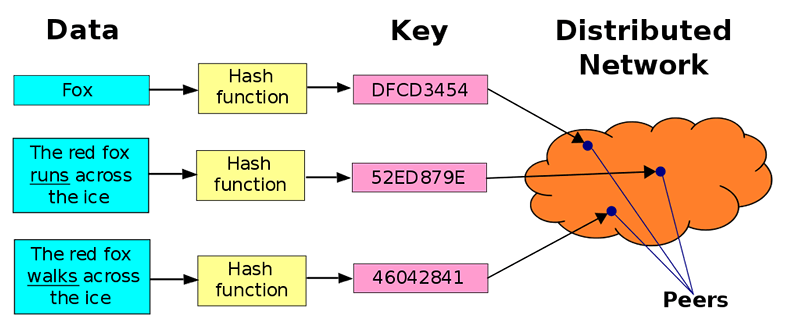
So how do we find who has the data we want? Basically, there is a large database that matches the content ID to the location of the computer hosting the content, and the database itself is assigned by everyone in the network. When you request something expressed as a CID, the computer searches the CID until it finds a list of people who have that ID. Your computer will then connect with these people, download the required files, and assemble them. That's a distributed hash table -essentially a big list of who owns what.
IPFS is cool, but will it succeed?
IPFS started in 2015 and has made great strides since then. Dozens of applications and websites (including decentralized YouTube or DTube ), blockchain file storage systems ( Filecoin ), and GeoCities alternatives ( Neocities ) have been built on it . It successfully achieves the perfect combination of decentralization and user-friendliness, which may be why it is the first choice for projects that want to enter decentralization, such as Sociall (decentralized social network) and Brave .
Cloudflare's IPFS gateway is very popular, and the use of the network has been getting easier and easier. All you have to do is download the program and install the browser extension . Of course, there is controversy as to whether it is really the best solution-it is far from the only project with the same vision-but it does not show any signs of slowing down. Even if it doesn't completely replace HTTP, it certainly seems to be part of the next version of the Internet.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- A picture to understand the blockchain App security system
- "Farewell Hayek": Conjecture on the Development Space of STO in China
- How to seize the breakthrough of the blockchain overpass? Experts and experienced practitioners give answers
- Hainan sets up digital asset trading test area, STO falling from the altar may usher in the biggest turning point
- Chinese Blockchain Enterprises Capture US Exchanges?
- The truth about blockchain employment: higher thresholds, fewer job applicants, high salaries or history?
- Beginner's Guide: Five dimensions to take you through the chaos of the blockchain






