How to Trust AI: What Ideas Does Zero-Knowledge Machine Learning (ZKML) Offer?
Trusting AI: The Role of Zero-Knowledge Machine Learning (ZKML)Abstract
As AI evolves at an unimaginable pace, concerns about trust in AI will also arise as another “blade” of the AI sword. First, there is privacy: How can humans trust AI from the perspective of data privacy in the AI era? Perhaps transparency of AI models is even more concerning: Emergence of large-scale language models is no different from an opaque technological “black box” that humans cannot see through, and general users may not understand how the model is running or how the running results are obtained – more troublesome, as a user may not know if the AI model provided by the service provider is running as promised. Especially in the application of AI algorithms and models in some sensitive data, such as medical, financial, internet applications, etc., whether the AI model has bias (or even malicious intent), or whether the service provider is running the model (and relevant parameters) accurately and as promised, becomes the most concerned issue for users. Zero-knowledge proof technology has targeted solutions in this area, so zero-knowledge machine learning (ZKML) has become the latest emerging development direction.
Considering the integrity of computation, heuristic optimization, and privacy, zero-knowledge proof and AI are combined to give birth to zero-knowledge machine learning (Zero-Knowledge Machine Learning, ZKML). As AI-generated content gets closer and closer to content generated by humans, the technical features of zero-knowledge proof can help us determine that specific content is generated by a specific model. For privacy protection, zero-knowledge proof technology is particularly important, that is, proof and verification can be completed without revealing user data input or model specific details.
Five ways zero-knowledge proof is applied to machine learning: computation integrity, model integrity, verification, distributed training, and identity verification. Recently, the rapid development of large-scale language models (LLM) has shown that these models are becoming more and more intelligent, and these models have perfected the interface between algorithms and humans: language. The trend of general artificial intelligence (AGI) is unstoppable, but based on the current model training results, AI can perfectly mimic high-capacity humans in digital interactions – and in fast evolution, it can reach beyond human levels at an unimaginable rate, making humans have to marvel at this evolutionary speed and even produce concerns about being rapidly replaced by AI.
- Founder of Aave: “DeFi frontend applications” such as payments will drive widespread adoption of Web3
- Will Perp DEX lead the next bull market? Comparative analysis of the fee structure, indicators, and growth potential of six protocols.
- Gemini: Customers affected by Voyager’s bankruptcy can file claims through opening an account on Gemini
Community developers used ZK-SNARKs to verify Twitter’s recommendation function, which is enlightening. Twitter’s “For You” recommendation function uses an AI recommendation algorithm to distill about 500 million tweets posted every day into a few popular tweets, which are finally displayed on the user’s homepage timeline. At the end of March 2023, Twitter open-sourced the algorithm, but because the model details were not disclosed, users still cannot verify whether the algorithm is accurate and complete. Community developers such as Daniel Kang use cryptographic tool ZK-SNARKs to check whether the Twitter recommendation algorithm is correct and complete without disclosing the algorithm details—this is precisely the most attractive feature of zero-knowledge proof, that is, to prove the credibility of the information without revealing any specific information about the object (zero knowledge). Ideally, Twitter can use ZK-SNARKS to publish the proof of its ranking model—that is, to prove that when the model is applied to specific users and tweets, it will produce specific final output rankings. This proof is the basis for the credibility of the model: users can verify whether the calculation of the model algorithm is executed according to the commitment— or entrust it to a third party for audit. All of this is based on not disclosing the details of the model parameter weights. That is to say, using the officially published model proof, users have doubts about specific tweets, and use this proof to verify whether specific tweets are honestly running as promised by the model.

1. Core views
As AI evolves at an unimaginable speed, it will inevitably cause concerns about the other “blade” of AI sword—trust. First of all, privacy: In the AI era, how can humans trust AI from the perspective of privacy? Perhaps the transparency of the AI model is the more worrying key: the emergence ability of large-scale language models, for humans, is like a technology “black box” that cannot be seen through, and ordinary users cannot understand how the model works or how the results are obtained (the model itself is full of difficult-to-understand or predictability). More troublesome is that as a user, you may not know whether the AI model provided by the service provider runs as promised. Especially when applying AI algorithms and models to sensitive data such as medical, financial, and Internet applications, whether the AI model has bias (or even malicious orientation), or whether the service provider runs the model (and related parameters) as accurately and correctly as promised becomes the most concerned issue for users.
Zero-knowledge proof technology has targeted solutions in this area, making zero-knowledge machine learning (ZKML) the latest emerging development direction. This article explores the characteristics, potential application scenarios, and some inspiring cases of ZKML technology, and studies the development direction and possible industrial impact of ZKML.
2. The “other edge” of the AI sword: how to trust AI?
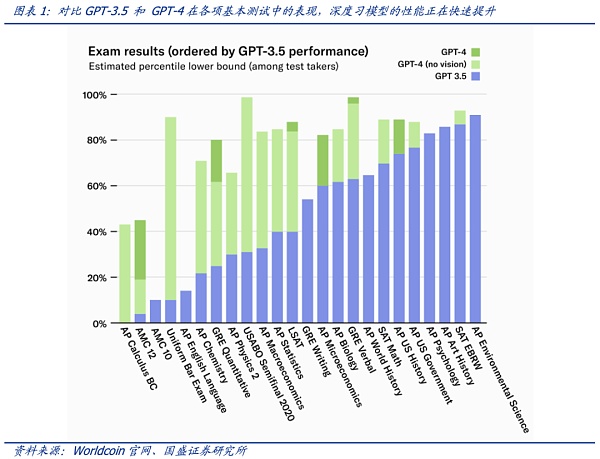
The ability of artificial intelligence is rapidly approaching that of humans and has already surpassed humans in many niche areas. The recent rapid development of large language models (LLMs) shows that these models are becoming more and more intelligent, perfecting the algorithmic interface between humans and language. The trend of general artificial intelligence (AGI) is unstoppable, but based on the current results of model training, AI can perfectly imitate high-ability humans in digital interactions-and achieve levels beyond human capabilities at an unimaginable speed in rapid evolution. Language models have recently made significant progress, with products represented by ChatGPT performing stunningly, reaching more than 20% of human ability in most routine evaluations. When comparing GPT-3.5 and GPT-4, which are only a few months apart, humans can’t help but marvel at this rate of evolution. But on the other hand, there are concerns about the loss of control over AI capabilities.
First of all, there is the issue of privacy. In the AI era, with the development of technologies such as facial recognition, users are always worried about the risk of data leakage while experiencing AI services. This has brought certain obstacles to the promotion and development of AI-how to trust AI from the perspective of privacy?
Perhaps the transparency of AI models is the more worrying key. Similar to the emergence of large-scale language models, for humans, it is like an opaque technological “black box”, and general users cannot understand how the model works or how the results are obtained (the model itself is full of difficult to understand or predict capabilities)-more troublesome is that as a user, you may not know whether the AI model provided by the service provider is running as promised. Especially when applying AI algorithms and models to sensitive data, such as medical, financial, and internet applications, whether AI models have biases (or even malicious intent), or whether service providers operate models (and related parameters) accurately and as promised, becomes the user’s most concerned issue. For example, whether social application platforms use “one-size-fits-all” algorithms for related recommendations? Is the recommendation from the AI algorithm of the financial service provider as accurate and complete as promised? Are there unnecessary expenses in the AI-recommended medical service plan? Will service providers accept audits of AI models?
Simply put, on the one hand, users do not know the true situation of the AI model provided by the service provider, and they are very concerned that the model is not “impartial.” AI models are considered to add elements of bias or other directions, which will bring unknown losses or negative impacts to users.
On the other hand, the self-evolution speed of AI seems to be increasingly difficult to predict. The increasingly powerful AI algorithm models seem to be more and more beyond the possibility of human control, so the issue of trust becomes another “blade” of this sword of AI.
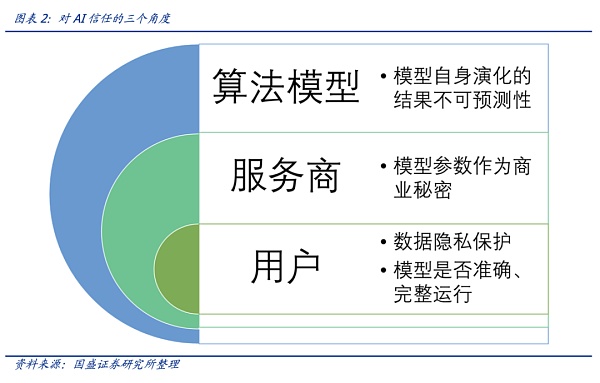
It is necessary to establish users’ trust in AI from the perspectives of data privacy, model transparency, and model controllability. Users need to worry about privacy protection and whether the algorithm model runs accurately and completely as promised. However, this is not easy. As far as model transparency is concerned, model providers have concerns about auditing and supervision of models based on commercial secrets and other factors. On the other hand, the evolution of algorithm models themselves is not easy to control, and this uncontrollability also needs to be taken into account.
From the perspective of user data privacy protection, our previous report, such as “AI and Data Elements Driven by Web3.0: Openness, Security and Privacy,” has also conducted extensive research. Some applications of Web3.0 are highly inspiring in this regard—namely, AI model training is carried out on the premise of complete user data rights confirmation and data privacy protection.
However, the market is still impressed by the stunning performance of large models such as Chatgpt, and has not yet considered the privacy issues of the models themselves, the trust issues brought by the evolution of algorithm “emergence” characteristics (as well as the trust brought by uncontrollability), but on the other hand, users have always been skeptical of the accuracy, completeness, and honest operation of so-called algorithm models. Therefore, the issue of trust in AI should be addressed from three levels: users, service providers, and model uncontrollability.
3. ZKML: Trust Brought by the Combination of Zero-Knowledge Proof and AI
3.1. Zero-Knowledge Proof: Technologies Such as zk-SNARKS and zk-STARK Are Becoming More Mature
Zero-Knowledge Proof (ZKP) was first proposed by MIT’s Shafi Goldwasser and Silvio Micali in a paper called “Knowledge Complexity of Interactive Proof Systems” in 1985. The authors mentioned in the paper that the prover may make the verifier believe the truthfulness of the data without revealing the specific data. There is a public function f(x) and an output value y of the function, Alice tells Bob that she knows the x value, but Bob does not believe it. Therefore, Alice uses a zero-knowledge proof algorithm to generate a proof. Bob verifies this proof to confirm whether Alice really knows x that satisfies the function f.
For example, using zero-knowledge proof, it is possible to know whether Xiao Ming’s exam score meets the user’s requirements without knowing his actual score, such as whether he passed or whether his fill-in-the-blank rate exceeded 60%. In the field of AI, zero-knowledge proof can be combined with AI models to provide a reliable tool for trust.
Zero-knowledge proof can be interactive, in which the prover must prove the authenticity of the data to each verifier, or non-interactive, in which the prover creates a proof that anyone using it can verify.
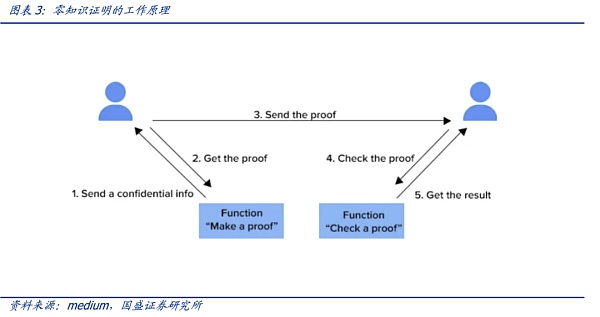
Zero-knowledge proof is divided into two parts: proof and verification. Generally, the proof is quasi-linear, and the verification is T*log(T).
Assuming the verification time is the square of the logarithm of the number of transactions, the machine verification time for 10,000 transactions per block is
VTime = ( )2 ~ (13.2)2 ~ 177 ms; now if the block size is increased by 100 times (reaching 1 million tx/block), the new running time of the verifier is VTime = (log2 1000000)2 ~ 202 ~ 400 ms. Therefore, we can see its super scalability, which is why the theoretical TPS can reach infinity.
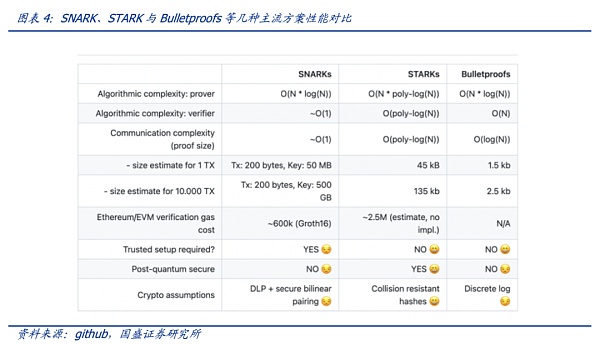
Verification is very fast, and all the difficulties lie in generating the proof. As long as the speed of generating the proof can keep up, the chain verification is very simple. There are currently various implementation methods of zero-knowledge proof, such as zk-SNARKS, zk-STARKS, PLONK, and Bulletproofs. Each method has its own advantages and disadvantages in proof size, prover time, and verification time.
The more complex and larger the zero-knowledge proof is, the higher the performance and the shorter the time required for verification. As shown in the figure below, STARKs and Bulletproofs do not require trusted setup, and as the transaction data volume increases from 1TX to 10,000TX, the latter proof size increases less. The advantage of Bulletproofs is that the proof size is logarithmic transformation (even if f and x are large), which may allow the proof to be stored in blocks, but its verification computational complexity is linear. It can be seen that there are many key points to be weighed for various algorithms, and there is also a lot of room for upgrading. However, in the actual operation process, the difficulty of generating the proof is much greater than imagined, so the industry is now committed to solving the problem of generating the proof.
Although the development of zero-knowledge proof technology is not yet sufficient to match the scale of large language models (LLMs), its technical implementation has inspiring application scenarios. Especially in the development of AI double-edged swords, zero-knowledge proof provides a reliable solution for the trustworthiness of AI.
3.2. Zero Knowledge Machine Learning (ZKML): Trustless AI
As AI-generated content gets closer and closer to human-generated content, the characteristics of zero-knowledge proof technology can help us determine if specific content comes from a particular model. Zero-knowledge proof technology is particularly important for privacy protection, as it can prove and verify without revealing user data input or model-specific details. Taking into account completeness of calculation, heuristic optimization, and privacy, zero-knowledge proof and AI are combined to give birth to Zero-Knowledge Machine Learning (ZKML).
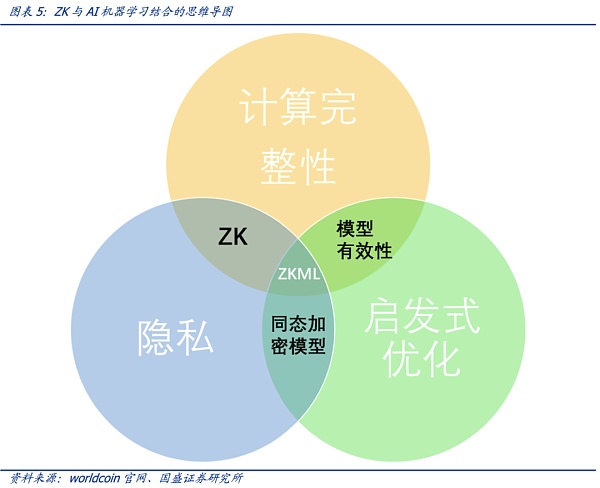
Here are five ways zero-knowledge proof is applied to machine learning. In addition to basic features such as calculation completeness, model integrity, and user privacy, zero-knowledge machine learning can also bring distributed training-which will promote the integration of AI and blockchain-as well as identity verification for humans in the AI jungle (which can be found in our report “OpenAI founder’s Web3 vision: Worldcoin creates AI digital passport”).

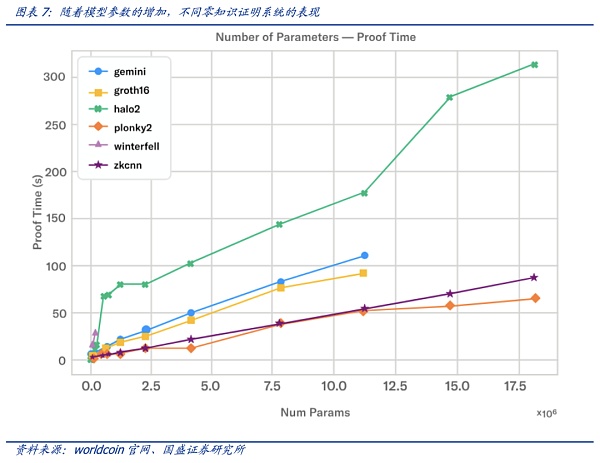
The demand for computing power in AI large models is obvious, and at this time, inserting ZK proofs into AI applications brings new hardware requirements for hardware computing power. The current level of technology of zero-knowledge systems combined with high-performance hardware is still unable to prove something as large as the currently available large language models (LLMs), but some progress has been made in creating proofs for smaller models. Modulus Labs team tested existing ZK proof systems for various models of different sizes. Proof systems such as plonky2 can run on a powerful AWS machine for about 50 seconds, creating proof for models with about 18 million parameters.
As for hardware, the current hardware choices for ZK technology include GPUs, FPGAs, or ASICs. It should be noted that zero-knowledge proof is still in its early stages of development, is currently rarely standardized, and algorithms are constantly being updated and changed. Each algorithm has its characteristics and is suitable for different hardware, and each algorithm will be improved to some extent as project development needs change, making it difficult to evaluate which algorithm is optimal.
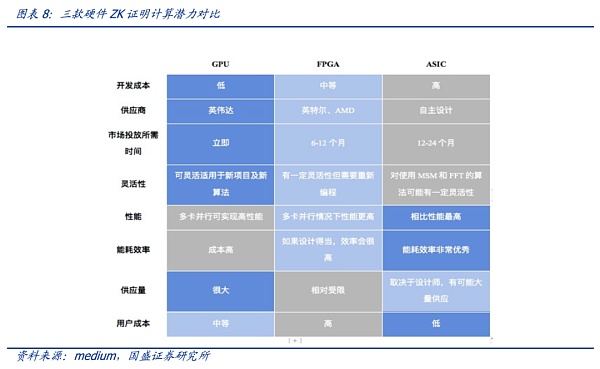
It should be noted that there is no clear research on the combination of ZK and AI large models to evaluate existing hardware systems, so there is still a lot of variability and potential in future hardware requirements.
3.3. Inspirational Case: Verification of Twitter’s Recommendation Algorithm
Twitter’s “For You” recommendation feature uses an AI recommendation algorithm to extract a few popular tweets from about 500 million tweets posted each day and finally display them on the “For You” timeline of the user’s homepage. The recommendation extracts potential information from tweets, users, and engagement data to provide more relevant recommendations. At the end of March 2023, Twitter open-sourced the algorithm for selecting and ranking posts on the “For You” timeline. The recommendation process is roughly as follows:
1) Generate user behavior features from user-site interactions and get the best tweets from different recommendation sources;
2) Rank each tweet with an AI algorithm model;
3) Apply heuristic functions and filters, such as filtering out blocked tweet content and viewed tweets from users.
The most core module of the recommendation algorithm is the Home Mixer service that builds and provides the For You timeline. This service acts as the algorithm backbone that connects different candidate sources, rating functions, heuristic methods, and filters.
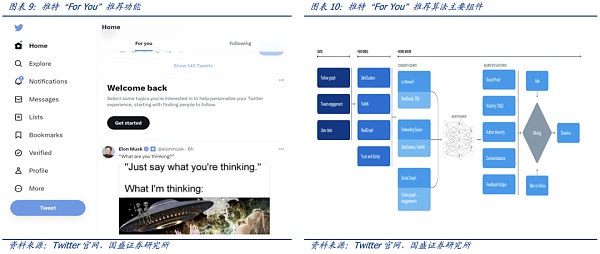
According to Twitter, the “For You” recommendation feature predicts the relevance of each of the approximately 1500 potentially relevant candidate recommendations and scores them. At this stage, all candidate tweets are treated equally. The core ranking is achieved through a neural network with about 48 million parameters, which is continuously trained on tweet interactions to optimize. This ranking mechanism considers thousands of features and outputs about ten labels to score each tweet, where each label represents the probability of engagement, and then ranks the tweets based on these scores.
Although this is an important step for Twitter’s recommendation algorithm to become transparent, users still cannot verify whether the algorithm is accurate or complete – one of the main reasons is that the specific weight details of the algorithm model used to rank tweets have not been disclosed to protect user privacy. Therefore, the transparency of the algorithm remains questionable.
Using ZKML (Zero-Knowledge Machine Learning) technology, it is possible to prove whether the algorithm runs accurately and completely (whether the model and its parameters treat different users equally) without disclosing the weight details of the algorithm model that Twitter does not make public. This achieves a good balance between privacy protection and transparency of the algorithm model.
Community developers Daniel Kang et al. used the cryptographic tool ZK-SNARKs to check if the Twitter recommendation algorithm was running correctly and completely without disclosing the algorithm’s details. This is precisely what makes zero-knowledge proof so appealing: the ability to prove the credibility of information without revealing any specific information about the object (zero knowledge). Ideally, Twitter could use ZK-SNARKS to publish a proof of its ranking model – a proof that when the model is applied to specific users and tweets, it produces a specific final output ranking. This proof is the basis of the model’s credibility: users can verify for themselves whether the algorithm’s calculations follow the promise – or leave it to a third party to audit. All of this is done without revealing the details of the model’s parameter weights. That is, using the officially published model proof, users can use this proof to verify whether specific tweets are honestly executed according to the model’s promise.
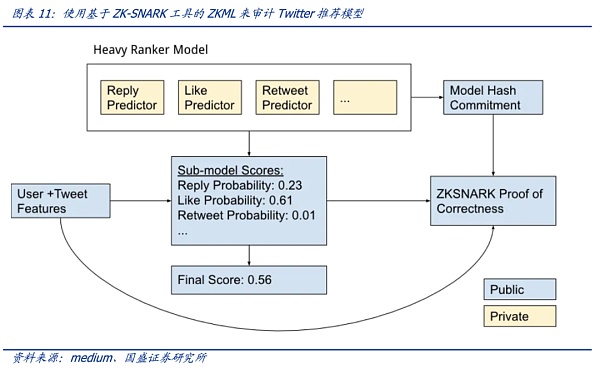
Suppose a user doubts the “For You” recommendation feature of the timeline – believing that the ranking of some tweets should be higher (or lower). If Twitter can launch the ZKML proof function, users can use the official proof to check for themselves how the suspected tweets rank compared to other tweets in the timeline (the calculated score corresponds to the ranking). If the ranking does not match the score of the model, it means that the algorithm model for these specific tweets is not honestly running (but artificially changed in some parameters). It can be understood in this way that although the official does not disclose the specific details of the model, according to the model, a magic wand (the proof generated by the model) is given, and any tweet can use this magic wand to show the relevant ranking score – but the privacy details of the model cannot be restored according to this magic wand. Therefore, the privacy details of the official model are protected while being audited.

From the perspective of the model, using ZKML technology can still enable the model to be audited and gain the trust of users while protecting the privacy of the model.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- OKX BTC browser officially supports Lightning Network now.
- Warning of new scam: tricking you into thinking big players are buying memecoins by transferring “fake WETH”
- Bankless: The Prosperity and Challenges of Optimistic Rollup
- Inventory of DAO trends that have received ARB airdrops: Balancer, Radiant, Stargate DAO……
- Is cryptocurrency the biggest scam in history? A decade-long history of love and hate between enthusiasts and critics
- Evolution of the Web3 Community: The Decline of PFP Community and the New Dawn of NFT
- Web3 Gaming New Infrastructure: Listening to Thunder in Silence






