Dry goods | Vitalik: Eth2 segmentation chain simplification proposal
Essential refinement
- The concept of a persistent shard chain will no longer exist. Instead, each tile is directly a crosslink. The proponent issues a proposal, and the cross-linking committee is responsible for approval.
- The number of tiles is reduced from the previous 1024 to 64, and the tile size is increased from (target value 16, upper limit 64) kB to (target value 128, upper limit value 512) kB. The total fragmentation capacity is 1.3-2.7 MB/s, depending on the slot time. If needed, the number of shards and block size can increase over time, say 1024 shards and 1 MB blocks after 10 years.
- A number of simplification schemes have been implemented at the L1 and L2 layers: (i) fewer fragmented chain logic required, and (ii) because "native" cross-sliced communication can be done in 1 time slot, so there is no need to pass Layer- 2 to accelerate cross-sliced communication, (iii) to facilitate the payment of cross-sliced transaction procedures without decentralized exchanges, (iv) the execution environment can be further simplified, (v) no need to mix serialization and hashing;
- The main disadvantages are: (i) the overhead of the beacon chain is greater, (ii) the fragmentation block takes longer to produce, (iii) the demand for “sudden” bandwidth is higher, but the demand for “average” bandwidth is lower.
Preface/idea
The current Ethereum 2.0 architecture is too complex, especially at the fee market level, and some people think of using Layer-2's strain approach to solve the main problem of the Eth2 base layer: although the block time within the slice is very short. (3-6s), however, the base layer communication time between slices is particularly long, requiring 1-16 epochs (if more than 1/3 of the certifiers are offline, it takes longer). This is an urgent need for an "optimistic" solution: a subsystem within a shard uses some sort of inferior security mechanism (such as a light client) to "pretend" to know the state roots of other shards in advance and use these uncertainties. The state root processes the transaction to calculate its own state. After a while, a "rear-guard" process traverses all shards, checks which calculations use the "correct" information for other shard states, and discards all calculations that do not use the "correct" information.
But this process is problematic. Although it can effectively simulate ultra-high-speed communication time in many cases, the difference between "optimistic" ETH and "real" ETH leads to other complicated situations. Specifically, we cannot assume that the block proposer "knows" the optimistic ETH, so if the user on slice A sends ETH to the user on slice B, Then, the user on the fragment B needs to wait for a period of time to receive the protocol layer ETH (the only ETH that can be used to pay the transaction fee). If you want to avoid delays, you either need to decentralize the exchange (there are complexities and inefficiencies) or you need to relay the market (and worry that the monopoly repeater might review the user's transactions).
In addition, the current cross-linking mechanism greatly increases the complexity. In fact, it requires a whole set of blockchain logic, including reward and punishment calculations, separate storage of intra-segment reward status, and fork selection rules. Inclusion in the segmentation chain as part of Phase 1. This document presents a bold alternative to address all of these issues, enabling Ethereum 2.0 to be used faster and at the same time reduce risk, with some compromises.
Program details
We reduced the SHARD_COUNT (number of fragments) from 1024 to 64 and increased the maximum number of fragments processed per time slot from 16 to 64. This means that the current “optimal” workflow is that each slice generates a cross-link during each beacon chain generation (for clarity, we no longer use “crosslink”). The term, because there is no “connection” to the segmentation chain, it is more appropriate to use the “sharding block” directly.
- Bitcoin is 11 years old. Has he grown up?
- Genesis Capital's third quarter report analyzes opportunities for cryptocurrency lending
- The domestic public chain Yuanjie DNA released the digital identity application Bitident (Bidden) to help the rise of the digital economy
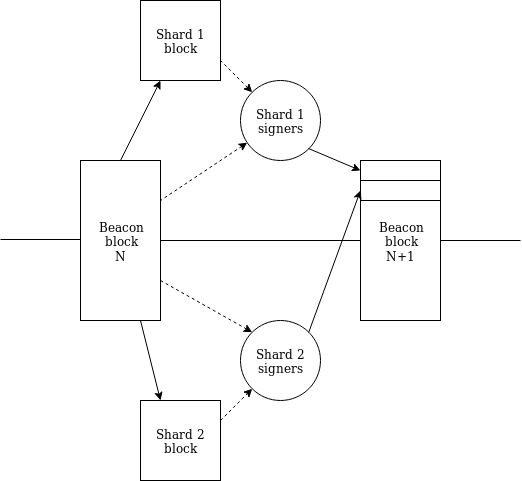
Note the key detail: any block at slot N+1 for any slice can now know the block at slot N for all slices through a single path. Therefore, we now have first-class single-slot cross-sliced communication (via Merkle receipts).

– Status (approximate) –

-New proposal –
In this proposal we changed the structure of the object connected to the attestation: in the original scheme, the witness message contained a "crosslink", which contained a complex serialized representation. The "data root" of many fragmented blocks; but in the new proposal, the witness message contains only one data root, which represents the content within a block (the content is entirely determined by the "proposer"). The tiled block will also include the signature from the proposer. In order to promote the stability of the p2p network, the way to calculate the proponent is still based on a persistent-committee-based algorithm. If no proposal is available, members of the Cross-Link Committee may also vote on the “Zero Proposal”.
We still store a map in the state of latest_shard_blocks: shard -> (block_hash, slot) , except that the parameter is changed from epoch to slot. Under ideal conditions, we hope that this mapping for each time slot can be updated.
Define online_validators as a subset of active certifiers, and at least one epoch in the last 8 time periods (epoch) contains their witness messages. Only 2/3 of the online_validators (in proportion to the total balance) will agree on the same new block for a given shard, and the above mapping will be updated.
Suppose the current time slot is n, but for a given slice i, latest_shard_blocks.slot < n-1 (ie, one slice of the slice is skipped in the previous time slot), we need to slice the Witness the message to provide the data root for all time slots in the range [latest_shard_blocks.slot + 1….min(latest_shard_blocks.slot + 8, n-1)].
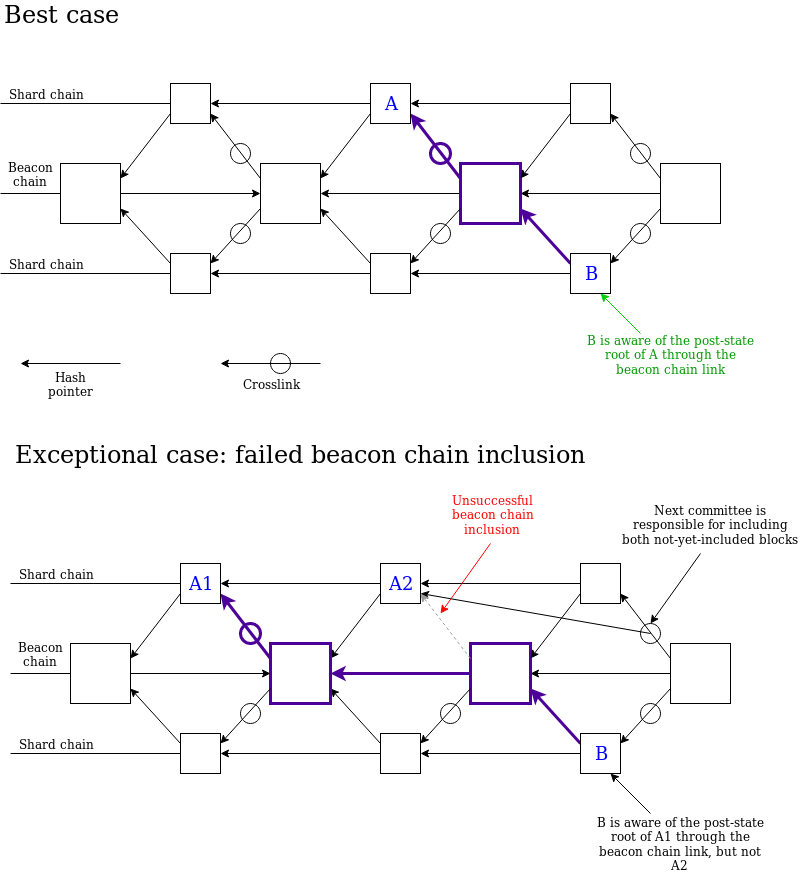
The fragmentation block still needs to point to the "previous fragmentation block", and we still have to enforce consistency, so the protocol requires multi-slot witness messages to ensure consistency. The committee adopts the following "forking selection rules":
- For each valid and available fragment block B (the ancestor block of the block must also be valid and available), calculate the total weight of the verifier whose latest message supports the descendants of B or B, and temporarily refer to this weight as the fragmentation area. The "score" of block B. Even a blank tile can have a score.
- Select the appropriate block based on the highest score at latest_shard_blocks[i].slot + 1
- When selecting a block at latest_shard_blocks[i].slot + k (k > 1), it is also selected according to the highest score, but only the parent block is selected at latest_shard_blocks[i].slot + (k-1) Block
Overview
The process from the beacon block N to the beacon block N+1 is as follows:
- Beacon block N is released;
- For any given slice i, the proposer of slice i proposes a slice block. The implementation of this block knows the beacon block N and the root of the previous block (if needed, we can reduce the visibility to block N-1 and the old block, which allows us to be on the beacon block and Fragmented blocks are simultaneously proposed);
- The witness assigned to slice i submits a witness message, including its opinion on the beacon block and the slice i block at time slot N (in the special case also includes the previous slice block in slice i) ;
- The beacon block N+1 is released, which includes witness messages for all shards. The state transition function of block N+1 processes these witness messages and updates the "latest state" of all slices.
cost analysis
Please note that participants do not need to actively download the tile data at any time. Conversely, when the proponent issues a proposal, it only needs to upload a data limit of 512 kB in 3 seconds (assuming there are 4 million verifiers, each of which requires an average of 128,000 time slots to be uploaded once), and then the committee verifies When proposing, it only needs to download data with a maximum of 512 kB in 3 seconds (required that each verifier wants to download the data in each epoch because we have reserved one attribute: in any given time period, each verification Both will be assigned a specific cross-link in a particular time slot.
Note that the requirement for this operation is lower than the current long-term load requirement for each verifier, which is about 2MB per epoch. However, this requires a higher “burst” load: the previous limit was 64KB in 3 seconds, and now the upper limit will increase to 512KB in 3 seconds.
The beacon chain data for the attestations load is changed as follows.
- Each witness message has a basic overhead of 224 bytes (128 bytes is AttestationData, 96 bytes is signature data), plus the witness bitfield requires 32 bytes (normal), and more 256 bytes (worst case) data. That is, a witness message requires an overhead of 256-280 bytes. A block can have up to 256 witness messages, and the average is about 128 (guess), so the message overhead for a single block is 32768 bytes (about 0.03 MB) under average conditions, and in the worst case 122880 words. Section (about 0.1 MB).
- Each slice status update message requires: (i) block chunk chunk data root, each 128 kB block data (or a portion thereof) requires a data root, so an average of 48 bytes is required, and a maximum of 128 bytes is required; (ii) fragment status root, 128 bytes; (iii) block body length, 8 bytes; (iv) custody bits, ranging from 32 bytes to 256 bytes. Therefore, on average, 216 bytes are required, and a maximum of 520 bytes is required. A single block can have up to 256 slice status update messages, averaging 64. Therefore, an average of 13824 bytes (about 0.01 MB) is required, and a maximum of 133120 bytes (about 0.1 MB) is required.
Each certificate has about 300 bytes of fixed data, plus a bit field, which is 4 million bits per epoch, and 8192 bytes per time slot. Therefore, the maximum load of the current scheme is 128 * 300 + 8192 = 46592, and the load in the average case may be closer to 32 * 300 + 8192 = 17792, even if it can reduce the load by compressing the redundant information in the proof.
For efficiency reasons, we only include the fragment status update data in the winning attestation in one block; only the hash value is saved for the fragment status update data in all other witness messages. This can save a lot of data overhead.
Also note that the cost of witness aggregation for each time slot in each shard is 65536 * 300 / 64 = 307200 bytes. This puts a natural system requirement threshold for the running node, so it doesn't make sense to compress the block data again.
At the computational level, the only significant increase in cost is the need for more pairings (more precisely, more Miller cycles), with the upper limit of each block increasing from 128 to 192, which will make the block The processing time is extended by 200ms.
"Basic Operating System" fragmentation
Each shard has a state, which is a mapping of ExecEnvID -> (state_hash, balance). A slice block is divided into a group of chunks, and each chunk specifies an execution environment. The execution of a chunk depends on the state root and the contents of the chunk (ie, part of the fragmented block data) as input, and outputs a list of [shard, EE_id, value, msg_hash] tuples, each of which has at most one EE_id (we Add two "virtual" shards: the transfer to shard-1 indicates that the certifier is storing the deposit to the beacon chain, and the transfer to shard-2 is the payment of the commission to the offer). We also subtract the total number of values from the balance of the EE.
In the fragment block header, we placed a "receipt root" containing a mapping: shard-> [[EE_id, value, msg_hash]…] (up to 8 elements per shard; in one Most of the majority of cross-segment EE transfers are for transfers to the same EE, even with fewer elements).
A fragment block on slice i should have a Merkel branch containing receipts for all other fragments, and this Merkel branch is generated by the receipt root of the other fragments (so any fragmentation i You can know the receipt root of any other fragment j). The value received will be assigned to its EE and the EE can access msg_has.
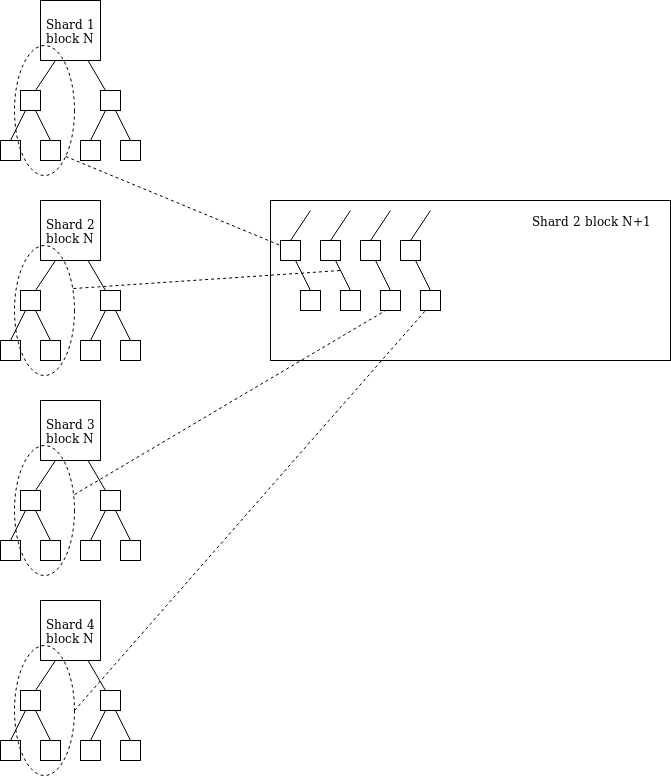
This allows different shards to implement an immediate ETH transition between EEs, with the overhead of each block being (32 * log(64) + 48) * 64 = 15360 bytes. Msg_hash can be used to reduce the size of the cross-sharding information witnessed by the ETH transfer, so 15360 bytes of data is essential in a highly active system.
Key benefits: a simpler cost market
We can then modify the Execution Environment (EE) system: each shard has a state that contains the state root and the balance of the execution environment. The execution environment will be able to send receipts to send money directly to the same EE of other shards. This process will be done using the Merkel branch processing mechanism. The EE state of each shard stores a nonce of each of the remaining shards to defend against replay attacks. EE can also be used to pay directly to block submitters.
This provides a sufficiently powerful feature that enables EE to be built on the basis of allowing users to deposit coins on shards and use them to pay transaction fees; transferring coins between shards is like the same shard It is as easy to operate as it is, thus eliminating the urgency of the need for the relay market and the burden on the EE to achieve optimistic cross-sharding.
Full and compressed witness message
For the sake of efficiency issues, we have also made the following optimizations. As mentioned earlier, the witness message directed to slot n can be completely contained in slot n+1. However, if such a witness message needs to be included in a subsequent time slot, it must be nested in "reduced form", containing only the beacon block (header, target, source) without any cross-linking data. .
This not only serves to reduce the effectiveness of the data, but more importantly, by forcing the "old witness message" to save the same data, the number of pairs needed to verify the witness message can be reduced: in most cases, all from the same time slot. Old witness messages can all be verified via a single pairing. If the chain is not forked, then in the worst case, the number of pairs needed to verify the old witness message is limited to 2 times the length of the epoch. If the chain does fork, the ability to include all witness messages depends on a higher percentage of honest proposers (such as 1/32 instead of 1/64) and include earlier proofs.
Ensure light client participation
Every day, we randomly select a committee of approximately 256 certifiers that can sign on each block, and the certifiers whose signatures are included can be rewarded in block n+1. The purpose of this is to allow light clients with low computing power to participate.
Off topic: data availability root
The operation to prove the availability of a 128 kB data is superfluous and has little value. In contrast, it makes sense to require that a block be able to provide a series root of all the fragmented block data that the block accepts and combines together (perhaps this fragmented block data root exists in a list, where each root represents 64 kB of data, which makes series connection easier). You can then create a single data availability root based on this data (average 8 MB, worst case 32 MB). Note that creating these roots may take longer than a time slot, so it's best to check the availability of data before an epoch (ie, sampling from these data availability roots will be extra "deterministic" an examination").
Other possible options
- The fragment block of slot n must reference the beacon chain block of slot n-1 instead of the beacon chain block at slot n. Such a measure would allow loops in time slots to occur in parallel instead of in series, thereby reducing slot time, at the cost of causing cross-sliced communication time to rise from 1 slot to 2 slots.
- If a block proposer tries to expand the block size to more than 64KB (note: target 128kB), he needs to generate 64kB of data first, then have the cross-linking committee sign it, and then they can add a reference to the first one. Signed 64kB data, and so on. This will encourage block creators to submit partial completion versions of their blocks every few seconds, creating a mechanism for pre-validation.
- Accelerate the development of secret leader elections (for simplicity, even an anonymous ring signature version of about 8 to 16 people can make a difference).
- Instead of using the "forced embedding" mechanism, we might as well seek a simpler alternative: each shard maintains an "inbound nonce" and an "outbound nonce" for each of the remaining shards (ie 8 * 64 * 2 = 1024) The status of the bytes), a fragmented manufacturing receipt will need to be manually added and processed in order by the received fragments. Receipt generation will be limited to a small receipt for each target shard in each block to ensure that one shard can process all incoming receipts, even if all shards simultaneously distribute receipts to it.
Original link: https://notes.ethereum.org/@vbuterin/HkiULaluS?from=groupmessage&isappinstalled=0 Author: Vitalik
This article was translated by ECN Ethereum China Community and EthFans is authorized to use the translation. At the time of publication, the translation was updated according to the changes in the original text.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- The digital currency of Chinese listed companies (below)
- The contract market will add another fierce will explain the currency China strategy
- SpaceX also engages in IEO? Musk is forced
- How to develop a "no coin" public chain?
- QKL123 market analysis | Federal Reserve cut interest rates as scheduled, safe-haven assets fluctuate (1031)
- The German Banking Association published a paper calling for the establishment of a programmable digital euro
- Top 10 DeFi Big Chain Life





