Vitalik Buterin Social media experiment Community Notes embodies the spirit of encryption.
Vitalik Buterin's Community Notes embodies encryption spirit.Author: Vitalik; Translation: Deep Tide TechFlow
In the past two years, Twitter (X) can be said to have been in turmoil. Last year, Elon Musk purchased the platform for $44 billion and subsequently carried out comprehensive reforms in terms of personnel configuration, content moderation, business model, and website culture. These changes were likely more attributed to Elon Musk’s soft power rather than specific policy decisions. However, amidst these controversial actions, a new feature on Twitter quickly became important and seemed to be favored by various political factions: Community Notes.
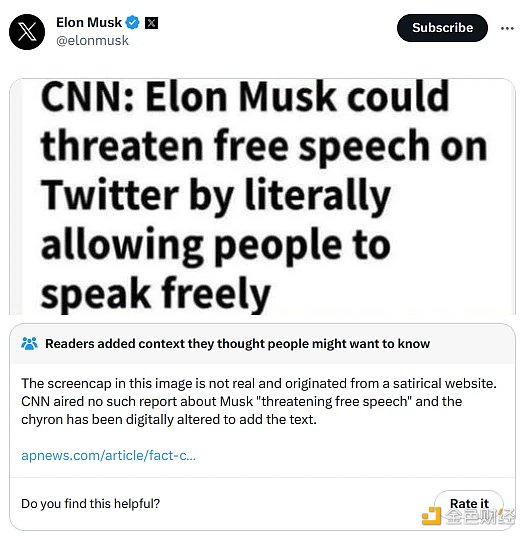
Community Notes is a fact-checking tool that sometimes attaches background annotations to tweets, such as Elon Musk’s tweet above, as a tool for fact-checking and countering misinformation. It was initially known as Birdwatch and was first launched as a pilot project in January 2021. Since then, it has gradually expanded, with the fastest expansion phase coinciding with Elon Musk taking over Twitter last year. Today, Community Notes frequently appear in widely discussed tweets on Twitter, including those involving controversial political topics. In my opinion, as well as the conclusion I have reached after talking to many people from various political factions, these Notes are informative and valuable when they appear.
- Who is creating Binance A Borderless Company in 4,000 Resumes
- LianGuai Morning Post | Federal Reserve Meeting Minutes Core Inflation Will Significantly Decrease in the Second Half of the Year
- Is the ‘big boss’ of the cryptocurrency world, Binance, starting to decline?
However, what interests me the most is Community Notes, which, although not a “cryptocurrency project,” may be the closest example we have seen in the mainstream world to “cryptocurrency values.” Community Notes are not written or planned by a central group of experts; instead, anyone can write and vote on them, and which Notes are displayed or not is entirely determined by an open-source algorithm. The Twitter website has a detailed and comprehensive guide describing how the algorithm works, and you can download the data containing published Notes and votes, run the algorithm locally, and verify if the output matches the content visible on the Twitter website. Although not perfect, it surprisingly comes close to the ideal of trustworthy neutrality in quite controversial situations and is also very useful.
How does the Community Notes algorithm work?
Anyone who meets certain conditions for a Twitter account (basically: active for more than 6 months, no violations, verified phone number) can register to participate in Community Notes. Currently, participants are being accepted slowly and randomly, but the ultimate plan is to allow anyone who meets the conditions to join. Once accepted, you can first participate in rating existing Notes, and once your ratings are good enough (measured by seeing which ratings match the final result of the Notes), you can also write your own Notes.
When you write a Note, it is assigned a score based on the evaluations of other Community Notes members. These evaluations can be seen as votes along the three levels of “helpful,” “somewhat helpful,” and “not helpful,” but evaluations can also include other tags that play a role in the algorithm. Based on these evaluations, the Note receives a score. If the score of the Note exceeds 0.40, it will be displayed; otherwise, it will not be displayed.
The uniqueness of the algorithm lies in the way scores are calculated. Unlike simple algorithms that aim to calculate only a sum or average of user ratings and use it as the final result, the Community Notes rating algorithm explicitly tries to prioritize Notes that have received positive evaluations from people with different perspectives. In other words, if people who usually have conflicting opinions on ratings reach a consensus on a particular Notes, that Notes will be highly rated.
Let’s delve into how it works. We have a group of users and a group of Notes; we can create a matrix M, where the cell Mij represents how the i-th user rates the j-th Notes.
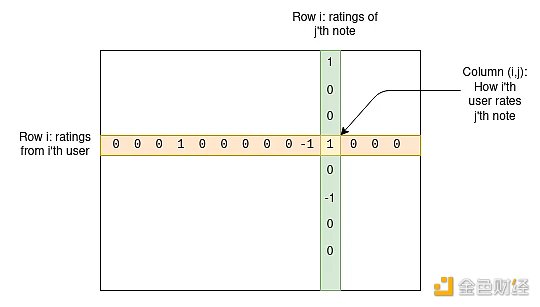
For any given Notes, most users have not rated it, so most entries in the matrix will be zero, but that’s okay. The goal of the algorithm is to create a four-column model of users and Notes, assigning two statistical data to each user, which we can call “friendliness” and “polarity,” and two statistical data to each Notes, which we can call “usefulness” and “polarity.” The model attempts to predict the matrix as a function of these values, using the following formula:
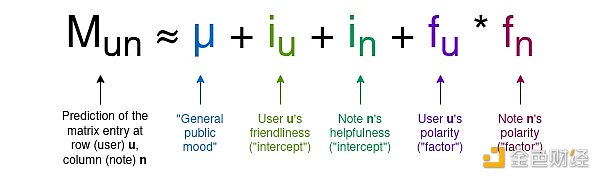
Note that here I introduce the terms used in the Birdwatch paper, as well as the terms I provided myself, in order to have a more intuitive understanding of the meaning of the variables, without involving mathematical concepts:
-
μ is a “public sentiment” parameter that measures how high user ratings are generally given.
-
iu is the “friendliness” of the user, indicating how likely the user is to give high ratings.
-
in is the “usefulness” of the Notes, indicating how likely the Notes will receive high ratings. This is the variable we are interested in.
-
fu or fn is the “polarity” of the user or Notes, indicating their position on the dominant axis of political extremes. In practice, negative polarity roughly means “left-leaning,” and positive polarity means “right-leaning,” but please note that the extreme axis is derived from analyzing user and Notes data, and the concepts of left and right are not hard-coded in.
The algorithm uses a fairly basic machine learning model (standard gradient descent) to find the optimal values of the variables to predict the matrix values. The usefulness assigned to a specific Notes is its final score. If the usefulness of a Notes is at least +0.4, then that Notes will be displayed.
The clever part here is that “polarity” absorbs the characteristics of a Notes that make it liked by some users and disliked by others, while “usefulness” only measures the characteristics of a Notes that make it liked by all users. Therefore, selecting usefulness can identify Notes that are recognized across communities and exclude Notes that are celebrated in one community but provoke antipathy in another community.
The above content only describes the core part of the algorithm. In fact, there are many additional mechanisms added on top of it. Fortunately, they are described in public documents. These mechanisms include:
-
The algorithm runs multiple times, each time adding some randomly generated extreme “pseudo votes” to the voting. This means that the algorithm has a value range for the true output of each Notes, and the final result depends on the “lower confidence” taken from that range and compared with the threshold of 0.32.
-
If many users (especially users with similar polarity to the Notes) rate a Notes as “not useful” and they also specify the same “tags” (e.g., “controversial or biased language”, “source does not support the Notes”) as the reason for the rating, then the usefulness threshold required for the publication of the Notes will increase from 0.4 to 0.5 (which may seem small but is very important in practice).
-
If a Notes is accepted, its usefulness must be reduced to below the threshold of 0.01 required for accepting the Notes.
-
The algorithm uses multiple models to run more times and sometimes promotes Notes with original usefulness scores between 0.3 and 0.4.
In summary, you will get some quite complex Python code, totaling 6282 lines, distributed in 22 files. But everything is open, you can download the Notes and rating data and run it yourself to see if the output matches the actual situation on Twitter.
So what does this look like in practice?
The biggest difference between this algorithm and the simple method of averaging scores from people’s votes is probably the concept of “polarity” values that I call. The algorithm document refers to them as fu and fn, using f to represent the factor, because these two terms multiply each other; the more general term is used because the ultimate goal is to make fu and fn multidimensional.
Polarity is assigned to users and Notes. The link between user ID and the underlying Twitter account is deliberately kept confidential, but the Notes are public. In fact, at least for the English dataset, the polarity generated by the algorithm is closely related to left and right-wing.
Here are some Notes examples with a polarity of about -0.8:
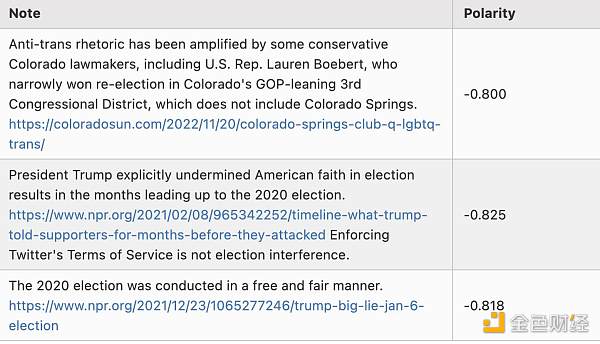
Please note that I didn’t select them here; these are actually the first three rows in the scored_notes.tsv spreadsheet generated when I ran the algorithm locally, and their polarity scores (called coreNoteFactor 1 in the spreadsheet) are less than -0.8.
Now, here are some Notes with a polarity of about +0.8. It turns out that many of them are either people discussing Brazilian politics in Portuguese or fans of Tesla angrily refuting criticism of Tesla, so let me pick a few that don’t belong to these two categories:
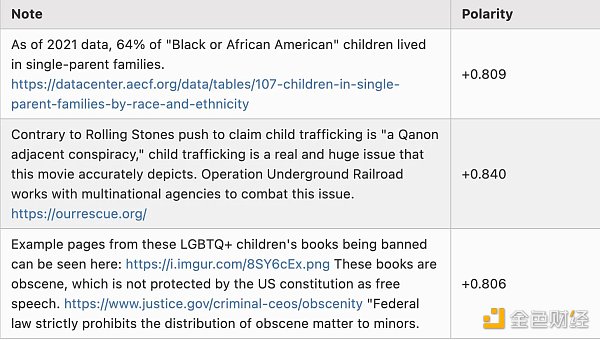
Just a reminder, the division between “left-wing and right-wing” is not hard-coded into the algorithm in any way; it is discovered through computation. This indicates that if you apply this algorithm to other cultural backgrounds, it can automatically detect their main political divisions and build bridges between them.
At the same time, the Notes that get the highest utility look like this. This time, because these Notes are actually displayed on Twitter, I can directly take a screenshot:
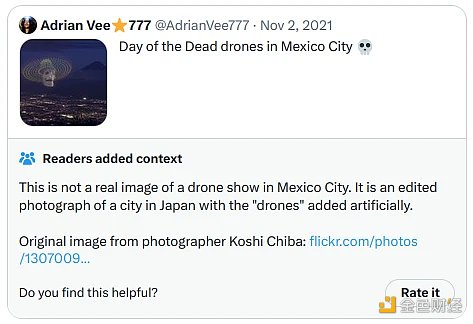
And another one:
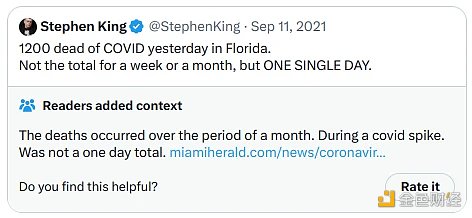
For the second Notes, it directly involves highly partisan political themes, but it is a clear, high-quality, and informative Notes, so it received a high rating. Overall, this algorithm seems to be effective, and it also seems feasible to verify the output of the algorithm by running the code.
What do I think of this algorithm?
When analyzing this algorithm, what impressed me the most is its complexity. There is an “academic paper version” that uses gradient descent to find the best fit for a five-item vector and matrix equation, and then there is the real version, a series of complex algorithm executions that involve many different executions and many arbitrary coefficients along the way.
Even the academic paper version hides the underlying complexity. The equation it optimizes is a negative fourth-degree polynomial (because the prediction formula includes a quadratic fu*fn term, and the cost function measures the square of the error). Although optimizing a quadratic equation over any number of variables almost always has a unique solution that can be calculated with fairly basic linear algebra, optimizing a fourth-degree equation over many variables typically has many solutions, so multiple rounds of gradient descent can yield different answers. Small changes in the inputs can cause the descent to flip from one local minimum to another, significantly altering the output.
This is different from the algorithms I have been involved in developing, such as quadratic funding, which feels like the difference between an economist’s algorithm and an engineer’s algorithm to me. An economist’s algorithm, at best, emphasizes simplicity, is relatively easy to analyze, and has clear mathematical properties that explain why it is optimal (or at least not too bad) for the task at hand, ideally proving how much damage one can cause by trying to exploit it. On the other hand, an engineer’s algorithm is arrived at through an iterative trial-and-error process, seeing what works and what doesn’t work in the engineer’s operational environment. An engineer’s algorithm is pragmatic and gets the job done; an economist’s algorithm doesn’t completely break down when faced with unexpected situations.
Or, as respected internet philosopher roon (also known as tszzl) said on related topics:

Of course, I will say that the “aesthetic theory” of cryptocurrencies is necessary because it can accurately distinguish between protocols that truly do not require trust and those that appear good and operate well on the surface but actually require trust in some centralized participants, or worse, may be outright scams.
Deep learning is effective under normal circumstances, but it has inevitable weaknesses against various adversarial machine learning attacks. If done well, technical traps and highly abstract ladders can counter these attacks. So, I have a question: can we transform Community Notes itself into something more like an economic algorithm?
To understand what this actually means, let’s explore an algorithm I designed several years ago for a similar purpose: LianGuaiirwise-bounded quadratic funding (a new design for quadratic funding).
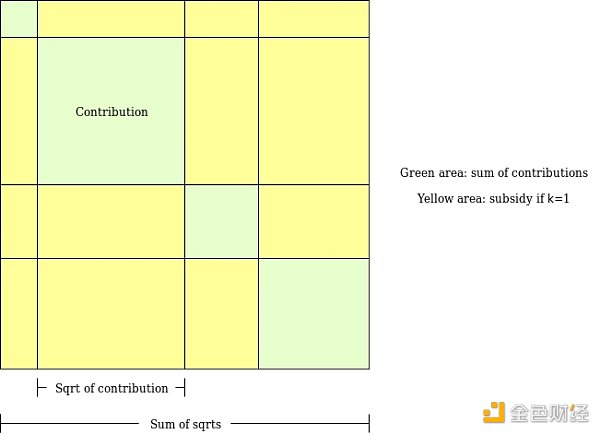
The goal of LianGuaiirwise-bounded quadratic funding is to fill a loophole in “conventional” quadratic funding, where even if two participants collude with each other, they can contribute a very large amount to a false project, have the funds returned to them, and receive a large subsidy that depletes the entire funding pool. In LianGuaiirwise-bounded quadratic funding, we allocate a limited budget M for each pair of participants. The algorithm traverses all possible pairs of participants, and if the algorithm decides to add a subsidy to a project P because participants A and B both support it, the subsidy is deducted from the budget allocated to that pair (A, B). Therefore, even if k participants collude, the maximum amount they can steal from the mechanism is k * (k-1) * M.
This form of algorithm is not applicable to the background of Community Notes because each user only casts a few votes: on average, the common votes between any two users are zero, so the algorithm cannot understand the polarity of users simply by examining each pair. The goal of machine learning models is to try to “fill” matrices from very sparse source data, which cannot be directly analyzed in this way. However, the challenge with this approach is that additional effort is required to avoid highly unstable results when faced with a small number of adverse votes.
Can Community Notes really resist left and right-wing factions?
We can analyze whether the Community Notes algorithm can actually resist extremism, that is, whether it performs better than a naive voting algorithm. This voting algorithm has already resisted extremism to some extent: a post with 200 likes and 100 dislikes performs worse than a post with only 200 likes. But does Community Notes do better?
From an abstract algorithm perspective, it’s hard to say. Why can’t a post with a high average rating but with polarization and high usefulness receive strong polarity? The idea is that if these votes are conflicting, polarity should “absorb” the characteristic that leads to a large number of votes for the post, but does it really achieve that?
In order to check this, I ran my own simplified implementation for 100 rounds. The average results are as follows:

In this test, “good” Notes received a score of +2 among users of the same political faction and a score of +0 among users of the opposing political faction. “Good but more extreme” Notes received a score of +4 among users of the same faction and a score of -2 among users of the opposing faction. Although the average scores are the same, the polarity is different. And in fact, the average usefulness of “good” Notes seems to be higher than that of “good but more extreme” Notes.
An algorithm that is closer to the “economist algorithm” will have a clearer story to explain how it punishes extremism.
How useful is all of this in high-risk situations?
We can understand some of the situations by observing a specific case. About a month ago, Ian Bremmer complained that a tweet added a highly critical Community Note, but the Note has been deleted.
This is a daunting task. Designing mechanisms in an Ethereum community environment is one thing, where the biggest complaint may only be $20,000 flowing to an extreme Twitter influencer. But when it comes to political and geopolitical issues affecting millions of people, the situation is completely different, and everyone tends to reasonably assume the worst motives. However, if mechanism designers want to have a significant impact on the world, interacting with these high-risk environments is essential.
Fortunately, the algorithm is open source and verifiable, so we can actually delve into it! Let’s do it. The URL of the original tweet is https://twitter.com/MFA_China/status/1676157337109946369. The number 1676157337109946369 at the end is the tweet’s ID. We can search for this ID in the downloadable data and identify the specific row in the spreadsheet with the aforementioned Notes:
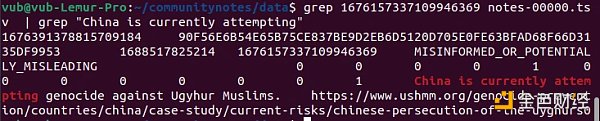
Here, we get the ID of the Notes itself, 1676391378815709184. Then we search for this ID in the scored_notes.tsv and note_status_history.tsv files generated by the algorithm. We get the following results:
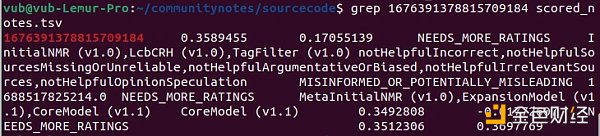

The second column in the first output is the current score of the Notes. The second output shows the history of the Notes: its current status is in the seventh column (NEEDS_MORE_RATINGS), and the first status it received before it was not NEEDS_MORE_RATINGS is in the fifth column (CURRENTLY_RATED_HELPFUL). Therefore, we can see that the algorithm itself first displayed the Notes and then deleted it after its score slightly decreased – seemingly without involving centralized intervention.
We can also look at the votes themselves in another way. We can scan the ratings-00000.tsv file to separate all the ratings for that Notes and see how many are rated as HELPFUL and NOT_HELPFUL:

However, if you sort them by timestamp and look at the first 50 votes, you will find 40 HELPFUL votes and 9 NOT_HELPFUL votes. Therefore, we come to the same conclusion: the initial audience of Notes had a more positive evaluation of Notes, while the later audience had a lower evaluation, resulting in a higher score at the beginning and a lower score over time.
Unfortunately, it is difficult to explain exactly how Notes changed its status: it is not a simple matter of “it was deleted because the previous score was higher than 0.40 and now it is lower than 0.40.” Instead, a large number of NOT_HELPFUL responses triggered one of the exceptional conditions, increasing the usefulness score that Notes needs to maintain above the threshold.
This is another good learning opportunity that teaches us a lesson: to make a trusted neutral algorithm truly trustworthy, it needs to be kept simple. If a Notes goes from being accepted to being rejected, there should be a simple and clear story to explain why.
Of course, there is another completely different way to manipulate this vote: Brigading. Someone who disagrees with a Notes they see can call on a highly engaged community (or worse, a large number of fake accounts) to vote it as NOT_HELPFUL, and it may not take many votes to change Notes from “useful” to “extreme.” To properly reduce the vulnerability of this algorithm to such coordinated attacks, more analysis and work are needed. One possible improvement is to not allow any user to vote on any Notes, but to randomly assign Notes to raters in a way recommended by the “For You” algorithm, and only allow raters to rate the Notes assigned to them.
Are Community Notes not “brave” enough?
I see that the main criticism of Community Notes is basically that it doesn’t do enough. I have seen two recent articles mentioning this. Quoting from one of the articles:
“It has a serious limitation, which is that in order to make Community Notes public, it must have universal acceptance from people of all political factions.”
“It has to have ideological consensus,” he said. “This means that both left-wing and right-wing people must agree that the note must be attached to the tweet.”
He said that essentially, it requires “cross-ideological agreement on truth, and in an environment of increasing partisan strife, achieving such consensus is almost impossible.”
This is a tricky issue, but in the end, I tend to think that I would rather let ten tweets with false information spread freely than unfairly attach a note to one tweet. We have witnessed years of fact-checking, which is brave, and from the perspective of “we actually know the truth, we know that one side lies more often than the other.” What will be the result?

To be honest, there is a widespread mistrust of the concept of fact-checking. Here, one strategy is to say: ignore the critics and remember that fact-checking experts really know the facts better than any voting system and stick with it. But fully committing to this approach seems risky. It is valuable to establish a cross-tribal institution that is respected to some extent by everyone. Just like William Blackstone’s maxim and the courts, I think that to maintain this respect, a system is needed where mistakes are made out of omission rather than actively making mistakes. Therefore, for me, it seems valuable that at least one major organization takes this different path and regards its rare cross-tribal respect as a precious resource.
Another reason why I think it is okay for Community Notes to be conservative is that I don’t think every tweet of misinformation, or even most tweets of misinformation, should receive corrective comments. Even if less than one percent of tweets of misinformation receive comments providing context or correction, Community Notes still provides an extremely valuable service as an educational tool. The goal is not to correct everything; instead, the goal is to remind people that there are multiple perspectives and that certain posts that seem convincing and engaging in isolation are actually quite wrong, and yes, you can usually do a basic internet search to verify that it is wrong.
Community Notes cannot and is not intended to be a panacea for all the problems in public epistemology. Whatever it cannot solve, there is ample space for other mechanisms to fill, whether it be novel tools like prediction markets or old-fashioned organizations hiring full-time staff with domain expertise to try to fill in these gaps.
Conclusion
Community Notes is not only an engaging social media experiment, but also an example of an engaging emerging type of mechanism design: consciously attempting to identify extremes and leaning towards promoting cross-tribal mechanisms rather than perpetuating divisions.
Two other examples in this category that I am aware of are: (i) the paired quadratic funding mechanism used in Gitcoin Grants, and (ii) Polis, a discussion tool that uses clustering algorithms to help communities identify widely popular statements that cut across people who usually have different views. This field of mechanism design is valuable and I hope to see more academic work in this area.
The algorithmic transparency provided by Community Notes is not fully decentralized social media—if you disagree with how Community Notes works, there is no way to view the same content from different algorithms. But this is the closest result we can see in the next few years that large-scale applications will achieve, and we can see that it has already provided a lot of value in preventing centralized manipulation and ensuring that platforms that do not engage in such manipulation are duly recognized.
I look forward to seeing the development and growth of Community Notes and many similar-minded algorithms in the next decade.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Vitalik Buterin What are my thoughts on Community Notes?
- Evening Must-Read | The Future of MEV is the Future of the Cryptocurrency World. Has the Importance of the MEV Track Been Underestimated?
- Telling Stories and Sharing Rights. Can Ctrip Play with NFTs Overseas?
- Opside ZK-Rollup LaunchBase Major Update Supports multiple L1 options such as ETH/BSC/Polygon testnet.
- What is Mantle Network? Ethereum Layer 2 Solution Guide
- Interpreting the Products of Frax Finance and the Synergy between them
- The US Department of Justice accuses SBF of misappropriating over $100 million of customer deposits for political donations.






