Decentralized Identity (DID) Research Report: An Important Practice for Web 3.0 Development
Author: HashKey & TokenGazer
Editor's Note: The original title is " HashKey & TokenGazer | Decentralized Identity (DID) Research Report"
Foreword
This article's Decentralized Identity (DID) Research Report was jointly published by HashKey and TokenGazer.
summary
- Why Libra may be "in the womb": talk about the trend of digital currency, the rise and fall of the monetary system and the evolution of the international monetary system
- Hangzhou Financial Office hosted the blockchain training matchmaking meeting, Babbitt Ma Qianli 45 minutes to explain what is the blockchain
- 2019 Deloitte Global Blockchain Survey: There is no common model for blockchain industry applications, depending on industry characteristics
Decentralized identity system – an important practice in the development of Web 3.0, will promote blockchain technology development and data privacy protection
DID is an important practice in the development of Web 3.0. The core goals of both DID (Decentralized Identity) and Web 3.0 Paradigm are to empower users to control their data, protect their privacy, and ultimately ensure their freedom through an open, anti-censored network. Although DID differs from SSI (self-sovereign identity) in terms of presentation and practice, DID and SSI overlap in most cases.
DIDs are evolved and derived from traditional centralized identities. From a centralized identity to a DID, it has experienced a centralized identity, a federated identity, a user-centric identity, and a DID. The particularity of DID is manifested in three dimensions of security, controllability and portability. Security is reflected in protection, persistence, and minimization; controllability is embodied in presence, control, and permissibility; portability is reflected in transparency, interoperability, portability, and access.
The DID architecture consists of four major components: network protocols, distributed ledgers, DID protocols, and applications. The advantages of the DID technology stack are seven advantages, such as governance structure, independent storage space, and vulnerability to network failures. However, there are also defects such as the risk of loss of private keys, limited scalability, insufficient TPS, and poor user acceptability. In view of the shortcomings of the current DID system, Blockstack, MYKEY, Cambridge blockchain, ShoCard and other projects try to solve the corresponding problems in different ways for different application scenarios.
The development of DID is essentially the result of continuous game and development of benefits and fairness. Technically , the development of DID; application , the future development of DID is that people's desire for data affirmation is getting higher and higher, but it is limited by a series of problems caused by the expansion of user base. Therefore, we believe that in the short term, DID projects will exist more in the field of multi-party games (such as supply chain finance) in the form of 2B; the medium-term will gradually move towards 2C with the solution of benefits and equity; long-term DID in the world A unified standard will be formed to find a balance between efficiency and fairness, and the data will be truly in the hands of users.
1 DID's development background, particularity and inevitability
1.1 Web3.0 and DID
In the book Flash Foresight, futurologist Daniel Burrus puts forward eight major trends in technology development. With the development of the Internet, the trend of virtualization and networking is well proven. The more people socialize, commerce, etc. The more you go online. In the process, many companies have captured trillions of dollars in business opportunities – Google, Facebook, Amazon, Apple, Taobao and so on. They provide Internet technology and services to billions of people in a free way, so the convenience of people's lives has been greatly improved. However, on the other hand, their business model has also caused a lot of controversy. Chris Dixon, head of a16z, believes that platforms such as Google and Facebook will inevitably enter the bottleneck stage of the S-curve in the later stages of development, and then their relationship with network participants (users/third parties) will change from positive and negative to zero-sum game. And as they move into the top of the S-curve, their power relative to users and third parties will grow steadily, and the easiest way to continue to grow is to extract data from users and compete with third-party participants for audiences and profits.
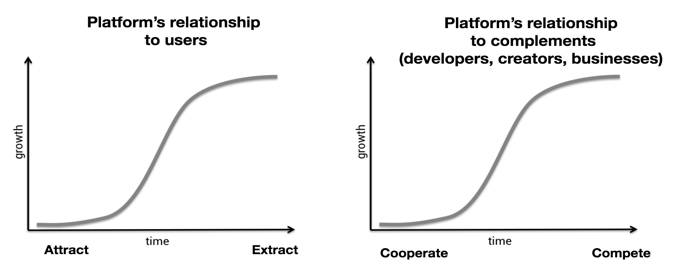
Figure 1: The development phase of the network digital platform Source: Chris Dixon
We do see that such platform companies are getting a lot of profits from their data. There are 2 problems with this business model:
- The platform almost monopolizes and uses user data to make a profit, and only gives a small amount of value to the user;
- After user data is collected, centralized storage exposes user data to significant risks (leakage, hacking, etc.). CSO counts the most significant 18 user data breaches in the 21st century:
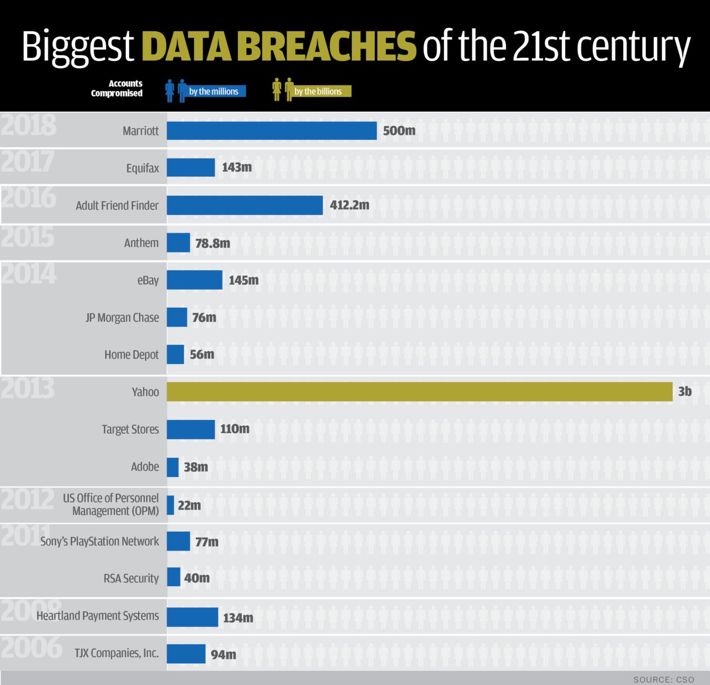
Figure 2: Data breach event statistics Source: CSO
The trend of technology development still makes people more involved in online life, and more and more frequent and increasingly important user data security incidents inevitably make people worry about their privacy and property security – this has become an urgent solution. problem.
Looking back at the development of the Internet, the first phase of the Internet, Web 1.0, was in the 1980s and early 2000s when Internet services were built on open protocols controlled by the Internet community. The second phase of Web 2.0 is from the mid-2000s to the present, software-as-a-service (SaaS) built by for-profit technology companies has become a major part of the Internet. Based on the above-mentioned unfair and data security issues of the existing network business model, more and more people believe that the network needs to enter the next stage of Web3.0, and the emergence of encrypted networks makes this possible.
The core goal of Web 3.0 is to allow users to control their data, protect their privacy, and ultimately secure their freedom through an open, anti-censored network. At present, there are many projects chasing related opportunities in different fields, and the open source code of the encryption community has enabled the related technologies and infrastructure to develop rapidly in just two or three years.
Decentralized Identity (DID, Decentralized Identity) is a very important practice throughout the Web 3.0 landscape.
1.2 Differences and links between DID and SSI
Decentralized identity (DID) is currently not fully accurate in the industry. In essence, it refers to a complete de-intermediation and allows individuals or organizations to fully own and manage their digital identity and its data. The identity of rights and control. Corresponding to the DID is also Self-Sovereign Identity (SSI), which is independent of the service provider and defines the SSI model and existing centralized identity system or There is an essential difference between a federated identity system (such as Google, Facebook, Alipay, etc.), that is, users must exist independently of the service provider.
We believe that the difference between DID and SSI is mainly reflected in the two aspects of literal meaning and practical application. From a literal point of view , DID emphasizes the decentralization feature, and emphasizes that each user in the identity system realizes peer-to-peer interaction through identifiers. There is no single or a group of nodes to control the data generated by all processes, so DID is more focused. In terms of the implementation of the technology and the architecture of the system; SSI is more inclined to the claims of user rights, expressing the user's permission to protect the privacy of personal data and the use of data.
From a practical point of view , DID requires that all aspects of the identity system architecture must be decentralized, including the data storage, verification, and transaction links on the blockchain or distributed ledger, from the underlying protocol. The application to the upper layer is completely decentralized; SSI only advocates that users can control their own identity and related data. In other processes, there may be centralized links, such as centralized operation and centralized storage under the blockchain. Centralized third-party unified certification.
The connection between DID and SSI is that both are used in the identity system. Most projects are the embodiment of DID and SSI. DID is the implementation of SSI in the technical architecture, and SSI is the value proposition of DID. Therefore, the second chapter and the third chapter of this paper introduce the centralized identity and decentralized identity (DID), and use DID to represent and analyze and discuss from the perspective of technology implementation.
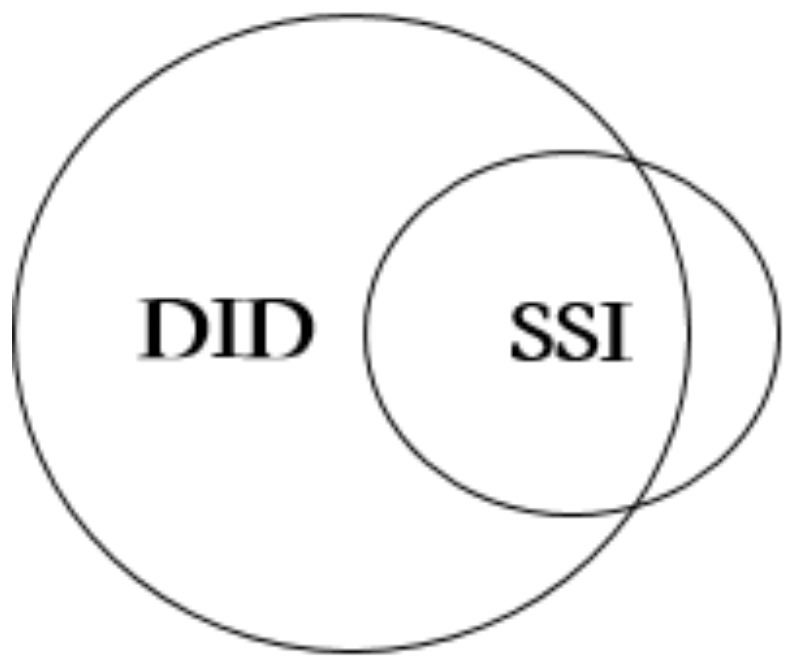
Figure 3: Relationship between Decentralized Identity (DID) and Self-Sovereign Identity (SSI) Source: HashKey Capital Research
1.3 The evolution process from centralized identity to DID
With the popularity and development of the Internet, digital identity plays a vital role in our lives. Digital identity with the user's awareness of identity control and self-protection has resulted in four forms: centralized identity, federated identity, user-centric identity, and decentralized identity (DID).
(1) Phase 1: Centralized identity
Centralized identity data is managed and controlled by a single central authority. For example, our VX number, Alipay account, etc. Obviously, the essence of centralized identity is that centralized authorities have the right to use and interpret identity data, and they can determine whether a user has a certain identity and its identity. Digital identities are owned by certification authorities, domain name registries, and websites.
Obviously, with the continuous development of the Internet and the increasing number of websites, the centralized identity brings a lot of confusion and restrictions. The user's various digital identities are randomly scattered on the Internet. Since the user's identity and related data are not controlled by the user, the privacy of the individual cannot be effectively guaranteed.
Today, most of the identity on the Internet is still a centralized model. We may register an account on a website or platform the day before. Maybe the next day there will be a related sales or harassment call asking if we need related services. What's more, the use of relevant information to counterfeit identity for illegal activities such as online fraud and money laundering. Over time, as people's awareness of self-protection of personal data and information continues to increase, centralized identity is difficult to meet the needs of individuals or organizations on the Internet.
(2) Second stage: alliance status
The disadvantages of data confusion caused by centralized identity have spawned an identity system controlled by multiple agencies or alliances. In layman's terms, the identity of the alliance makes the user's online identity data a certain degree of portability. The Passport program, introduced by Microsoft in 1999, first introduced the concept of alliance identity. Alliance identity refers to the digital identity of a user who is jointly managed by multiple organizations. For example, the website platform such as Pinto and Sina Weibo authorize an instant messaging software account as a third-party login account.
Although the alliance identity solves the problem of controlling the identity data of a single digital identity provider to a certain extent, it only distributes power from a single node to at least a few super nodes, forming an oligopoly of user identity, once these super nodes are formed. Collusion, there will still be hidden dangers caused by the centralized identity mentioned above, the user's identity data is still controlled by the central organization, and users still have no control over their digital identity.
(3) Phase III: User-centric identity
The purpose of the user-centric identity is that the identity service node can determine the identity storage and use and identity portability through user authorization. Therefore, this type of digital identity focuses on three elements: user permissions, interoperability, and based on the user's complete grasp of the data.
However, the user-centric identity model has not been successfully implemented for two reasons: on the one hand, the mode is weak in preventing "phishing" (electronic fraud); on the other hand, the technology used in this mode has a higher threshold. . So most users still prefer to use the first two types of identities.
Taking OpenID as an example, users can theoretically register their own OpenID, and any website can act as an identity provider for OpenID. On the one hand, when logging in to a website that claims to support OpenID, the user may send the entered username and password to the fraudulent web page; on the other hand, OpenID relies on the URL identifier of the correct machine routed to the Internet, which in turn depends on Domain name resolution system for network address mapping, but this system has security risks.
(4) Stage 4: Decentralized Identity (DID)
Since the digital identities of the above three stages are more or less dangerous in security, DID has emerged, and different DID systems have been designed to be applied to different business scenarios according to the particularity of different industries.
1.4 DID's value proposition
The DID industry is currently in the early stages of exploration and there is no clear definition, but we can understand it from the goals it seeks.
Today, the activities in our lives and work need to be increasingly carried out through web applications, and they often need our digital identity. As mentioned earlier, our identity information and our other online activity data are recorded, owned and controlled by others, some of which we don't even know.
DID advocates that everyone has the right to own and control their own digital identity, which securely stores elements of their digital identity and protects privacy. However, it is not easy to implement DID, which involves the discovery, identification and verification of identity, trusted storage and calculation of related data, identity declaration and credentials, and so on.
1.5 DID specificity
DID differs from the other three identity modes in three ways. They are security, controllability and portability.

Table 1: Particularities of DID Source: Hashkey Capital Research
In terms of security , DID protects user personal data and limits data exposure to the lowest level of functionality. It includes the following three dimensions:
- Protective . That is, the user's rights must be fully protected. When identity network requirements conflict with the rights of individual users, the network should give priority to protecting the individual's freedom and rights.
- Permanent . Identity must be lasting. It is best to be sustainable, at least for the time nodes that the user expects, to avoid "forgotten rights," and the user decides on the deletion and deregistration of the ID, not just the registration and creation of the ID.
- Minimize . Identity data information needs to be provided to control the minimum level of functionality that the user needs to implement. For example, in real life, when we enter the Internet cafe, we need to provide an ID card to prove that "you are an adult", but the ID card has extra information such as the home address and ID card number in addition to the date of birth of the user. , resulting in information leakage caused by excessive information. However, we only need to provide proof of birth date "I am an adult".
In terms of controllability , the user is completely independent of the identity provider and other institutions. The use of identity must be approved by the user, and the user can fully grasp and control his identity data. Includes the following 3 dimensions:
- Existence . Users must exist independently of any other network participants. DIDs never exist as numbers. It simply exposes certain limited aspects of the existing “self” and makes it accessible.
- Control . Users have control over all operations such as registration, use, update, deletion, and logout of DIDs. The user is the highest authority of his own identity, and chooses whether the information is open or not according to his or her own preferences, and even hides his identity. But this does not mean that the user can grasp all the statements related to his identity, other users can also make a statement to the user, but this should not be the core of the identity itself.
- Licensing . Any network participant who uses the user's identity and its associated data must obtain permission from the user. And the data can only be shared with the user's consent. In addition, the license must be well thought out and easy to understand by the user.
In terms of portability , it includes four dimensions of transparency, interoperability, portability and access rights.
- Transparency . Code such as DID systems and algorithms must be transparent (open source). On the one hand, the way the DID system works and the way it is managed and updated must be open; on the other hand, the algorithm should be free, open source, accessible to anyone, and as independent as possible from any particular architecture, anyone Both have the right to supervise the working process of the algorithm.
- Interoperability . DID should be used extensively. If it is only limited to be effective in a limited market segment, then these identities have no value.
- Portability . DID information and services must be portable. The alliance identity mentioned above adds portability to the foundation of identity. In contrast, identity cannot be held by any SuperNode. Therefore, the portability of DID is that the user can migrate the corresponding identity according to his or her own needs, instead of the authorized third party login of the federation identity.
- Access rights . That is, users must be able to access their own data and only have access to their own DID data. The user's full understanding of the DID and its associated verifiable claims does not mean that the user must modify all claims related to his or her identity. Specifically, the user must be able to easily retrieve all claims and other data in his or her identity at any time. There must be no hidden data in the process of recovering the data, and no other participants should guard the data.
1.6 The inevitability of DID development
This paper believes that DID development inevitability has two main points: accurate data reconstruction for all walks of life (supply side) and people's awareness of privacy protection of personal data (demand side).
(1) Accurate data needs to be institutionalized for the reconstruction of all walks of life
As the saying goes, it is necessary to get rich first, and in the age of informationization, data is like a road. The current Internet business model is generally to use its data resources to open up the channels of its application, thereby obtaining traffic and earning. profit. The Internet is no longer a tool-based technology to provide efficiency and profit, but an institutionalized technology that constrains its code of conduct. Similarly, the Internet of Things and accurate data must be used to restructure the business model for all industries. The Internet of Things and accurate data must be institutionalized, and DID plays a vital role in its institutionalization process.
At present, the path of information technology development is shown in Figure 4. As the gradual coverage of 5G networks will bring the development of animal networks, the coverage of the Internet of Things enables all industries to obtain accurate (accurate and timely) data at any time. Data is the basis for the development of the artificial intelligence industry. DID is of great significance to the construction of the Internet of Things and accurate data systems. Massive data will inevitably lead to data distortion and security risks. The biggest premise of cloud computing is to ensure network and data security, to provide specific data to specific groups, and the centralized identity system can not meet this. DID's reconstruction of the business model of all walks of life is that the data disclosed by enterprises or individuals only need to meet the trading conditions, without exposing more information, which is conducive to the confidentiality of trade secrets and promotes a virtuous circle of industry competition ecology.
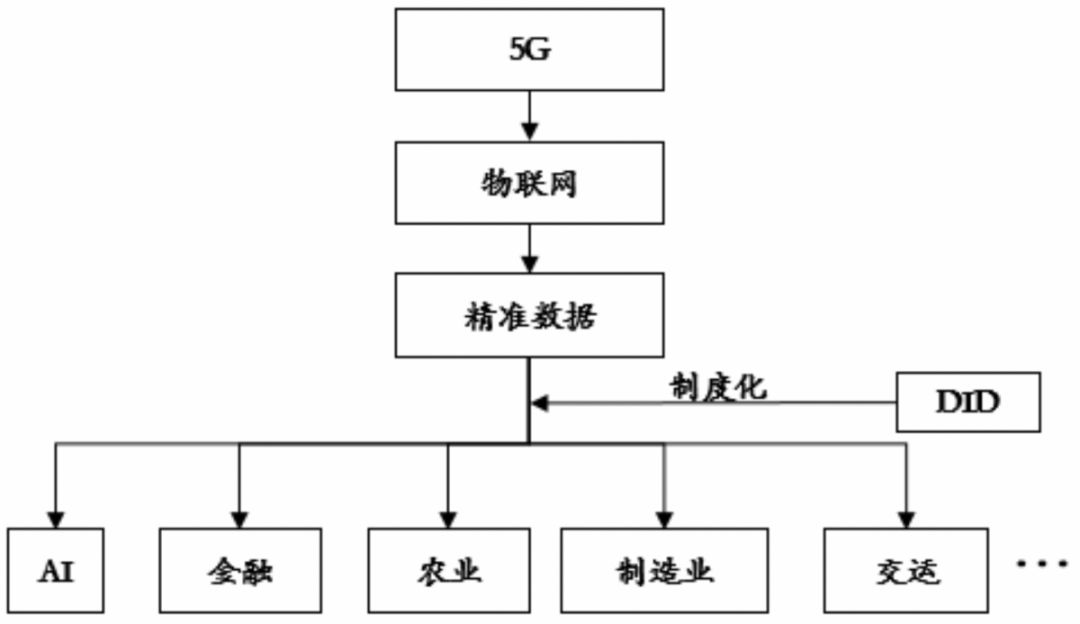
Figure 4: Reconstruction of Accurate Data across Industries Source: Hashkey Capital Research
The major breakthrough brought by 5G is that the process of reconfiguring accurate data for all industries will accelerate. In the case of automatic driverless driving, the realization of true autonomous driving is definitely not simply to install the GPU. It also needs to transmit data to the cloud instantaneously through 5G and the Internet of Things for cloud computing and mass computing. In the process of cloud computing, DID can ensure the accuracy and timeliness of data through data deduplication, and to minimize the data supply to a certain extent, reduce data redundancy, thereby reducing computing costs and improving the operation of automated algorithms. effectiveness.
(2) People's awareness of the protection of personal data is increasing
There is no doubt that people's awareness of the protection of personal information data will gradually increase. Although the speed of reinforcement is still subject to people's mental and psychological constraints, it seems that the process of increasing the awareness of personal data protection is very slow, but this psychological constraint is like the gate of a dam. People's awareness of the protection of personal data spreads and develops like a flood.
In the "Bizarre Behavior", Ai Ruili pointed out that people will only be sensitive to the marginal loss and the direct cause of the loss, but will turn a blind eye to some indirect causes of marginal loss. At present, the vast majority of people are not very concerned about the leakage of some seemingly “insignificant” information, such as personal shopping consumption records, ID numbers, mobile phone numbers and genders, because the disclosure of such information cannot be directly brought to people. Loss of interest, but often has a cumulative effect on triggering marginal losses. Many online scams, hackers, and crimes are accumulated step by step using this information, not a day's work.
Taking online fraud cases as an example, many websites use shopping as a cover for fraud. However, many centralized platforms or internal personnel of the platform sell data to third parties while grasping data such as user shopping records. The evil node uses online shopping data to attract customers who are in love with low prices at a low price, and use a lot of money to run in the case of traps such as shopping vouchers and deposits. The basis of the accurate prediction of the consumer shopping recommendation algorithm is the positioning of the feature attributes between the user's shopping information and the registration information, and the consumers are clustered. These feature attribute data can not bring us direct economic losses, but the wicked use these The data positions our consumption habits so that we can more accurately use our consumer psychology, making it easier for us to believe in the lie of fraud, which in turn leads to economic losses.
The best way to solve the problem is to find the source of the problem. The source of the problem is that the user cannot control the personal information data autonomously, and ultimately the probability of economic loss increases. The reason why cyber fraud cases are repeatedly deceived is not that people's security awareness is not enough, but neglect of indirect reasons. But because most people ignore it now, the DID of data protection does not solve the problem of human nature to some extent. However, with the development of the information age, once people begin to face these "insignificant" indirect reasons, DID-related projects can quickly land. It is fair to promote the loss of benefits.
2 Centralized identity system
2.1 Centralized identity system business process
The most important feature of the architecture of a centralized identity system is the system in which one or more central authorities control user identity and its associated data. The centralized identity and federated identity systems mentioned above are all within the scope of a centralized identity system. Taking an instant messaging software Auth2.0 to authorize a third-party application as an example, as shown in Figure 5, it is divided into the following steps:
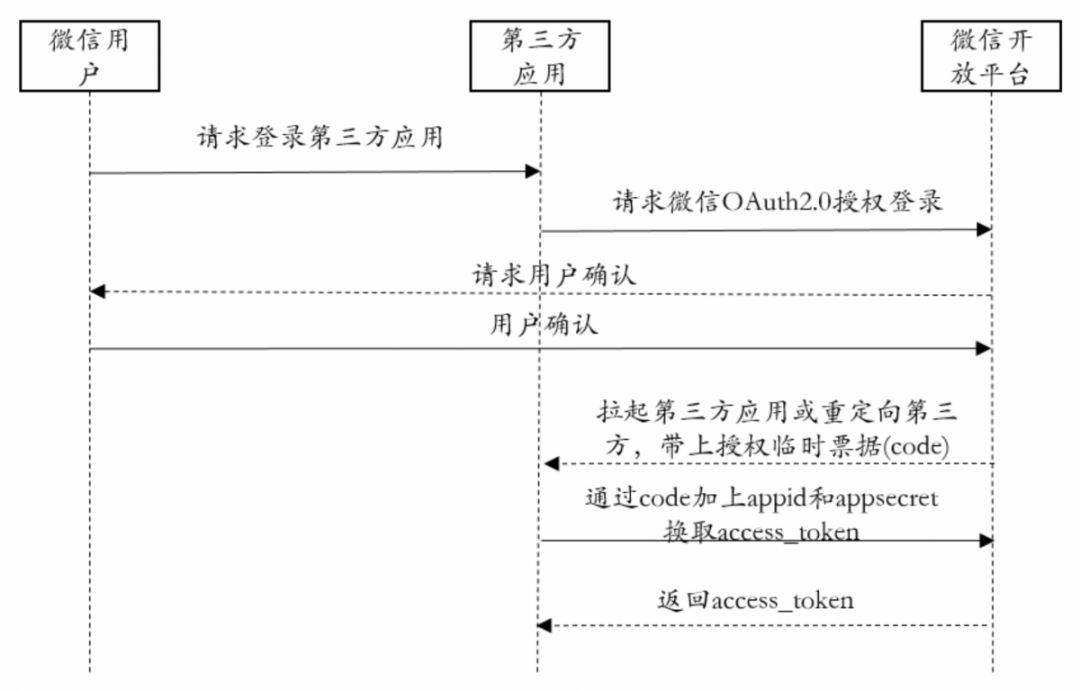
Figure 5: An instant messaging software OAuth2.0 authorizes login to third-party applications Source: Hashkey Capital Research
- An instant messaging software user sends a request to a third-party application to "log in to a third-party application";
- The third-party application requests an OAuth2.0 authorization login to an instant messaging software open platform (such as a public number);
- The platform requests the user to confirm the login request information;
- After the user completes the confirmation to the open platform, the platform issues a request for “pull up a third party application” or “redirect a third party” to the third party application, and authorizes a temporary ticket (code);
- After the authorization server verifies that the code has passed, it agrees to authorize and returns a resource access certificate (access_token);
- The third-party application requests related resources from the resource server through the fourth step of the access_token;
- After the resource server authentication credential (access_token) is passed, the resource requested by the third-party application is returned.
It can be seen that the user's ability to control the data is very weak. On the one hand, you need to log in with OAuth2.0 authorization (with the right to grant a certificate, that is, the license); on the other hand, the access_token needs to be exchanged for the open platform.
2.2 Defects in the centralized identity system
Starting from the particularity of Section 1.5 DID, OAuth2.0 authorizes the third-party login process to add certain portability and accessibility only based on the centralized identity. The user does not have control over the identity. Disclosure of information does not have permission, and it is not possible to minimize the degree of information disclosure while satisfying the function. Therefore, the centralized identity system has major drawbacks.
In addition, the centralized identity system is susceptible to external factors, which can seriously affect the availability of the entire system, and even lead to paralysis of the entire system. Taking the centralized access management platform of the Internet of Things as an example (Figure 6), the transfer of information between devices between different IoT zones needs to be verified through a centralized identity management platform, so there are several factors that can lead to identity. The availability of the system is greatly reduced:
- Broken network . In the case of a broken network, verification cannot be performed between different devices.
- The centralized platform is likely to be overwhelmed . When different devices frequently transmit information, the data brought by the information is massive, and the system is likely to be overwhelmed, but with the launch of 5G or even faster traffic platforms, the problem will be alleviated to some extent.
- Single point of failure . A centralized identity management platform is like a series circuit (Figure 6). Once a single point of failure occurs, the operation of the entire system is severely hampered.
On the contrary, the DID management system can effectively verify these problems even if there is a single point of failure or network disconnection, and the different devices can still be verified.
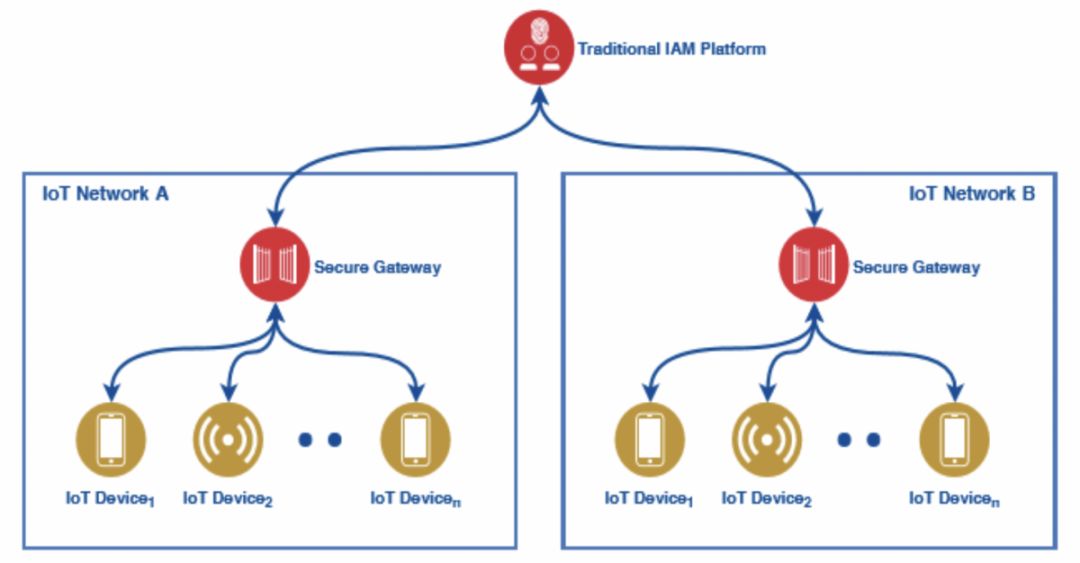
Figure 6: Centralized identity management system is vulnerable to external factors Source: Uniquid White Paper
Although a recent instant messaging software has issued a new regulation on user privacy: prohibiting red envelopes, coupons, and points as rewards for users to perform corresponding actions on the platform (such as forwarding, reading, commenting, etc.); Reward; use of any vulgar speech is prohibited. The new policy is to restrict the behavior of other behavior organizations or individuals from invading personal privacy from the perspective of user behavior. The storage of data, the recording of transfer transactions, and the verification of information are all carried out on the server of the centralized platform, and cannot be the same as DID. Fully empowered. With the Internet giants in Europe and the United States (such as Facebook, Google, etc.) gradually comply with the stricter GDPR standards, it not only restricts the behavior of people infringing on data privacy, but also restricts the use of AI algorithms to invade user privacy. This is a big improvement, but it still needs further improvement.
3 Decentralized identity system
3.1 Decentralized Identity System Participants
This article uses the DID system as a representative to explain the decentralized identity system architecture. The participants in the DID system have users, identities, verifiable claim initiators, and trusted parties. Contrary to the centralized identity system mentioned above, the service provider, the traditional centralized identity management platform (Traditional IAM Platform), is not centered on its operators, and the DID system is user-centric.
As shown in Table 2, the verifiable statement initiates the verifiable assertion of the user's identity after verifying that the user's specific feature attributes (such as gender, age, etc.) are correct. Any trusted party (verifier) who needs to authenticate the user will receive a verifiable statement and verify its authenticity. The premise that the identity management system can operate effectively is that the trusted party must establish a trustworthy relationship with the claim initiator. Suppose that Tom needs to register an account (identifier) on the identity management platform. In the DID system, Tom can control its own identity and its related data, and has ownership, access and access rights to it when the statement originator sends out When Tom declares an account with an ID identifier, the identity must be presented to the verifier who establishes a trusted relationship with the claim initiator and objectively verify the true or false of the claim.

Table 2: Participants in the DID Identity Management System Source: Hashkey Capital Research
3.2 DID System Architecture and Operation Process
The foundation of the DID management system architecture is a distributed ledger and DID protocol based on blockchain technology. Obviously, the DID system is user-centric. The operation process of the DID system is shown in Figure 7, which has the following characteristics:
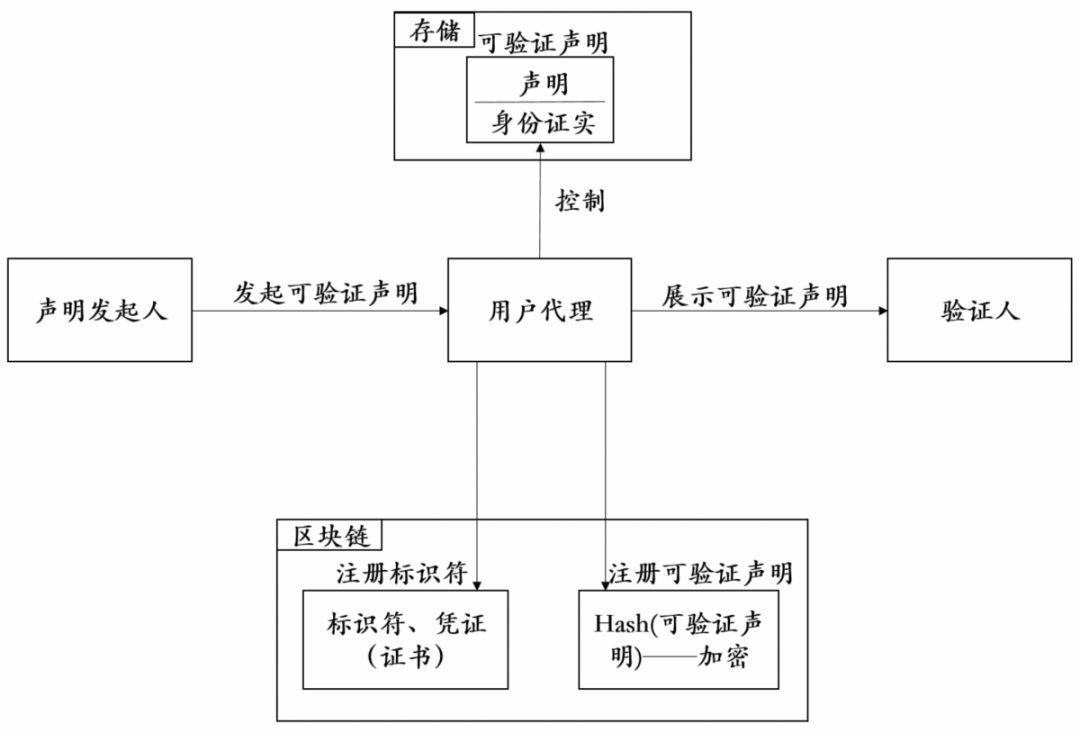
Figure 7: DID Identity System Operational Process (Identity Registration) Source: Hashkey Capital Research
- The user has absolute control over the stored database of verifiable claims. The identity verifiable statement is stored in a user-controlled storage area (generally a database). For the protection of user privacy, it is usually stored under the chain, and the encrypted information is summarized into the chain. The trusted party (verifier) can compare the publicly available identifier with the identifier in the statement submitted by the user to him. After authenticating the user using the authentication method provided in the public chain, the statement itself can be verified by the trusted party (verifier), and finally the result of passing the verification or rejecting the verification is given.
- The blockchain not only has the ability to provide users with the ability to register identifiers on the chain, but it also allows the user agent to register and encrypt the verifiable claims. On the one hand, the user encrypts the user's identity identifier and related digital certificate on the basis of providing minimum personal information (satisfying the function of determining whether the user can register the identifier), and each node is It performs accounting; on the other hand, the user agent also stores the registration verifiable statement on the chain, encrypts the verifiable statement through asymmetric encryption technology, and further protects the privacy of the user data.
In summary, in the process of registering the DID, it is not necessary to store any information related to the user's individual on the claim originating node or the verifying node, and the DID system can be made to operate normally by establishing a trust between the initiating node and the verifying node in advance.
3.3 DID system technology stack
The technical stack of the DID system has many components, and there are big differences between different projects, but the basic components are indispensable. Among them, the components that are common to all projects are the basic components and optional components. (Figure 8)
In general, the current technology stack of all DID systems is a bottom-up structure, the bottom layer is the network protocol (usually TCP/IP), and the upper layer is the blockchain or distributed ledger, and then the previous one. The layer is the DID protocol, and the top layer is the application software (applications such as DApp and App).
Among them, the DID protocol is the core part of the entire decentralized identity system, and it is also the basis of a particular DID system different from other DID systems. In general, simplified DID protocols include decentralized identity identifiers, verifiable claims, public key infrastructure, and storage schemes.
- Decentralized identifiers (DIDs) : In general, identifiers are equivalent to nicknames in a centralized identity system, but the most significant difference is that accounts are controlled by their operators, while DIDs are controlled by users in the Web 3.0 paradigm. And completely independent of the identifier vendor, certification authority (CA), certifier and other participants.
- Public Key Infrastructure (PKI) and Private Key : Generally speaking, the DID system has both a public key and a private key, which is equivalent to an account and password in the context of Web 3.0. Public Key Infrastructure (PKI) involves all the functions of registering, revoking, deleting, and authorizing access to public keys in Section 3.2, and promoting infrastructure that enables these functions to be more efficiently implemented, such as state machines, verification authorities, and digital certificates. And Token tokens, etc. The private key is a password, but in general, the private key cannot be retrieved once it is lost (with the exception of MYKEY). The storage structure of the public key infrastructure and private key will determine the security of the DID system.
- Verifiable Declaration (VC) : Refer to VC in Section 3.1.
- Storage scheme : The storage scheme is divided into two categories : centralized storage scheme and decentralized storage scheme. The choice of data storage scheme is the decisive factor of the whole project business model and ecological development. In theory, decentralized storage solutions will break the traditional Internet by monopolizing the identity and data of users. As we all know, the Internet giant (BATJ, etc.) has monopolized user data and traffic through a centralized storage solution, thus subverting the business model of traditional entities. Participants in all aspects of the DID system must access the user's data and must pass the user's permission. The important data of the user is stored in the chain or local to the user node. In fact, the blockchain can't support massive data storage, so most projects choose to store the data under the chain, generally independent storage space such as the cloud, while the vendors and service providers that control the cloud will monopolize the data. Users only constrain their power, and users are relatively passive in centralized storage compared to decentralized storage.
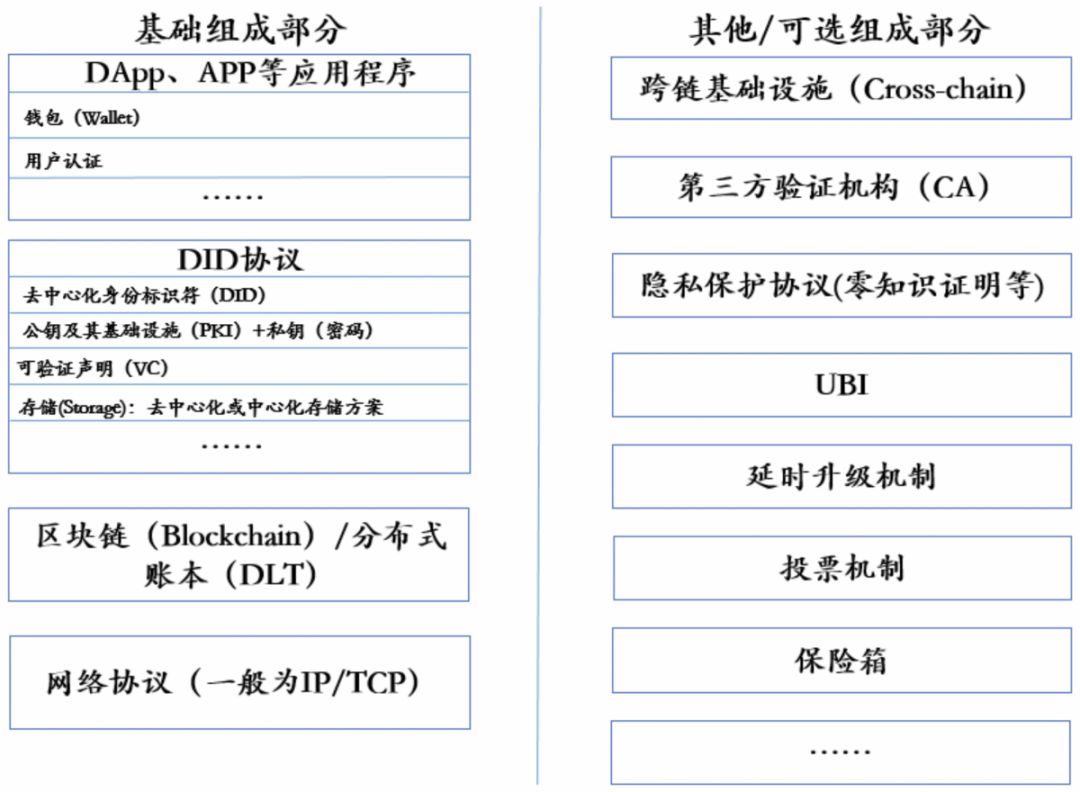
Figure 8: DID System Technology Stack Source: Hashkey Capital Research
3.4 Advantages of the DID System Technology Stack
The DID system is user-centric and has the following advantages based on the 10 specificities mentioned in Section 1.5:
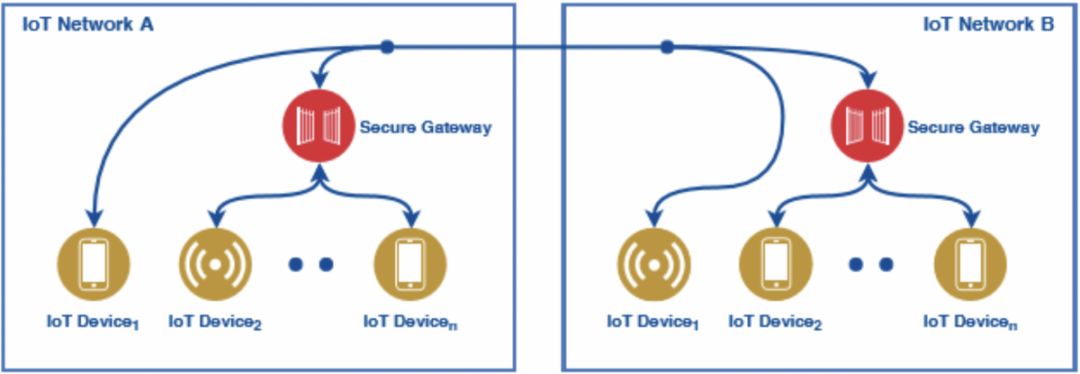
Figure 9: DID management system is less susceptible to external factors Source: Uniquid White Paper
- Not susceptible to network partition failures, single points of failure, and network disconnection (Figure 9) . For the underlying network protocol (IP/TCP), information transfer, verification, and value transfer can still be performed between different nodes in the event of a single node failure or network disconnection.
- The governance model of DID is better than the existing governance model of blockchain or distributed ledger, which is conducive to the realization of data equality. Because DIDs do not rely on a specific type of blockchain distributed ledger technology (DLTs), they can be used with any blockchain or DLTs that can satisfy the underlying principles. In the incentive system, DID can make the user participate in the expansion process of the network through appropriate incentives, and has the rights of permission, access and income. The user has the right to share the dividend brought by the network effect.
- DID can make up for the shortcomings of traditional public chain TPS by constructing independent storage space, and can even process data efficiently under the chain. For example, Blockstack provides developers with an innovation-driven development network environment by building decentralized storage space and distributed ledgers. It expands the network's TPS and efficiently stores core data under the chain, making it less vulnerable to hackers. Especially when the DID project is on the 2B side (private chain or alliance chain), its processing efficiency will be greatly improved.
- DID strictly adheres to the privacy protection agreement of the high standard of GDPR in compliance. By establishing a data usage mechanism based on the user's license, the user can provide corresponding information according to his or her actual situation, and complete the exchange function of the verifiable statement, so as not to disclose other core information such as the ID number, the mobile phone contact information, and the date of birth. At the same time, regulators or authorities can act as verifiers, which is beneficial to regulation and reduces the space for money laundering and crime.
- DID increases the cost of malicious nodes. The DID is stored in the blockchain by summarizing the user's activity into a header, and establishes an effective monitoring mechanism and consensus mechanism through the distributed ledger. Once the malicious node wants to steal user information through hacking methods such as 51% attack, Digital currency assets, their behavior will soon be exposed by multiple verifiers.
- DID has a certain degree of portability. With the gradual maturity of cross-chain technology in the future, DI D will be authorized to log in to other applications like an instant messaging software account or Alipay account, and users can control their own identity.
3.5 DID System Technology Stack Challenge
DID system solves the problem of humanity to some extent, in the era of further data interconnection and interoperability, it will help improve the authenticity of data, protect the privacy of user data, and effectively reduce external factors (such as network disconnection, network The negative impact of partitioning, etc.). However, the DID system in the case of improving the fairness mechanism, the decline in efficiency is still the challenge of the DID architecture.
- Data throughput is not sufficient to support the calculation of massive data, and is not applicable to applications that require low latency. At present, for the blockchain projects that have already landed, only EOS can achieve a data throughput of 2,500 times/s through the consensus mechanism of DPoS. At present, most of the applications of artificial intelligence stay in static applications, which is still insufficient to It changes people's existing productivity and production relationships, and dynamic applications require massive amounts of data for cloud computing, enabling real-time processing. In addition, the popularity of 5G traffic or the further upgrade of mobile networks can only expand the bandwidth of the network, but the consensus delay based on blockchain technology is still unavoidable, resulting in greatly reduced efficiency of the entire DID system, so it cannot be used in the field of automatic driving. .
- DID is in some way inconsistent with data sharing, which may further aggravate information silos and even increase the challenge to the regulatory authorities. In many cases, data sharing and user data privacy protection are conflicting. Although the DID system protects the user's absolute control of personal data to a certain extent, users will no longer disclose more personal information because of the protection of privacy rights. But it also hinders the sharing of data, and even many gray areas and underground economic activities are likely to be more embarrassing because of privacy protection. Although DID has made a major breakthrough in protecting users' personal privacy, it also raises the difficulty of supervision. The convenience of supervision and the protection of users are always both. The blockchain system can only use the timestamp to ensure that the information cannot be falsified after the information is input. The transaction is not repeated, but the source of the information cannot be controlled. The DID is currently not legally effective. Once the regulator asks for changes to inaccurate information, it cannot be tampered with but is difficult to implement.
- Decentralized identity is less acceptable to users and operations are largely inferior to centralized identity systems. Wilcox-OHearn's impossible triangle theory states that the decentralized identifier (DID) readability, high degree of decentralization, and system security cannot be met at the same time, and most current projects are at the expense of accounts. Readability to meet the security and decentralization of the system, which leads to lower acceptance of identifiers (accounts). First, identifiers generated based on random numbers rely on probabilities to avoid collisions. Second, centralized identifiers use registration privileges to assign identifiers and prevent conflicts.
- Data stored on the chain is prone to data leakage and the risk of private key loss. In order to prevent the risk of disclosure of associated information, even in the form of encryption, private data is not stored in the chain or in the distributed ledger. Only anonymous identifiers (DIDs), anonymous public keys and proxy addresses are placed on the chain to make all private data. The exchange is carried out outside the books. In addition, private data encryption stored in the chain is vulnerable to attack and easily lead to private key leakage, so important data should be converted under the chain.
However, due to the differences in application scenarios and implementation methods of different projects, the limitations of different DID projects have different impacts on project development. In Chapter 4, the following items mitigate or overcome one or more of the above four problems with different scenarios. In the future, the main direction of the development of DID projects and even the entire blockchain technology is to find a better balance between efficiency and fairness, and to achieve data affirmation on the basis of ensuring efficiency.
4 DID project introduction and analysis
4.1 Industry Segmentation
There are many criteria for the classification of DID project industry classifications, including the division of B2B and B2C, and the division according to the application of the industry (sub-category of vertical suppliers), and the division of functions according to its implementation (such as wallet suppliers, Verify suppliers and infrastructure vendors, etc.). Naturally, a classification may contain multiple DID projects, and a project may be laying out or about to deploy multiple businesses and apply to different industry sectors, so the DID project business and the DID project itself are many-to-many relationships.
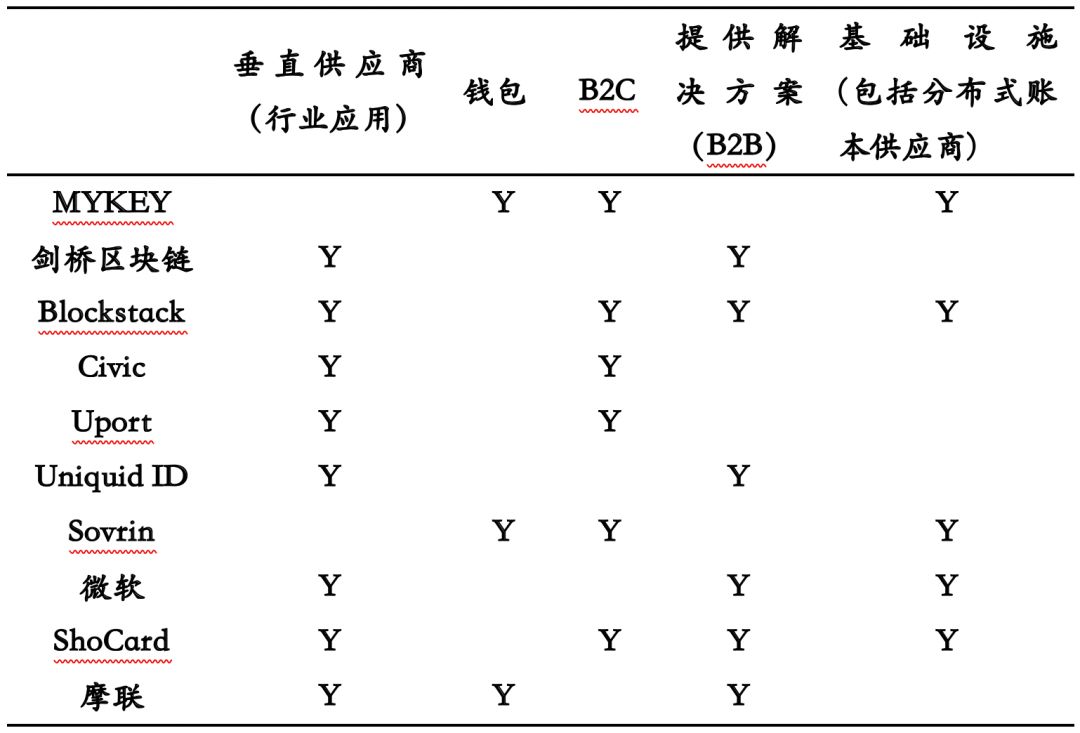
Table 3: Related Project Business Classification Data Source: HashKey Capital Research, TokenGazer
Note: where Y means Yes, that is, the project is carrying out the business.
4.2 Project Analysis
4.2.1 Blockstack
(1) Project introduction
Blockstack aims to build a distributed computing network that replaces traditional cloud computing with a full stack. Based on Blockstack's decentralized application (DApp), most of its business logic and data processing is done on the client, not the centralized server. The Blockstack team is committed to building a complete ecosystem that enables decentralized application development, data storage, and authentication, decentralized to address the trust of traditional Internet and has comparable performance to traditional Internet. More secure.
(2) Project technical plan
The Stacks blockchain is the foundation of the entire network, using Tunable Proof-of-Work, which optimizes security and predictability with a new smart contract language and allows Static analysis of all transactions. Gaia is a highly scalable, high performance decentralized storage system that provides users with a private data locker; the Blockstack authentication protocol is a decentralized authentication protocol in the system through which users can use their own The ID is authenticated and you can set which Gaia server to use to save the data; the SDK and developer tools make DApp development easier, and developers don't have to worry about server or database operations.
Blockstack provides users with a common username for logging in to all applications without any passwords. Unlike password-based authentication, Blockstack users use public keys for authentication and sign authentication requests. The authentication protocol Blockstack Auth connects the application, the user's Gaia hub, and any application-related private keys. The application uses this information to save users and data and verify the authenticity of data generated by other users.
Blockstack Auth uses public key cryptography for authentication. The user logs into an application that can generate and store signed data, and other users can read and verify the data and prove to other users that the logged in user is legitimate.
Blockstack builds a system that developers can't do by adopting the following design:
- Decentralized Domain Name System BNS (Blockstack Name System). Using blockchain technology to build a global system like DNS in a completely decentralized way, no company can review a website or forcibly deprive a domain name of ownership.
- Decentralized storage system Gaia. Gaia provides new uses for existing cloud storage service providers and delivers performance that matches existing services.
- A decentralized system built on the basis of applied cryptography. This technology is becoming easier to use in managing private keys and software.
As shown in Figure 10, the users in the Blockstack ecosystem manage their own data and identity information. When they log in or use the application, they will authorize the DApp to read the information. The developer has no access to the user data information, which basically eliminates the use of user data. Do the possibility of doing evil.
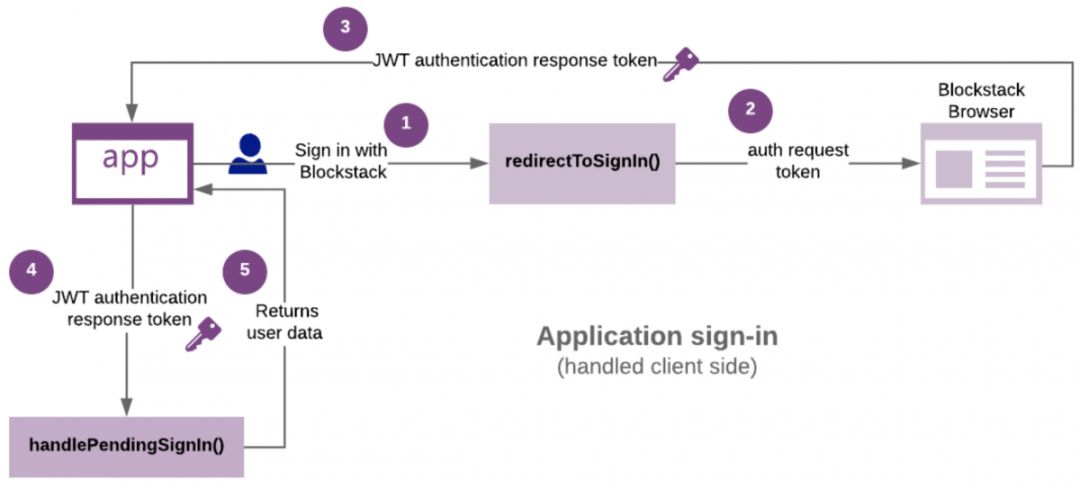
Figure 10: Blockstack Operational Process Data Source: Blockstack Official Website
(3) Project evaluation
Blockstack provides the user with a generic username that can be used for all applications without any password. Unlike password-based authentication, users authenticate using public key cryptography: a locally running software client processes login requests from specific applications and signs authentication requests. Blockstack's design philosophy is the same as Web3.0's user-controlled data, user and platform affirmation, and may be an important project in the Web3.0 framework in the future.
4.2.2 MYKEY Identity Management Platform
(1) Project introduction
MYKEY is an autonomous identity system based on multiple public blockchains. The system is based on the Key ID autonomous identity protocol. The Token in the protocol is KEY. For example, use KEY to purchase network fees, lock KEY to obtain membership rights.
From the asset dimension , MYKEY is a multi-chain wallet that allows users to take full control of their assets and freeze and recover accounts when they lose their private keys. From a trust network perspective , MYKEY is part of a trusted network. At the same time, MYKEY returns data sovereignty to users in the context of Web 3.0, protecting user privacy from the ground up.
(2) Project structure
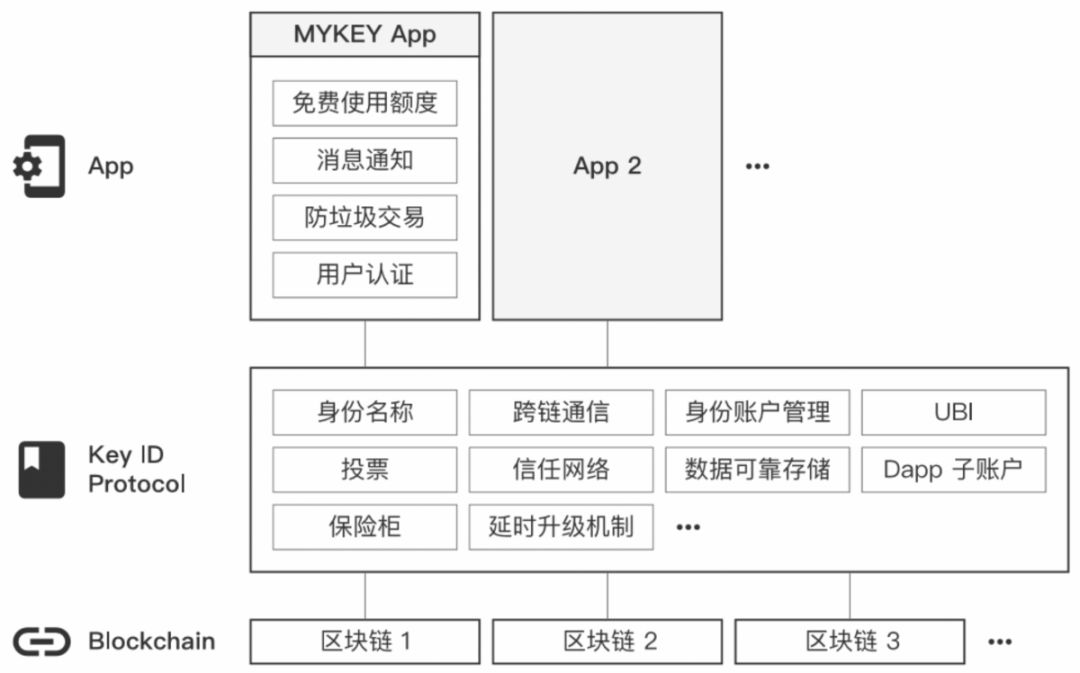
Figure 11: MYKEY Technology Stack Source: MYKEY White Paper
- MYKEY application layer
MYKEY has three main functions in its application: multi-chain wallet, trust network and reliable storage of data, which is operated by profitable company MYKEY Lab.
- The multi-chain wallet multi-chain wallet serves multiple wallets with known public chains and supports multiple smart contract platforms. Because MYKEY accounts exist as smart contracts on every blockchain, MYKEY wallets do not support non-intelligent contract platforms (such as BTC, etc.). Multi-chain wallet has the following characteristics : unified identity name, free usage quota (lower usage threshold, metered by network fee – usage right), mutual checks and balances to ensure account security, private key loss recovery mechanism, agreement Upgradeability, anti-spam transactions.
Because there is no cross-chain function, MYKEY uses the central conversion method to realize the use of KEY certificate on multiple chains. The specific method is as follows: MYKEY Lab locks part of the KEY owned by itself in the Ethereum blockchain, and generates the same amount of mapping certificate on other blockchains, and provides convenient conversion services to make the map pass and KEY There is a 1:1 interchange between them (except for handling fees).
In terms of personal data records , personal data is fully recorded in the storage security zone. Because the data security zone is based on decentralized storage technology and is completely controlled by the smart contract of account identity, it is in line with the licensing characteristics of self-sovereign identity, and users can determine sharing in advance. The way;
On the DApp side , some or all of the data of the DApp is stored in the decentralized storage area. Access to the data requires authorization of the identity account. Some interactions with the DApp can also be stored in the own data security zone under the identity account.
- Key ID protocol
The Key ID protocol was deployed by MYKEY Lab, and in return, MYKEY Lab received 10 billion initial KEYs. The agreement hopes to solve the user's private key management problem by providing an easy-to-use, secure, fault-tolerant solution to establish the user's identity in the blockchain.
Key ID has no centralized hosting, but completely realizes the user's self-identity management through smart contracts. The contract is open source and audited by several security service providers, including the following four innovative features.
- Permission separation settings . MYKEY splits the user's chain permissions into administrative and operational permissions. Operational privileges are used for daily operations such as transfers, mortgages, etc. Administrative rights are the highest privilege of an account, but administrative privilege can only modify the user's privilege, but not directly manipulate account assets and daily operations.
- Hierarchical key management . Once the MYKEY management private key (recovery code) is exported, it will be stored offline forever. MYKEY recommends users to copy multiple copies or use hardware wallet management. The operating private key is closely tied to the user's smartphone. The user does not need to care about the technical implementation details, and only needs to provide the account password or the correct biometrics to retrieve the operating private key.
- Trusted recovery mechanism . In order to avoid the immediate consequences of the loss of the private key, a certain delay is required in the Key ID protocol to replace the private key. At the same time, MYKEY provides an emergency contact mechanism. After the out-of-chain identity authentication, a set of emergency contacts that reach the threshold number can help to quickly replace the key, and can also assist in re-acquiring management rights when the management private key is lost. Time). In addition, Key ID smart contracts are open source and subject to audit by authorities to minimize code vulnerabilities.
- Risk response system . In the MYKEY system, under the MYKEY system, MYKEY provides solutions for risk events such as user negligence, hacking, and theft. It can handle mobile phone loss, password forgetting, recovery code loss, and recovery code stolen. Wait for most questions.
(3) Project evaluation
MYKEY essentially plays the role of guiding the currency platform. By introducing the permission separation mechanism, hierarchical key management, trusted recovery mechanism and risk correspondence system in the Key ID protocol, the traditional public chain data throughput is insufficient and the private key is solved. Lost can not be retrieved, the information on the chain is vulnerable to attacks and other pain points. The project relies on the currency platform and will generate more traffic and more financial support.
4.2.3 Cambridge Blockchain
(1) Project introduction
The Cambridge Blockchain is a company that produces digital identity software that simplifies the storage, sharing and verification of personal data by using the most advanced privacy protection technologies and secure systems, providing companies with effective solutions such as KYC for financial institutions. Wait.
The Cambridge blockchain's goal is to help financial institutions meet the most stringent new data privacy rules (such as GDPR), eliminate redundant identity compliance inspection processes, and proactively cater to regulatory while reducing costs.
(2) Business process
In the Cambridge blockchain business model, the owner of personal data has control and ownership of digital identities and their associated data, typically natural persons, businesses or equipment. A trusted third party acts as a verifier, typically a government or business. Service providers are consumers of personal data and credentials, typically businesses.
First, a verifiable statement is issued by the user, and after being verified by a trusted third party, sensitive data is provided to the service provider in exchange for the corresponding service. In this process, personal sensitive data is stored in a chain in an encrypted and abstract manner, which facilitates supervision by regulators.
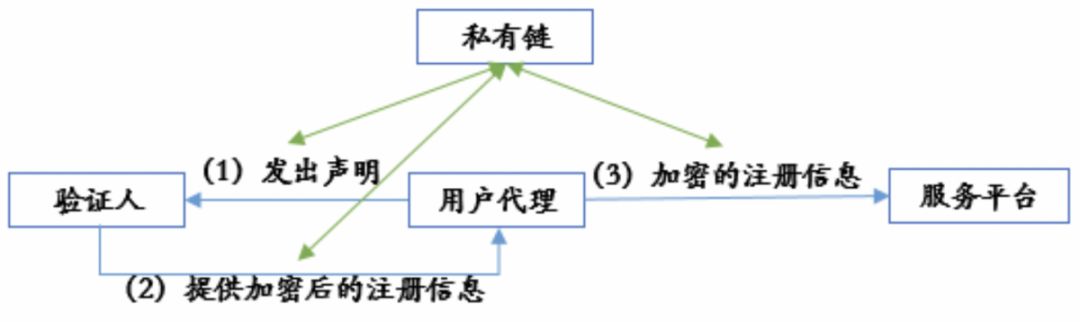
Figure 12: Cambridge Blockchain Business Flow Chart Source: Cambridge Blockchain Official Website
Note: The blue arrow indicates the execution steps of the business process, the green arrow indicates the encryption process of the private chain for all steps, and the process of encrypting the information into the chain.
In the KYC business , the company and IHS Markit became strategic partners, and IHS Markit provided KYC data for financial institutions or related entities, covering more than 250 due diligence documents and more than 14,000 companies. Including large banks such as Citibank, Morgan Stanley, and Swiss Bank.
In supply chain finance , the company created a “Supplier Data Service” network for Foxconn's major suppliers and sub-suppliers through Foxconn's subsidiary, Chained Finance. The network allows debt financing based on supplier orders, delivery status, quality control reports, and more.
(3) Project evaluation
The company uses the raw data of 264 million users provided by IHS Markit to improve its business. In the future, it plans to establish KYC data sharing among five payment companies such as PayPal. At the same time, the company actively caters to regulatory needs and optimizes Luxembourg by building Lux Trust ID Keep. Italy's compliance regulatory process; the Cambridge blockchain is deeply involved in the Foxconn supply chain financial system to optimize resource allocation while meeting the needs of banks, payment companies, entities and regulatory authorities.
4.2.4 ShoCard Identity Management Platform
(1) Project introduction
ShoCard is an identity management platform, which is different from the traditional identity management platform. It is characterized by blockchain-based decentralized identity storage and implements its applications and functions with SSI (self-sovereign identity) as the gateway. Currently in finance Landed applications in industry and tourism. There are three functions implemented by the ShoCard network: the exchange of authentication, authorization verification certificates, and the certification of personal certificates (authenticity reports that prove verifiable statements).
ShoCard is designed to allow multiple entities or individuals to establish trust through independent information verification. It does not require long-term mutual trust relationships, and no need for trusted third parties to perform independent verification.
(2) ShoCard's IM system technology stack
The ShoCardIM platform is integrated into applications and servers for mobile devices such as mobile phones through its Software Development Kit (SDK). Its architecture includes the ShoCard Software Toolkit (SDK), the ShoCard Service Layer (Sho Server and Sho Storage), the ShoCard Sidechain, the Blockchain Cache, and the ShoCard Blockchain Adapter.
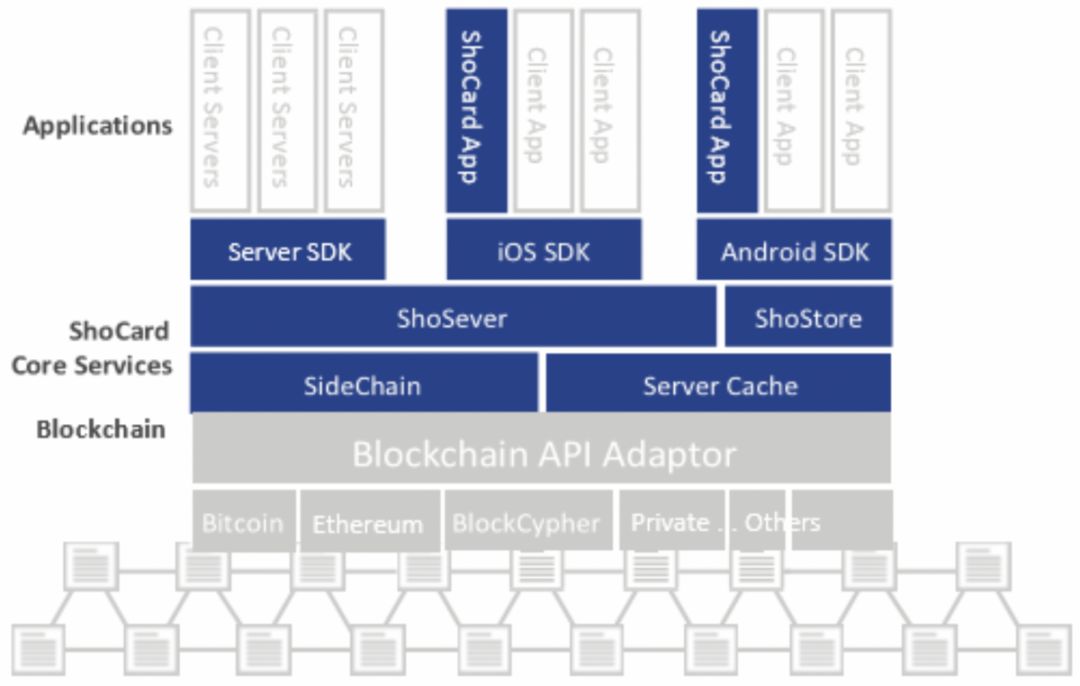
Figure 13: ShoCard Technology Stack Source: ShoCard White Paper
- Application layer
In terms of usability, ShoCard supports both IOS and Android on the application; on the data store, these software toolkits (SDKs) perform all verification and checking only on the local server or device, not the foreign server, ie self-verification . Any third party can participate in verifying the authenticity of its statement.
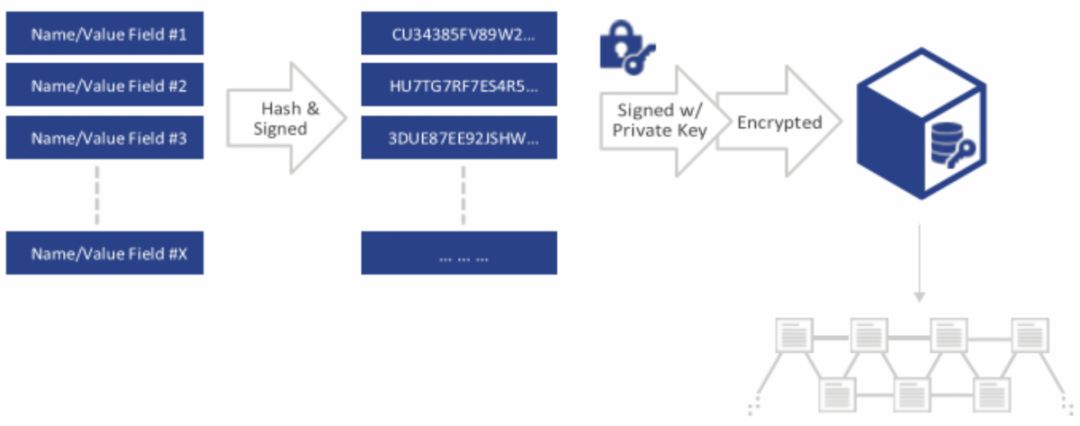
Figure 14: ShoCard self-authenticated identity encryption stored on the chain Source: ShoCard White Paper
ShoCard is used in the KYC system of the financial industry, government and tourism.
For financial institutions' KYC functions, the ShoCard IM platform has data exchange capabilities. It allows the original certifier (such as the bank that performs the initial KYC) to use the blockchain to charge information fees to other financial institutions that also want KYC, and the user decides and chooses the certificate shared with other parties. Thus, on the one hand, the requesting agency can reduce its overall KYC cost and speed up the certification; on the other hand, the original verifier can also monetize it.
Credit card authorization service . With the ShoCard IM platform, credit card networks and banks can easily request transaction authorization from users without specifically registering an ID with ShoCard. Through the blockchain's PoW mechanism, the cost of fraudsters is increased, and the inevitable modification of the blockchain avoids transaction friction caused by multiple parties. Therefore, the solution is applicable to both e-commerce and entity enterprises.
Zero knowledge certification service . In the ShoCard IM platform, the user agent simply requests authentication. After receiving the verification notification, the client uses the biometric authentication method such as self-authentication or face recognition to verify the verification on the local server.
Credit sharing . Through the ShoCard IM platform, the credit evaluation company can prove the authenticity of the user's credit score and other related information on the blockchain. The credit certificate will be bound to a specific user, and the user can provide data such as the credit report certificate to any third party institution. , which reduces transaction costs and increases transaction speed.
Travel identity certification . On the ShoCard IM platform, the authority checks and verifies the traveler's ID (such as a passport, etc.) and places their certificate on the chain. When the traveler arrives at the next service offering location on the trip, the traveler ID on his chain is safely displayed by scanning QR codes, Bluetooth and captured image recognition. At each node, the service provider independently verifies the traveler ID through the blockchain and associates its ID with the service he purchased, thereby reducing the labor cost of the service provider and reducing the waiting time for the travel service.
- Service layer (ShoCard's DID protocol)
In terms of decentralization, the ShoCard service layer does not actually exchange raw data with users. When a transaction is recorded on the blockchain, all messages are digitally signed by the user and encrypted using the other party's public key. The ShoCard's service provider can never decrypt the user's data information, it only executes the "write" command. .
In terms of scalability , on the one hand, the ShoCard service layer manages caches and local indexes to create high-throughput and highly scalable systems; on the other hand, the ShoCard service layer manages all clients' SDKs and blockchains. Interface between. In order to compensate for the limitations of the system's low throughput due to the consensus delay of the public chain, the ShoCard identity management platform is responsible for managing the sidechain (smart contract for storing and managing certificates) and the cache record of the main chain under the main chain (reserved to the local copy) For faster read and access, and then access the local through the API adapter.
Under this architecture, the ShoCard service layer can create and authenticate at least 5 million new users within 30 minutes under the PoW consensus mechanism, that is, create and authenticate 2,778 per second, and effectively avoid network partition failures and single points of failure, and Data is vulnerable to being stored on the chain.
(3) Project evaluation
By introducing a local server authentication mechanism, ShoCard always encrypts all the information of user data on their mobile phones and verifies them with biometric technology, storing digital signatures only on the main chain. It solves the problems of low-throughput of the public chain, centralization of data storage, and vulnerability of information on the chain, breaking the impossible triangle of the current blockchain project in terms of scalability, security and user convenience.
4.2.5 Sovrin Identity Management Network
(1) Project introduction
Sovrin is a cross-border, semi-publicized digital identity management network. The identity type of the network is SSI. All participants, such as users, have only the right to use the network and do not have ownership of the network. It is designed to build a distributed network that provides digital identities to everyone around the world and makes it as ubiquitous as DNS. Sovrin addresses the problem of insufficient DID scalability, lack of governance models, and insufficient storage security on the chain.
(2) Sovrin Agreement
Sovrin is a protocol for autonomous identity and decentralized trust designed to meet the four requirements of SSI: scalability, governance, accessibility, and privacy protection.
Governance First, because SSI does not rely on any blockchain or distributed ledger technology, it can embed various blockchains and distributed networks as long as it meets its basic usage requirements, so its governance model has a greater advantage.
Next, Sovrin sets up a new Token and provides built-in incentives to motivate service providers to protect user privacy. First, Sovrin provides a Token accurate to 1 cent to lower the usage threshold of the payment system. Sovrin's Token links to every exchange of verifiable claims, and the value of the voucher can be shared securely and with the owner's consent. Achieve multiple wins. Therefore, the Sovrin network has a good application in microfinance, lease, employment qualification, online recommendation and news verification.
- Scalability
Sovrin has a big advantage in scalability. On the one hand, in order to overcome the shortcomings of the consensus mechanism intelligently extending to a limited number of verification nodes, Sovrin divides its network node network into two categories: verification nodes and observation nodes. The former is used to record transaction transaction information, and the latter is used to run a read-only copy of the blockchain to meet the readability requirements of the SSI. On the other hand, the Sovrin blockchain is able to prove the status of any behavior. Sovrin's encryption proof can be processed on the smartphone, verifying the validity of the behavior based on the current status of the ledger, effectively preventing man-in-the-middle attacks.
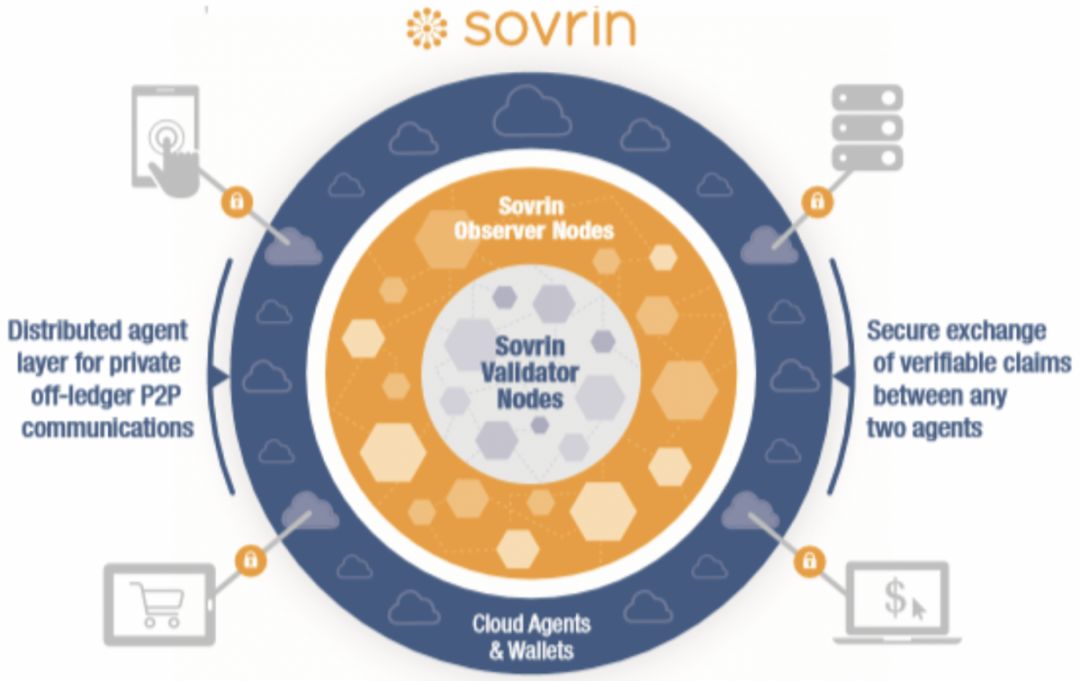
Figure 15: Two types of node groups in the Sovrin network enhance scalability. Source: Sovrin White Paper
- Accessibility
Accessibility is universal access, and Sovrin implements universal access in three ways:
- Running a distributed ledger with a user license system at a high cost;
- Design a low-cost, distributed, unlicensed ledger;
- Subsidize the cost of all ledgers.
In addition, the Sovrin Foundation formed the “Everyone's Identity” council to ensure that Sovrin meets the needs of those who have not yet proven their identity, such as European refugees.
- Privacy protection design
The core of the Sovrin architecture for privacy protection is "Privacy as the default."
- The default setting is anonymous . Sovrin supports paired unique DIDs and public keys. Sovrin uses paired anonymous identity identifiers , each with a different anonymous identifier. Paired anonymous identity identifiers are not worth stealing , and hackers can't just use it anywhere else, and can change the DID once any party finds a problem.
- The private user agent is set by default . In the Sovrin architecture, each DID has a corresponding dedicated agent with its own anonymous network address from which the identity owner can exchange verifiable claims and other rights with another identity owner through an encrypted private channel. Any data.
- The default setting user data is selectively exposed . Sovrin's verifiable claims use encrypted zero-knowledge proofs, so they can automatically support data minimization.
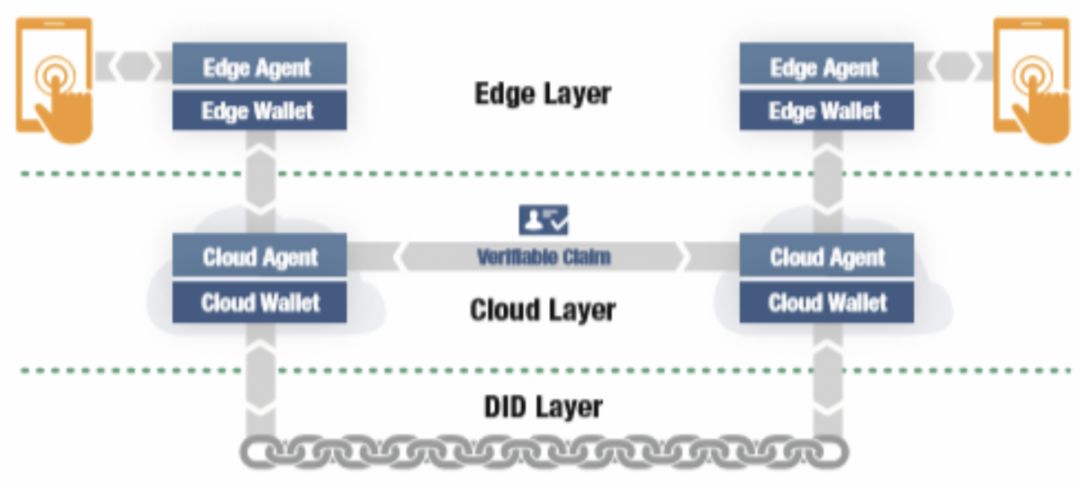
Figure 16: Sovrin's private agent Source: Sovrin White Paper
(3) Project evaluation
Sovrin essentially reduces barriers to entry in the authentication market, allowing more individuals or organizations to participate in SSI's identity management network with a certain network effect. Although the problem of insufficient data storage and user privacy protection in the blockchain has been solved, effective breakthroughs and progress have been made in technology, but the problems corresponding to the real world and the digital world identity cannot be solved, and the subsequent implementation of the project is more difficult. It may be necessary to work with government authorities and act as a verifier, and subsequent Sovrin projects may be a good choice for developing alliances between companies.
4.2.6 uPort
(1) Project introduction
uPort is a decentralized identity system based on the Ethereum network that allows users to authenticate, passwordless logins, digital signatures, and interact with other applications on Ethereum. uPort aims to solve the problem of private key management that is common in current public chain projects, and to create permanent identity information by integrating identity protocols of blockchain projects.
(2) Project technical plan
The solution for uPort authentication is to create a fully user-controlled digital identity based on blockchain technology that can be used across the network. Based on different usage scenarios, users can grant or disallow access to other users' identity information.
uPort's technical architecture consists of three main components: smart contracts, developer libraries, and mobile apps. Smart contracts allow users to recover their identity when a mobile device is lost, and the developer library allows developers of third-party applications to interact with uPort.
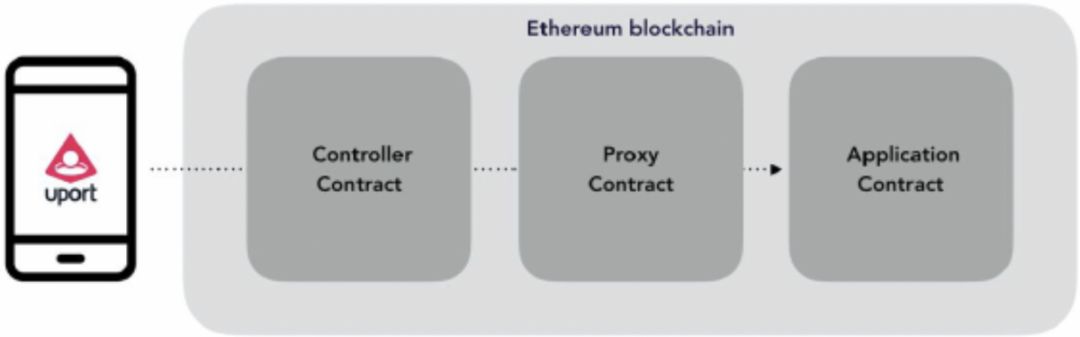
Figure 17: uPort Certification Process Source: uPort White Paper
The uPort authentication process is:
- The user requests a uPort ID through the uPort App;
- The proof file is uploaded in the uPort App and waiting for the verification result. Currently, uPort official website DEMO supports the uploading of information files such as cities, degrees and occupations;
- Certificates issued by the certificate authority need to create electronic files and provide a captureable method similar to the two-dimensional code on these documents;
- uPort works with a certificate authority to invoke electronic files of these certificate authorities;
- The third-party application accesses the uPort, which indicates which documents the user needs to provide when using the application.
- Users use uPortApp to scan third-party application QR codes for registration. The application obtains the user uPortID and passes it to uPort, requesting uPort to check whether the ID has verified the certificate required by the application;
- If the uPort check is passed, the application allows the user to register and use the user's uPortID to write to the account contract; if the uPort check fails, the user has not yet associated the certificate file, and the application requires the user to verify the required supporting documents in the uPort. ;
- After the verification is passed, the next time the user logs in to the application using uPort, the uPortID is passed in, and the application will match the uPortID in the account contract. If it exists, the login is allowed.
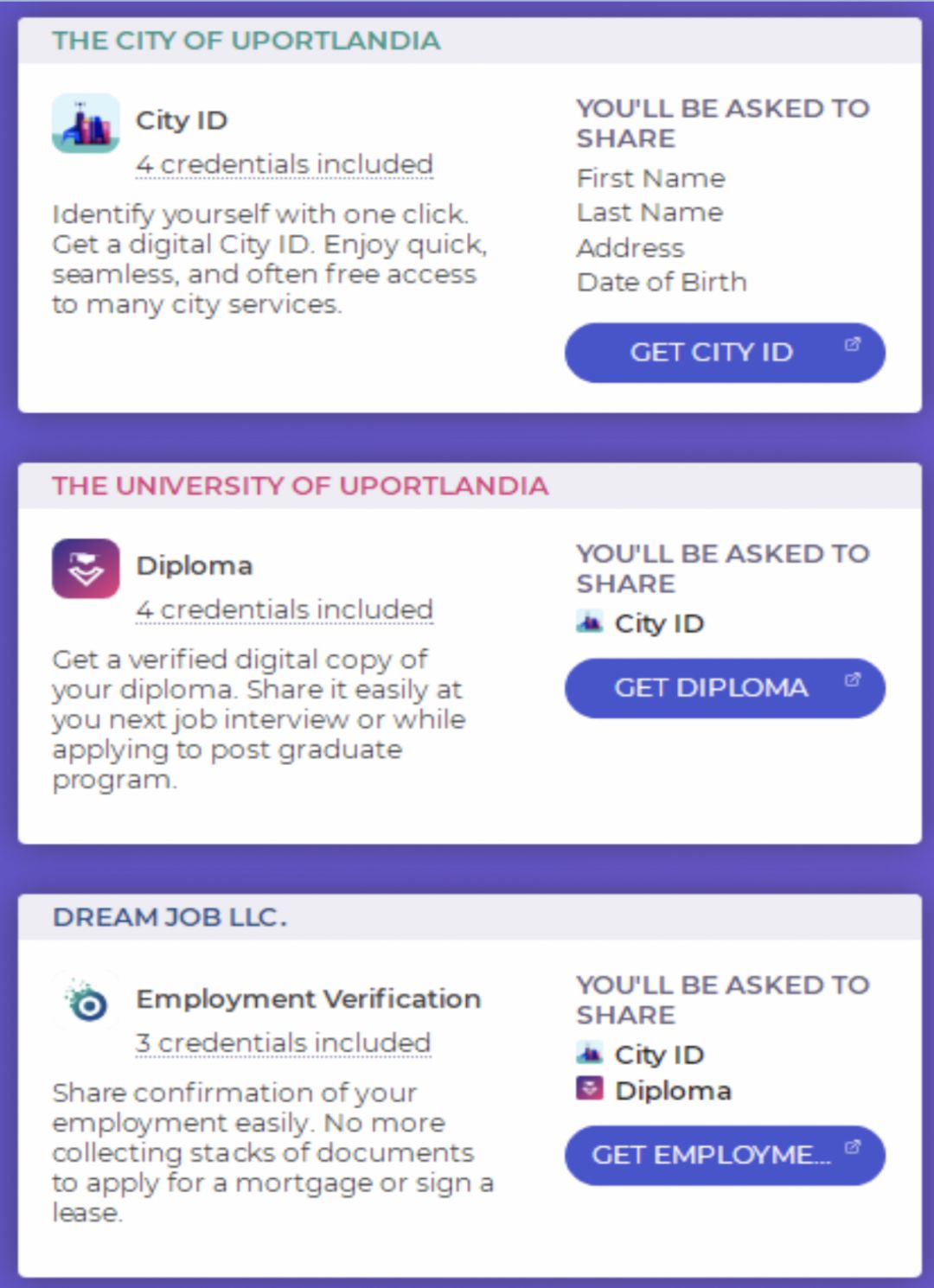
Figure 18: Example application of the uPort App Source: uPort Official Website
(3) Project evaluation
The uPort identity is essentially an Ethereum smart contract address. Therefore, when users interact with third-party applications, they only need to provide the Ethereum smart contract address by uPort, and do not rely on the data information of the centralized identity provider. However, it should be pointed out that the uPort project needs to cooperate with various certificate authorities to complete the verification of uploaded files, which is a huge challenge for the uPort project.
4.2.7 Civic
(1) Project introduction
Civic is a blockchain-based identity authentication system designed to create a new ecosystem to address current malpractices in the field of identity authentication and identification (IDV).
For enterprises that need to be authenticated to provide services, they rely on the Civic system to perform user authentication more efficiently and at low cost, and at the same time play an anti-counterfeiting role to improve service quality. Users can control their identity information within the Civic system, and can easily enjoy the various services after completing the identity authentication within the ecosystem.
(2) Product application
The smart contract for the identity ecosystem in the Civic project is built in Ethereum, where user identity information is stored on the Ethereum for subsequent authentication, so the user experience in all aspects of data recall and deposit will depend on the ether. The efficiency of the workshop.
The identity of the Civic project is mainly done through the app on the mobile phone. Users can use the fingerprint or face recognition on the mobile side of the app to confirm and register the user. After the user's identity completes the first registration confirmation, the user can scan the code at the designated merchant that cooperates with Civic to obtain identity authentication and enjoy follow-up services. Civic's technology products can be divided into the following sections:
- Secure Identity Platform
Through decentralized blockchain technology and mobile biometrics (fingerprint, face recognition), the Civic platform provides a multi-faceted authentication guarantee, and third-party trust organizations will review their identity. The identity information will be stored on the user's mobile side by encryption, and only the user can access it, so it will not be used by the government and criminal groups. At the same time, the identity information will generate hash values for storage on the blockchain for subsequent services to prove the authenticity of the data.
- Reusable KYC (Reusable KYC)
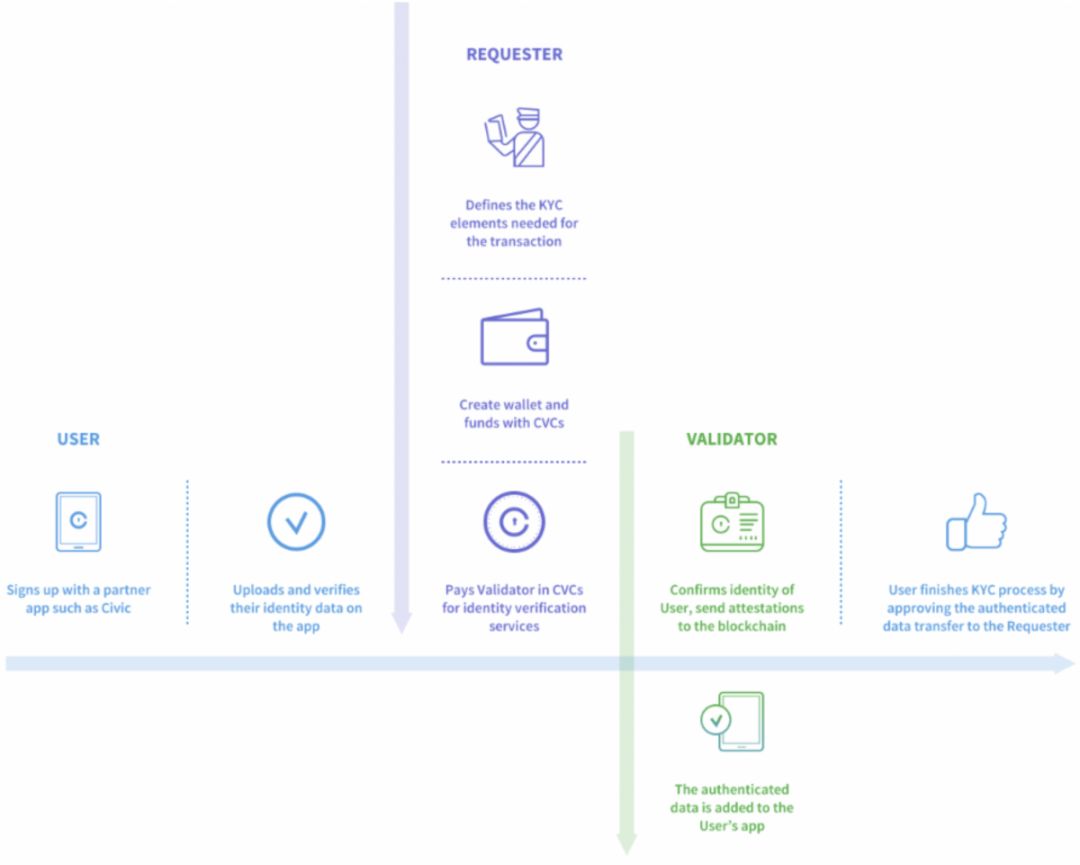
Figure 19: Civic KYC Certification Process Source: Civic Official Website
KYC is completed when the user authenticates for the first time on the Civic platform, and this process takes only 3-5 minutes. If the servant who specifies the cooperation later needs to perform KYC verification, the Civic user can complete the authentication without the need to repeat the data identity submission simply and quickly. Websites and platforms that need to verify user information can access Civic as a Requester (requester, such as exchanges, banks, etc.), while Validator (verifier, verification node) is responsible for verifying the user's identity. If a user wants to submit a KYC application to Requester, they should submit their information to the verification smart contract on the blockchain. These smart contracts complete the managed services of the transaction and provide identity data for the Validator. Validator compares the identity information with the hash value that the user has authenticated on the blockchain. If the authenticity of the information is verified and the KYC requirements are met, the Validator will give the user the authorization to pass the KYC and pass the KYC user information back to Requester. The entire verification process will be done through Civic's identity ecosystem, identity.com, and both the user and the Requester will need to pay a certain CVC Token for the Validator.
- Vending machine (Automated Retail)
Civic's official website offers the sale of beer vending machines, currently at a predetermined stage, with a reservation fee of $999 per unit and a vending machine price of $15,000. For countries that are limited to age to purchase alcoholic beverages (for example, the United States prohibits the purchase of alcoholic beverages under the age of 21), such vending machines can quickly and safely and anonymously enable users to purchase beer. After the identity of the Civic platform, users only need to scan the App mobile phone on the Civic vending machine to confirm whether they are eligible for purchase. Users do not need to show identification documents every time they buy alcoholic beverages in the supermarket. In the future, Civic will also provide a channel for digital currency payments, so that purchase payments are made by the Civic App. This business model for anonymous identity checks is not limited to the sale of beer. For some age-restricted drug prescriptions and other items, automated sales can also be achieved through such vending machines, thereby saving labor costs. Beer vending machines will be sold first in the United States, but the project side is still addressing the issue of regional legal compliance for beer vending machines. According to Civic's official website, the Civic project has entered into a partnership with two well-known beer manufacturers.
- ID Codes
Civic's unique identity authentication system connects user identity to business, investment, and any interpersonal relationship using blockchain technology. Civic believes that in the current Internet information, there are too many false information about business relationships, investment relationships, etc., which will cause unnecessary misleading and potential business losses. With Civic's ID Codes technology, authenticated interpersonal relationships can be verified on the blockchain, and user profiles and information are securely secured. According to Vinny, founder of the Civic team, ID Codes are free for individuals, but companies must pay to use the service. Currently, more than 60 companies have committed to using ID Codes.
(3) Project evaluation
Civic's main direction is identity authentication. It has achieved certain results in terms of products and solved some very specific problems, such as determining whether users are allowed to buy beer through identity authentication, and protecting users' privacy. The difficulty lies in how to expand the scale of their business and promote the services of their secure identity platform to more individuals and businesses.
4.2.8 Microsoft DID
(1) Project introduction
On May 13, 2019, Microsoft released its DID implementation, ION (Identity Overlay Network). ION is a bitcoin-based, two-tier network that accesses the Bitcoin network through the Sidetree protocol. ION combines a large number of DID operations into one uplink operation by batch merging on the second layer network, and realizes DID by storing the data on the bitcoin network by storing the data on the IPFS. Trusted storage of data. ION circumvents the performance of Bitcoin networks and can support thousands or even tens of thousands of data throughput per second.
(2) Technical architecture
According to the white paper, Microsoft's DID consists of the following seven technical modules:
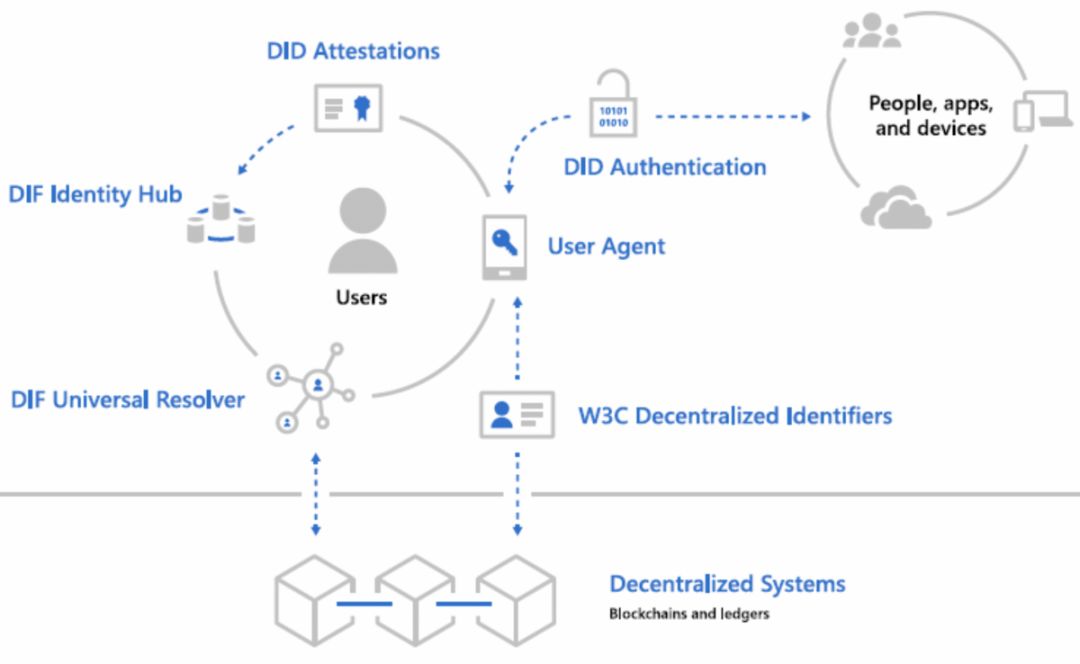
Figure 20: Microsoft DID Technology Module Data Source: Microsoft DID White Paper
- W3C Decentralized Identity (DIDs)
DIDs are identities that are created, owned, and controlled by users independent of any organization or government. According to the W3C's annotations, the DID is the world's only identifier linked to the Decentralized Public Key Infrastructure (DPKI) metadata, which consists of a public key material, an authentication descriptor, and a server DID document.
- Decentralized systems (eg blockchains and distributed ledgers)
The feasibility of DID ultimately needs to be built on a decentralized system, and blockchain technology provides the mechanisms and functions required for DPKI.
- DID User Agent
User agents are applications that enable users to use decentralized identities. Helps with DIDs creation, data and rights management, and signature verification DID-related claims.
- Global DID parser
The global DID parser uses a set of DID drivers to provide a standard way to find and parse various DIDs across a decentralized system. For example, theid starting with did:abt, where abt indicates that this is the DID provided by ArcBlock, so the global DID resolution can be used to locate the technical provider of the DID. This is one of the keys to the interoperability of DIDs.
- Identity center
The Identity Center is a replicable grid of personal data encrypted storage consisting of cloud and edge instances such as mobile phones, computers or smart speakers for easy identity data storage and identity interaction.
- DID certification
DID authentication is a DID-based authentication protocol. This may be the first way that DID technology is perceived by the end user, that is, DID can be used to log in to various DID-enabled services.
- Decentralized applications and services
DIDs combined with personal identity data storage centers create new applications and services that store data in user identity centers and operate within authorized limits.
(3) Project evaluation
Microsoft DID technology architecture is comprehensive and has a strong universality. As a large technology company, the implementation of Microsoft's DID program will play a very good role in the development and promotion of standards in this field. For the blockchain performance bottleneck that DID may face, Microsoft DID solves the problem of low bitcoin performance by using the most secure blockchain network bitcoin while merging data in the second layer network. A solution that combines safety and efficiency.
5 DID's future prospects
5.1 Relevant technology developments
5.1.1 Decentralized storage
A person's identity includes social attributes, property attributes, and data attributes. Social attributes refer to various types of data related to identity, such as health data, shopping records, and qualification certificates. Therefore, the appropriate storage method is required to store the DID-related data in a trusted manner.
Traditional data storage methods face the same data security and privacy issues as centralized identity management. Decentralized storage is one of the solutions to this problem. Decentralized storage is also considered an important part of Web 3.0, and it has a value proposition similar to DID.
Decentralized cloud storage is theoretically superior to traditional cloud storage in terms of privacy protection, high security, low cost, strong scalability, low bandwidth limitation, and trust. However, in practical applications, verification is still needed. The reliability of scale applications faces many challenges in terms of technology and regulations. Currently, decentralized cloud storage projects mainly include Filecoin, Storj, Sia, MaidSafe, Swarm, Lambda, Genaro, Casper API, Sharder, etc. Some of the projects have been issued Token and distributed:

Figure 21: Decentralized storage development history
From the above projects, the total market value of the current centralized cloud storage platform is about 423 million US dollars, which is less than 1% of the traditional cloud storage market. In fact, in the above projects, although BitTorrent and MaidSafe's certificates have been listed, they have not yet provided usable storage services. In addition, other high-profile, uncirculated decentralized cloud storage projects, Filecoin and Swarm, are still in place. In the development phase. At this stage, the development of decentralized storage technology will have an impact on the implementation of DID.
5.1.2 Cross-chain and its infrastructure
From the current development of blockchains and distributed ledgers, it is foreseeable that people need to interact with different blockchains or distributed ledgers. How DID meets the needs of users across the chain will depend to some extent on the development of cross-chain infrastructure.
At present, the mainstream cross-chain technology has a notary mechanism, a side chain/relay chain, a hash lock, and a distributed private key control. We have seen the implementation of asset cross-chains, such as WBTC on the Ethereum network and RBTC in the RSK network, the former using distributed private key control and the latter using sidechain technology.
Figure 23: Cross-chain technology architecture Source: Polkadot White Paper
Today's high-profile cross-chain networks, Cosmos and Polkadot, are in the development phase, both of which are technically capable of transporting cross-chain assets and messages. According to the development progress, Cosmos is expected to release its Block Inter-Chain Communication (IBC) agreement in 2019; Polkadot may launch its main network in the first half of 2020.
From the development of cross-chain infrastructure, DID has a variety of technical solutions in dealing with cross-chain asset transfer; in the processing of cross-chain smart contract interaction, it is also expected to obtain support for cross-chain networks such as Cosmos and Polkadot.
5.2 Data Affirmative Promotion of DID
The most fundamental core element of DID is that power is transferred to the user by the centralization organization, whether it is permission, income or control, and the distribution of interest and data property rights between Internet companies and consumer users is unequal. People pay more attention to data property rights to people's attention to copyright. DID projects will gradually enter the growth stage of rapid development, and naturally, a positive feedback effect will be formed in the closed loop, and the 2C project will accelerate. Whether it is the permission to provide data, the right to participate in the optimization of the entire system, or the right to participate in community governance, the DID system. The fundamental reason why centralization organizations (such as Tencent, Alibaba, etc.) can become bigger and stronger is that their business model has formed a positive feedback effect , data is in their hands, and with the increase of platform applications and the number of users As they increase, they can get more data and further improve.
We believe that consumers' demand for data affirmation (Internet service providers and users should have equal rights) will increase, leading to the legal system to make up for the lack of protection of log rights, and thus boost people's demand for DID. The argument has the following three points:
- The data property rights on the Internet should belong to consumers (users). Any data collection in the future should have a legal basis, otherwise it cannot be collected. At present, the Internet giants use their inherent advantages to obtain consumer surplus, so the future law is bound to protect the rights of individuals or organizations. Although Facebook has been fined and promised to protect user data in accordance with the GDPR standard, there are no laws and regulations based on AI algorithm to mine personal information data. The DID protocol allows users to have permissions, access and ownership of their digital identity through decentralized storage, personal data encryption, and distributed ledger technology, in line with future regulatory direction.
- Consumers (users) must participate in the process of data sharing business model and have the right to benefit, so as to achieve true value sharing. Similar to the process of European mineralizers' acquisition of mineral resources in the Americas, Internet companies naturally use data sources with marginal costs close to zero. The DID protocol greatly enhances the degree of user participation in business by building an effective distributed business governance model, and not just the Internet model, users only use related products or services. For example, Blockstack voluntarily mobilizes the enthusiasm of users (including developers and other individuals or organizations) through decentralized building of a community network, rewarding users who develop new applications or features, and enabling users through Gaia Hub's decentralized storage. The data security has been greatly improved. In the future, users will play more roles in the DID network, such as developers, verifiers, voters and voters, and participate in the design process of network community products or services from a broader perspective, forming a positive positive feedback loop. .
- The legal protection of the right to power will promote the progress of society and the development of innovation. Although monopoly represents a high profit at a lower cost, it tends to curb the pace and motivation of innovation. On the one hand, the supply side monopoly loses competition and loses the external power of innovation and progress because it monopolizes resources and productivity. On the other hand, consumers and users on the demand side do not enjoy the right to income generated by products or services, and thus lose the motivation to help the business ecology and the new business model. If the consumer's digital rights are not legally protected, the Internet will continue to seize consumer data in an unsolicited manner, and consumer acceptance of new Internet services will decline, which will slow down technological innovation to a certain extent and affect the data economy. The popularity and speed of globalization. Without real sharing and popularity, there will be no real Web 3.0.
In an ideal state, the blockchain has a methodology for solving this dilemma. For the blockchain (book), each transaction participant has only the right to use, not ownership, so the number of users and consumers can be effectively guaranteed. However, in reality, the user's book storage and calling requires a large amount of data, resulting in high technical barriers to use, and it is difficult to be accepted by a large group in use, resulting in limited use, so the key to the future lies in the blockchain. How technology can lower the threshold of use, only by doing this, can more users and consumers accept the DID system.
5.3 The resolution of privacy issues is the premise of DID landing
Before the privacy issue is completely resolved, the ID on the blockchain is difficult to give too much energy, because as the user base becomes larger, it may bring a series of social problems. Even if the blockchain distributed ledger or blockchain operation is seriously hindered due to insufficient data throughput, the user base will become a series of social problems.
DID is easy to provide a full umbrella for crime and hinders government regulation. More and more criminal organizations use encrypted information to complete illegal transactions. Since the blockchain only guarantees that the data information cannot be tampered after being chained, it cannot guarantee the authenticity and timeliness of the information before the uplink. When the regulatory organization requires the blockchain to provide encrypted information or tamper with the relevant non-compliant transaction records, the relevant nodes in the DID network cannot meet the requirements of the regulator.
The unreadable readability of DID identifiers will prevent communication between people. Most DID projects often sacrifice the readability of identifiers to ensure decentralization and usability. However, as the user base expands, the need for information exchange and transmission between users will increase, and The way you communicate is also higher (such as video, call, AR, VR, etc.). In the process of communication, there must be more or less leakage of personal or organizational information, and privacy protection can not meet relatively high requirements.
Although the privacy protection technology was proposed and used 20 years ago, it is still immature. The service provider of the centralized identity system controls the privacy of the user, and the code on the blockchain is open source. The information stored on the chain is vulnerable to hacking and disclosure.
Although the centralized identity system and the DID system have certain defects in privacy protection, I believe that if the two learn from each other, they will achieve unexpected results. On the one hand, the storage of data is kept by the government authority or the role of the government authority as a verifier can effectively solve the regulatory problem; on the other hand, the DID system can break the traditional Internet giant monopoly data to better benefit and fair. Achieve a balance between the two. However, a series of problems caused by the expansion of the user base will lead to the majority of DID projects that can only be started on the 2B side. For example, the Cambridge blockchain and other projects have become inevitable.
5.4 DID Outlook Summary
From the perspective of economics, the current problems of DID mainly come from the contradiction between benefit and fairness. The higher the degree of centralization of the project system, the higher the efficiency of resource integration, but the sacrifice of user privacy and account security. The greater the fairness of sacrifice, the greater the fairness of the data. The nature of the data is essentially the right of the user to enjoy fairness with the identity provider in all activities of the digital identity platform, including licensing rights, income rights, right to know and access rights. The essence of data affirmation is determined again). In the future, no matter how advanced the technology is, and what structure the ideology and business model develops, DID is essentially to make the fairness more perfect on the basis of ensuring the benefits, and the constant game and compromise between the two, trade-offs and trade-offs.
We believe that the development of DID should be gradually improved with the evolution of laws, regulations and social systems.
From the perspective of short-term (in the next 5 years) , the development of most DID projects is still based on 2B, providing effective solutions for multi-party games such as supply chain finance, inefficient operation, and extremely asymmetric information. The scheme builds the DID in the form of a private chain or a coalition chain. (refer to the various standards)
From the perspective of the medium term (the next 5-10 years) , with the continuous improvement of the legal infrastructure, DID has played a major role in conforming to its own development of standardization, legal norms and other related facilities. DID will gradually move from 2B to 2C. With the lack of network effects in the smart contract, the DID project will gradually achieve certain scale effect and network effect.
From the perspective of long-term (the next 10 years) , the DID network will gradually emerge, and the global standard of DID will be unified. DID finds a balance between efficiency and fairness, and regulators access it in the form of a verifier or storage organization. The DID system strengthens the supervision while ensuring the privacy of the users, realizing the true grasp of the data in the hands of the users.
Special thanks to the support and guidance given by MYKEY experts in our research!
Copyright Information and Disclaimer
除⾮本⽂另有说明,否则所有内容均为原创,由TokenGazer研究和制作。未经TokenGazer明确同意,不得以任何形式复制或在任何其他出版物中提及此内容的任何部分。
TokenGazer的徽标,图形,图标,商标,服务标记和标题是TokenGazer Inc.的服务标记,商标(⽆论是否注册)和/或商业外观。本⽂提及、展示、引⽤或以其他⽅式指出的所有其他商标、公司名称、徽标、服务标记和/或商业外观(“第三⽅商标”)是其各⾃所有者的专有财产。未经TokenGazer或此类第三⽅标志的所有者事先明确书⾯许可,不得以任何⽅式复制,下载,显示,⽤作元标记,误⽤或以其他⽅式利⽤标记或第三⽅标记。
本⽂仅供参考,⽂中所包含的所有信息都不应该作为投资决策的依据。
本⽂不构成投资建议或辅助判断特定投资⽬标、财务状况及其他投资者需求。如投资者对投资数字资产有兴趣,应当咨询⾃⼰的投资顾问,投资者不应凭借本⽂以作为法律,税务或投资⽅⾯的建议。
本研究中提到的资产价格和内在价值并⾮⼀成不变。资产的过往表现也不能作为⽀撑本⽂所述的任何资产的未来业绩依据。某些投资的价值、价格或收⼊可能会因为汇率波动⽽产⽣不利影响。
本⽂中涉及的某些陈述可能是TokenGazer对于未来预期的假设以及其他的前瞻性观点,⽽已知和未知的⻛险与不确定因素,可能导致实际结果、表现或事件与陈述中的观点和假设存在实质性差异。
In addition to forward-looking statements as a result of contextual derivation, there are words of “may, future, should, may, can, expect, plan, intend, anticipate, believe, estimate, predict, potential, predict or continue” Similar expressions identify forward-looking statements. TokenGazer is not obligated to update any forward-looking statements contained herein, and Buyer shall not place excessive reasons on such statements, which merely represent opinions prior to the deadline. While TokenGazer has taken reasonable care to ensure that the information contained herein is accurate, TokenGazer makes no representations or warranties, either expressed or implied, including the liability of third parties, for its accuracy, reliability or completeness. You should not make any investment decisions based on these inferences and assumptions.
Investment risk warning
Price fluctuations: In the past, digital currency assets have single-day and post-price fluctuations.
Market acceptance: Digital assets may never be widely adopted by the market, in which case single or multiple digital assets may lose most of their value.
Government regulations: The regulatory framework for digital assets remains unclear, and regulatory and regulatory restrictions on existing applications may have a significant impact on the value of digital assets.
About TokenGazer
TokenGazer is committed to providing long-term, continuous improvement of value research methods and toolsets for the blockchain industry, as well as technical and business insights for blockchain and Token projects. Provide industry-leading qualitative and quantitative analysis tools, research templates, data warehouses, and data visualization services for users at home and abroad to help users better analyze and measure the true value of blockchain projects.
Welcome to TokenGazer's official website: tokengazer.com to view the primary market depth research, secondary market rating reports and quantitative research, project valuation deviation data, investment strategy analysis and past exchange data analysis.
Editor in charge: TokenGazer
This article is the original content of TokenGazer, please indicate the source.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- "Dark net" black trading eco exposure: buying and selling personal information, drugs, using bitcoin transactions, multiple large cases were investigated
- Bitski completed $1.81 million in seed round financing and won the favor of three well-known institutions such as Coinbase, Galaxy Digital and Winklevoss
- Ling listened to Wu Xiaobo channel, and found these 5 opportunities in 3000 blockchain articles.
- Financial observation: The United States is advancing the delay of the digital currency, causing industry concerns
- Blockchain analysis company Messari completed $4 million in financing, Coinbase, distributed capital, etc.
- HSBC joins Singapore Exchange and Temasek to issue blockchain-based fixed income securities
- US CFTC Chairman: After Ethereum 2.0 to PoS, ETH may be considered "securities"