Dune SQL and Ethereum Data Analysis Advanced Guide
Dune SQL and Ethereum Data Analysis GuideAuthor: ANDREW HONG; Source: Web3 Data Degens; Translation: Chainlink Translation Plan
In this guide, you will learn how to browse Ethereum protocol standards and use advanced SQL functions for call tracing, time series balance tracking, dex/nft transactions, and ABI.
What are standards? Why are they important for analysts?
Protocols consist of a set of smart contracts that effectively manage functionality, state, governance, and scalability. Smart contracts can be infinitely complex, with a function calling dozens of other contracts. The structure of these contracts evolves over time, and some of the most common patterns become standards. Ethereum Improvement Proposals (EIPs) track these standards and create a set of implementation references (code snippet libraries).
Here are some examples of standards:
- The Core Function of Data Availability in Layer2
- Consensys Global Survey How is Web3 perceived around the world?
- Understanding the Account Abstraction That Determines the Future of Web3 in One Article
-
Creating clone factories like the Uniswap factory to create new pairs of contracts or Argent to create smart contract wallets, with optimizations such as minimal proxies (EIP-1167).
-
Tokens for deposit/withdrawal, such as WETH and aTokens, and even LP holdings like Uni-v2, have become token treasuries (EIP-4626).
-
ENS, Cryptopunks, Cryptokitties, and other non-fungible tokens gave rise to today’s NFT standards (EIP-721). Since then, there have been many improved implementations, such as ERC721A.
-
The above standards are protocols (contracts) that do not require changes to the Ethereum Virtual Machine (EVM). These are known as ERC standards.
-
There are also standards like deploying contracts on semi-specific addresses, which added the CREATE2 opcode at the EVM level (EIP-1014), making it a CORE standard. This allows Opensea to deploy Seaport at the same address on all chains (for everyone’s convenience).
I recommend starting with the main ERC standards and understanding the best example contracts for each standard. You can find information about these standards on my dashboard, which covers each standard:
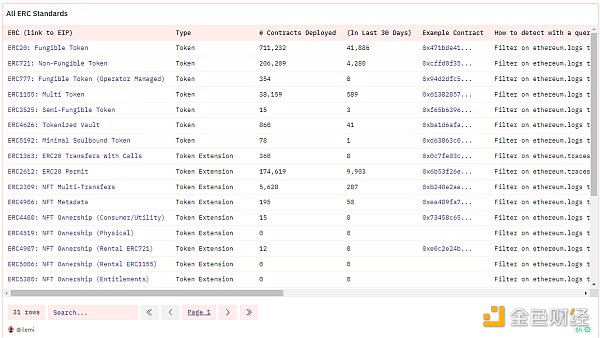
Explanation of each ERC/EIP, with trends and examples (#1)
These standards are important because they are universal across all protocols. Regardless of any unique complexity added, if it’s a DEX, you know to first look for the liquidity of ERC20 tokens and search for some transfers in and out of the liquidity pool. From there, you can piece together complex protocols.
Many patterns, such as oracles and utilization curves, have not yet become EIP standards. EIPs are not the only place to find standards; you can also find some standards at the protocol level, such as Opensea’s Seaport Improvement Proposals (SIP).
If you approach protocols with the mindset of “what have they built on existing patterns,” your life as an analyst will become easier and more interesting.
For simplicity, in the rest of this article, I will refer to the pattern as “standard”.
Spellbook tables and query analysis are standard abstractions
The standard-first approach also allows us to better understand the Spellbook tables and queries of other analysts. Let’s take dex.trades as an example. I have some assumptions: that the DEX must follow most of these standard patterns in order to remain compatible with other parts of the ecosystem.
Here is an example checklist when I look at a new DEX on the dex.trades table:
-
Standard: You can exchange one ERC20 token for another ERC20 token. We represent each exchange as a row in the table.
-
Standard: The circulating supply must already exist somewhere, most likely in a vault contract similar to ERC4626 (where some new tokens represent the deposited circulating supply).
-
In-depth: We like to put the “liquidity contract” that best represents the “token pair” in the project_contract_address column.
-
Standard: The liquidity contract holds two or more tokens.
-
In-depth: I would input the project_contract_address into Etherscan to see which tokens the contract holds (if any, some contracts like Balancer v2 track internal balances used on pools).
-
Standard: This type of liquidity contract is usually produced by a factory.
-
In-depth: Then I would click into the project_contract_address to create a transaction link and see if there is a factory contract. If not, this indicates to me that each trading pair may be really complex – or it only supports a certain token/mechanism.
-
Standard: Users usually call a “router” contract instead of the liquidity contract (ETH → USDC, then USDC → Aave, completing the ETH → Aave exchange).
-
In-depth: How many contract calls are there between the top-level contract called by the user (wallet signer) and the actual liquidity contract (project_contract_address)?
-
Is the top-level contract related to the DEX/aggregator or more complex like ERC4337?
-
Standard: Different DEXs can be optimized for different types of tokens.
-
In-depth: The addresses for selling (swapping in) or buying (swapping out) tokens are token_sold_address and token_bought_address, respectively.
-
What kind of tokens are usually bought/sold? (rebase-type, stablecoins, volatile, etc.)
-
Where does the token come from? Is it a regular ERC20 or something more specialized?
-
Some tokens have additional transfer logic. I would check the transaction logs to see if any special events occurred with these two tokens.
-
Standard: Criteria for yield farming/rewards tied to incentive liquidity pools
-
In-depth: Again, I would look at the “project_contract_address” to create a transaction link and see if the initial transaction created other contracts.
While reviewing this list, I used the EVM Quickstart Dashboard to jot down interesting transaction examples and tables.
There’s also an article: How to Analyze Any Ethereum Protocol or Product in Five Minutes
I also created some auxiliary queries, such as this transaction browser query, which can display all tables to be queried for a given transaction hash:
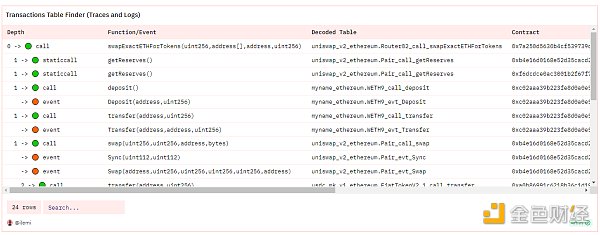
The standard priority analysis method deepened my understanding of this new DEX in the context of existing DEX standards.
Advanced SQL Functions
With these Ethereum concept prompts, let’s do some advanced queries and functions. Today, we will discuss the following topics:
-
DuneSQL specific functions and types
-
Advanced transformations (values/CSV, pivot, window functions, cross join, unnest, cumulative sum, forward/backward fill)
-
Array functions
-
JSON functions
In this guide, all SQL examples will be Ethereum-centric. Please remember that DuneSQL is just a fork of Trino SQL.
If you want to optimize your queries, you should check out our query optimization checklist. Dune also has a larger engine and features like materialized views that can enhance your query capabilities.
DuneSQL Specific Functions and Types
Dune has added a series of functions and types to make the processing of blockchain data more convenient and accurate (based on existing TrinoSQL functions).
**First, familiarize yourself with the binary type.** Binary is any value with a 0x prefix (also known as byte/hexadecimal), and its query speed is almost twice that of varchar. You may encounter cases where certain 0x values in the Spellbook table or uploaded datasets are entered as varchars. In such cases, you should use from_hex(varchar_col) when performing any filtering or joining. Some longer binary variable values (such as function calldata or event log data) can be split into several blocks (usually 32 bytes, or split into 64 characters using bytearray_substring), and then converted into numbers (bytearray_to_uint256), strings (from_utf8), or boolean values (0x00=FALSE, 0x01=TRUE). You can see all bytearray functions in the documentation through examples.
For string-based functions like CONCAT(), you need to convert varbinary type to varchar type, which is common when creating blockchain explorer links. We have created functions like “get_href()” and “get_chain_explorer_address()” to simplify this process, and you can find examples here.
**The other unique DuneSQL types are unsigned integers and signed integers (uint256 and int256).** These custom implementations can capture values up to 256 bytes more accurately, surpassing the limit of large integers with 64 bytes. It should be noted that uint256 cannot be negative, and mathematical operations (such as division) are not compatible for both types. In this case, you should use “cast(uint256_col as double)”. You will see me do this later when dividing by token decimals.
If you are dealing with Bitcoin or Solana data, they are stored in base58 encoding for many values. You need to use frombase58(varchar) to convert the value to binary, and then you can use all the operations mentioned above. A good example for Bitcoin is identifying ordinals, and for Solana, it is decoding transfer data.
Advanced Transformations
VALUES and CSV Upload
In many cases, you need to use custom mappings. For example, let’s take a look at queries for all ERC standards deployments. You will see that I use the “VALUES () as table(col1, col2, col3)” pattern to define a “table” that I can use as a CTE:

I can also upload it as a CSV and then query it as a table, but since the mapping is very small, I manually perform the operations in the query.
Pivoting
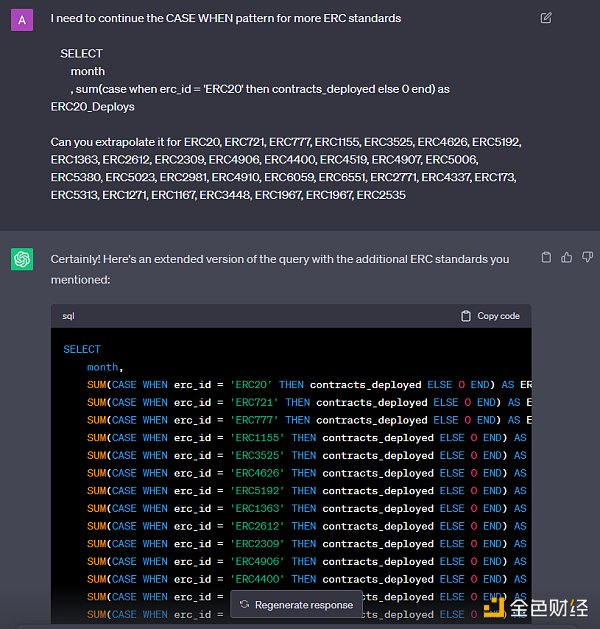
Pivoting is often referred to as expanding a column that contains different categories into multiple columns (one column for each category), and vice versa, folding multiple columns into one column. In the same ERC query above, I first calculate the number of contract deployments by erc_id and month in the GROUP BY. So there are about 30 records per month, and one record per ERC. I want each ERC to be its own column for charting, and the number of months since Ethereum’s launch as the number of rows. To do this, I take SUM(case when erc_id = ‘ERC20’ then contracts_deployed else 0 end) for each value of erc_id. Note that the native DuneSQL (TrinoSQL) does not yet have a pivot function that dynamically performs this operation.
I don’t want to type the same thing 30 times, so I gave an example to chatgpt and asked them to help me write it. Once you figure out the basic logic, you should use chatgpt to write most of the queries (**or use our Dune LLM wand feature) **!
Window Functions
Window functions can be initially difficult to understand because they require you to imagine a table as multiple different tables. These “different tables” are split from the main table through “partitions”. Let’s start with a simple example of finding the last call (trace) address for each transaction in a block. I found a block with only three transactions:

If you’re not familiar with transaction tracing, it’s a collection of all calls after the root transaction call. So in the first transaction to the Uniswap router above, the router will call the liquidity contract and then call the token contract to send tokens back and forth. When the calls are linked, there is an increasing [array](https://openethereum.github.io/JSONRPC-trace-module#:~:text=Every%20individual%20operation.-,traceAddress%20field,-traceAddress%20field) called trace_address. We want to get the maximum trace_address value for each transaction. To do this, we partition by tx_hash and then assign a counter value in descending order for each trace_address, so the final trace value is 1. The SQL code is as follows:
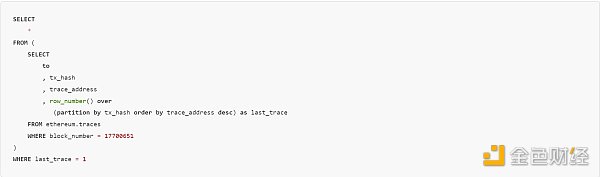

Query link
row_number() is a function for windows, which simply counts up from 1 based on the sorting of rows. It treats each tx_hash as its own table (window) and applies the function to it. One trace recorded 257 primary calls!
If you run the query without using last_trace = 1, you will see the incremental count restart three times (once for each transaction). Many different functions can be used with windows, including typical aggregate functions such as sum() or approx_percentile(). We will use more window functions in the examples below.
Sequences, Unnest, Cross Joins, Cumulative Sums, Forward/Backward Filling
These five functions are basic functions for time series analysis. These concepts have also caused the most trouble for people, so if you still don’t understand, you can play around with the following subqueries by adjusting different rows.
I will use a query to demonstrate these concepts, which captures the historical nominal balance and dollar balance of ETH, ERC20, and NFT tokens held by a certain address.
The query first calculates the total amount of tokens spent or received in Ethereum transfers, ERC20 transfers, NFT transfers, and gas consumption – if you are not familiar with the tables and logic involved, it is necessary to spend some time understanding these CTEs.
An address may be active on certain days and inactive on other days – we need to create a table to fill in the missing days in between to get an accurate view. Since calculating the number of days takes a long time, I truncate all data to months using date_trunc. When creating all “months” since the first transfer to the address, unnest is used.
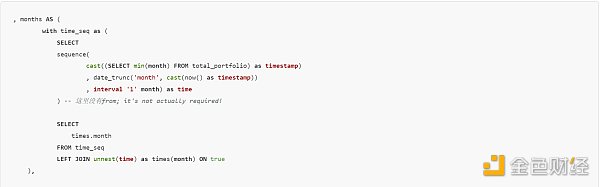
sequence creates an array that contains the values from the first input to the second input, and the intervals between the third inputs. I want each array value to be a row, so I use unnest on the created time column and rename it as month in the alias. I use LEFT JOIN … on true to make each array value appear only once, as the time_seq table has only one value. If the time_seq table had two row values, I would get duplicate months. It becomes difficult to track this situation when unnesting more complex structures such as JSON (we will unnest at the end of the article).
Now, I not only need to track the balance for each month, but also need to track the balance of each different token (contract address) held by the address. This means I need to use “CROSS JOIN”, which can take any set of columns and create all possible combinations of them.

I am simultaneously tracking the asset type and asset address, because some contracts can mint both erc20 and NFT tokens. The key here is SELECT * FROM distinct_assets, months, which takes the “month”, “asset”, and “asset_address” columns and creates such a table:
The above subquery also joins all balance changes, which means I can capture the total balance of any token in any month using the cumulative sum of the differences. This is actually an easy way to fill values forward. To perform the cumulative sum, I use sum() in the window function, partitioned by each asset and asset_address, starting from the earliest month.
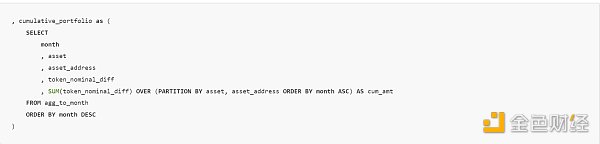
In the last part of the query (after adding external API prices, DEX prices, and NFT transaction prices), I want to fill in the days with no transactions or no API data with forward and backward filling. To do this, I used a creative COALESCE, LEAD/LAG, and IGNORE NULLS window functions. If a month does not have a price, it will take the previous (or next) non-null value as the price for that month.
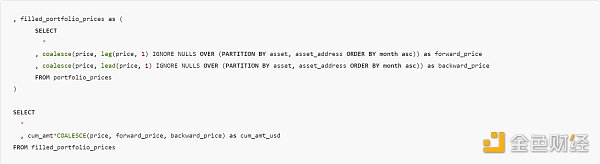
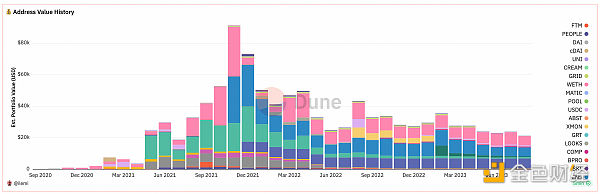
Please note that this is only an estimate, as prices for some wrapped tokens and shared contract NFT collections (such as artblocks) are difficult to obtain.
This query is very dense and difficult to understand. If you want to understand what is happening, you can run each CTE one by one and make adjustments along the way! To use these functions well, you must be good at imagining what each CTE table looks like in your mind without running the CTE table.
Array Functions
An array is a list of values of the same type, with indexes starting from 1. You can create an array like this: array[1,2,3]. But it is more common to create arrays during the aggregation process. Here is a query that finds the smartest NFT traders and summarizes their total trading volume and trading collections in the past 30 days.

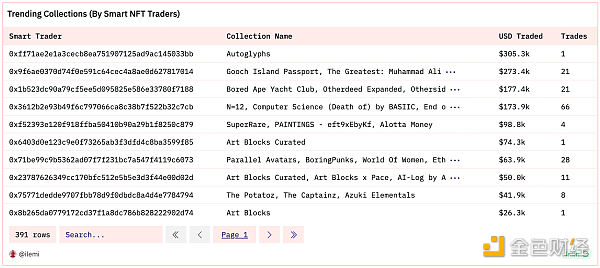
Query link
Arrays can also use many functions. You can use cardinality to get the length of an array, and you can use contains or contains_sequence to check if a value exists in the array. We can query the exchange path (ERC20 token address array) of all Uniswap routers, where the path length is at least three tokens and passes through either WETH -> USDC or USDC -> WETH.

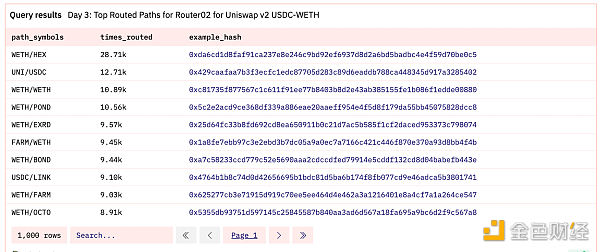
Query link
We can see that the WETH/HEX exchange has the highest number of routes routed through the WETH-USDC trading pair. If you are interested in this query, there is a complete video explanation here.
There are some advanced array functions called “lambda functions,” which are very useful for running more complex logic between array values. I will give an example in the JSON section. If you have used python/pandas, it is similar to “df.apply().”
JSON Functions
JSON allows combining variables of different types into a nested structure. To extract values from JSON (there are many additional parameters available to control path logic, missing data handling, and error handling, which apply to all of these):
-
json_query(varchar_col, ‘strict $.key1.key2’):
-
This function extracts data from the JSON column based on the given path.
-
The extracted data is preserved as a JSON structure in the result, but the type is still varchar.
-
json_value(varchar_col, ‘strict $.key1.key2’):
-
It extracts data from a single return value, such as text, number, or array. It does not return a JSON structure.
-
If you expect to return a value but it doesn’t, consider using json_query instead.
-
json_extract_scalar(json_col, ‘$.key1.key2’):
-
Same as json_value, but only works when the column is already of JSON type. It is confusing that json_query and json_value do not work on JSON types.
Used to create JSON type columns/values:
-
json_LianGuairse is used to convert a JSON formatted string to a JSON type.
-
json_object is used to build a JSON object based on specified key-value pairs.
The most famous JSON type example in Ethereum is the Application Binary Interface (ABI), which defines all the functions, events, errors, etc. of a contract. Here is the “transferFrom()” part of the ABI for ERC20 tokens:
 I have created a query that allows you to easily view all the inputs and outputs of functions in a contract using ABI. The “abi” column of “ethereum.contracts” is a JSON array (stored as “array(row())”).
I have created a query that allows you to easily view all the inputs and outputs of functions in a contract using ABI. The “abi” column of “ethereum.contracts” is a JSON array (stored as “array(row())”).
We need to extract inputs/outputs from each value. To do this, I first unnest the abi, and then use json_value to get the function name and state mutability. Since a function can have multiple inputs and outputs, I create a new JSON array by extracting the inputs[] array. Please note that although json_query returns a JSON structure, its type is varchar, so I need to use json_LianGuairse to process it first and then convert it to a JSON array array(row()).
 After writing a few more lines (which I omitted above) for cleaning up and aggregating all the inputs/outputs into a single line for each function, we get the following result:
After writing a few more lines (which I omitted above) for cleaning up and aggregating all the inputs/outputs into a single line for each function, we get the following result:
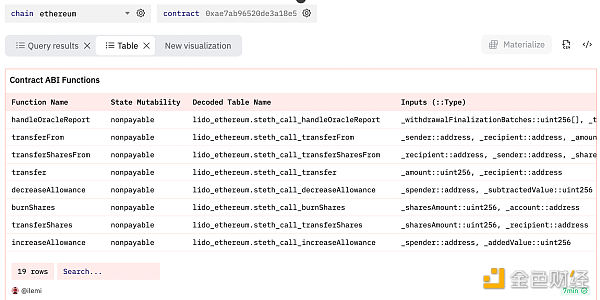
Query link
Now, do you remember the lambda functions I mentioned earlier for arrays? Let’s use them here. I will filter out view and pure functions from the ABI, and then create an array based on the function names only. Lambda functions will iterate through each value in the array and apply specific logic. So, I first use filter to keep only the functions that meet the conditions, and then transform the filtered array, which takes the ABI json of each function and returns only the name. x represents the value of the array, and the part after -> is the function I apply to x. I also use a window function to keep only the most recently submitted ABI based on the created_at column. The complete SQL query for modifying the contract functions with the seaport namespace is as follows:

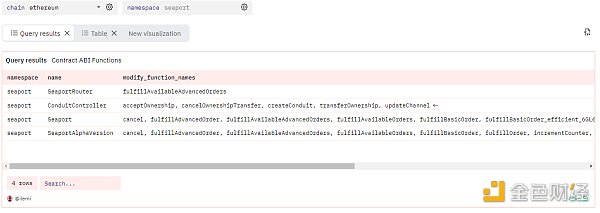
Query link
Challenge: Want to truly test your understanding of each concept in this guide? Try reverse engineering the transaction browser query I mentioned earlier. I used a lot of tricks in it.)
Congratulations on becoming a data expert
Take your time to digest and practice these concepts, making sure to fork and play with each query. Just reading alone does not count as mastery! Use the standards, types, transformations, and functions you have learned to unleash your true creativity in queries.
Once all the content in this article becomes familiar to you, I can easily say that you are already in the top 1% of data experts on Ethereum. After that, you should focus more on developing your soft skills, such as browsing communities, asking good questions, and telling engaging stories. Or, you can delve into statistics and machine learning – they are likely to become more relevant in the Web3 space in about six months.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- CertiK Security Report Nearly 1 billion USD will be stolen in 2023 due to fraud, vulnerability exploitation, and hacker attacks.
- Doodles version of the holey shoes sold out in 3 days, blue-chip NFTs sell to save themselves.
- With the innovative low transaction volume, where is the way out for NFTs?
- After Vitalik’s account was hacked, he released phishing information. Besides phishing attacks, what other ways of fund fraud should users be alert to?
- Opinion If the Bot track cannot achieve an unforkable state, it will be very difficult to achieve sustainable revenue.
- Will Micro-Rollup be the next wave when applications become Rollup?
- Inventory of Common Scams in the Cryptocurrency Field