Decentralization explorers of Rollup: Polygon, Starknet, and Espresso
Exploration of Rollup decentralization: Polygon, Starknet, and Espresso.Written by: Scroll
As the use of Rollups increases and applications hosted by the ecosystem, the user’s migration costs will increase, and centralized sorters will gain monopolistic influence over pricing. Controllers of centralized sorters have reason to extract value from users to the maximum extent possible (MEV) both directly (e.g. through fees) and indirectly (e.g. through front-running transactions, sandwich attacks, etc.)—Espresso
As the Espresso team mentioned, centralized Rollups will ultimately face the problems of monopolistic pricing and MEV. Furthermore, centralized Rollups essentially break composability, leading to fragmented Rollups.
However, almost all Rollups are still centralized at present because building a decentralized, permissionless, and scalable Rollup is extremely challenging. Another reason is that launching centralized Rollups first can help incubate the ecosystem and capture market share.
- As the countdown to the debt ceiling negotiations begins, Biden and Republican leaders reassure the public that there will be no default.
- Is Binance joining ORC-20, marking the end of BRC-20?
- Understanding the business model and product components of Centrifuge, one of the leading companies in RWA
And when we talk about decentralized Rollups, especially zkRollups, there are two levels of decentralization. The first is the decentralization of the verifiers, and the second is the decentralization of the sorters. Achieving complete decentralization also requires solving the coordination problem between sorters and verifiers.
In the trend of modularity, there are currently three types of participants in decentralized Rollups. The first aims to achieve fully decentralized Rollups and has proposed complete solutions. The second is a protocol that aims to solve the verifier network. Finally, there are multiple solutions in progress to achieve the decentralization of sorters.
Decentralization of Rollups

In zkRollups, Polygon and Starknet have proposed solutions to achieve decentralization of their Rollups.
Polygon

Polygon zkEVM used POD (Proof of Donation) before introducing POE (Proof of Efficiency), which allowed sorters to bid on the opportunity to create the next batch of transactions. However, this created a problem where a single malicious party could control the entire network by bidding the highest.
With POE, sorters and verifiers will participate most efficiently in permissionless networks under their own hardware conditions. Anyone can join Polygon zkEVM as long as it is economically viable.
In Polygon’s zkEVM, the sorter requires 16GB of RAM and 4 CPU cores, while the prover requires 1TB of RAM and 128 CPU cores. In addition, there is a role called the aggregator, responsible for collecting L1 data, sending it to the prover, receiving proofs, and submitting them to L1. We can think of the aggregator and the prover as the same entity, because the relationship between the aggregator and the prover is very simple, with the aggregator paying the prover to produce proofs.
This architecture is very simple: any sorter can pack transactions on L1 based on the previous state without permission, and update the corresponding state accordingly. At the same time, any aggregator can submit proof to verify the updated state.
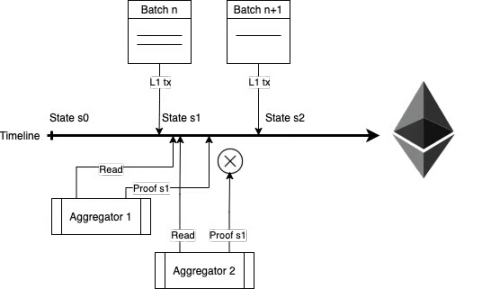
In POE, efficiency not only refers to network efficiency when participants compete with each other, but also to the economic efficiency of sorters and provers themselves. In L2, sorters and provers share transaction fees, with sorters paying batchFee to the aggregator to generate proof. This ensures that participants have economic incentives to contribute to network efficiency, leading to a more robust and sustainable ecosystem.
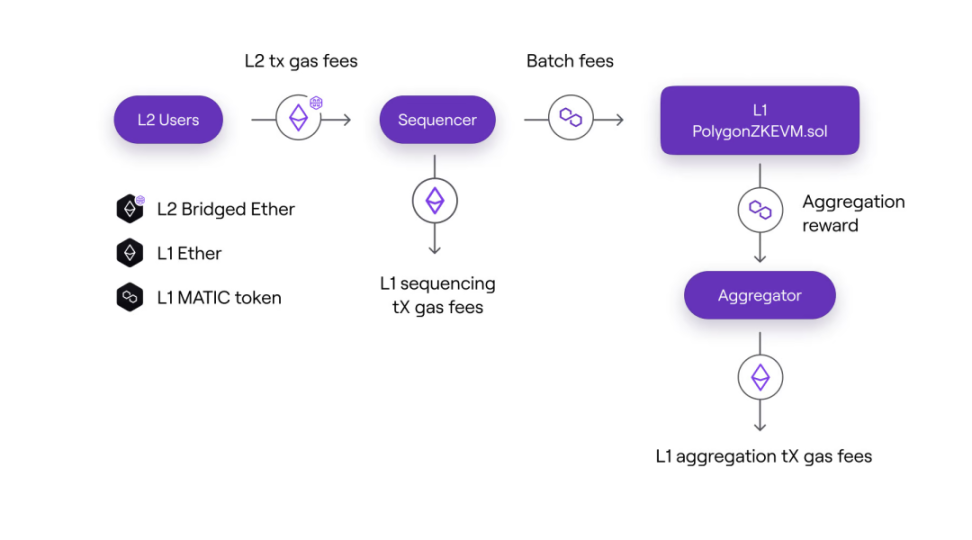
Sorter
- Income: L2 transaction fees
- Cost: batchFee (calculated in $MATIC) + L1 transaction fees (calling sequenceBatches method)
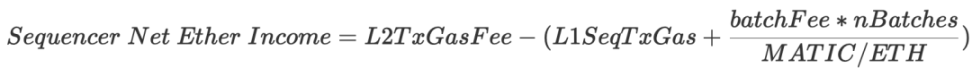
Aggregator (Prover)
- Income: batchFee (calculated in $MATIC)
- Cost: proof cost + L1 transaction fees (calling verifyBatchesTrustedAggregator method)
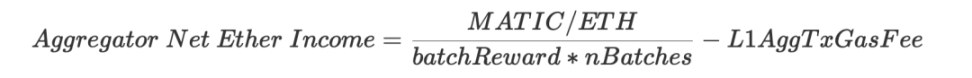
Coordinator: batchFee
- Initial parameters
- batchFee = 1 $MATIC
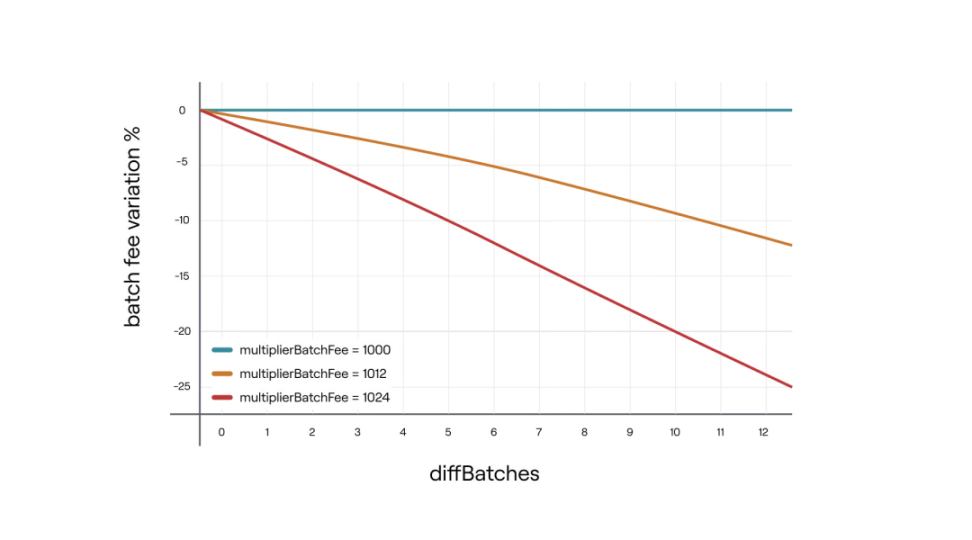
- veryBatchTimeTarget = 30 minutes. This is the target time for verifying batches. The protocol will update the `batchFee` variable to achieve this target time.
- multiplierBatchFee = 1002. This is the batch fee multiplier, ranging from 1000 to 1024, with 3 decimal places.
- Regulator
- diffBatches: The number of batches aggregated with >30 minutes minus the number of batches with <=30 minutes. The maximum value is 12.
- Coordination process
- When diffBatches > 0, increase the aggregation reward to incentivize aggregators.
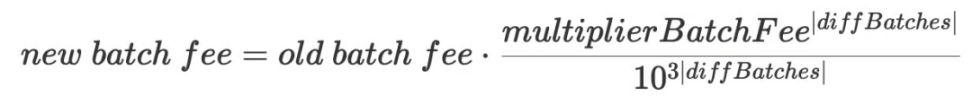
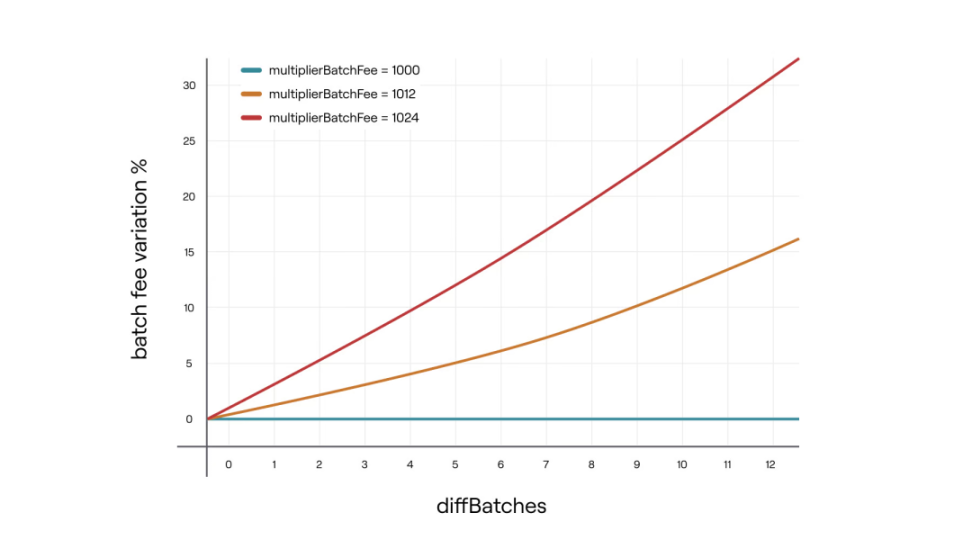
- When diffBatches < 0, decrease the aggregation reward to suppress aggregators and slow down the aggregation process.
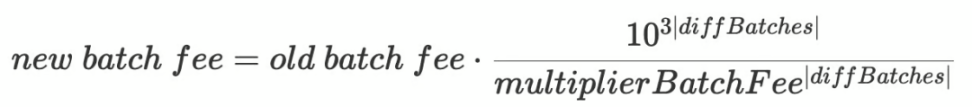
Starknet

Starknet is also building a fast-confirmed, permissionless, and scalable Rollup. Although the final specification for a decentralized solution has not yet been reached, they released some drafts on the forum a few months ago.
Compared to the simple mechanism of Polygon zkEVM, Starknet’s solution is more complex because it includes chained proof-of-a-protocol in L2 consensus and proof networks.
Sorter
Starknet proposes a double ledger consensus protocol instead of simply adding a consensus layer in the sorter layer. In this protocol, L2 serves as the live protocol for fast response, while L1 checkpoints serve as the safe protocol for final confirmations.
Various consensus mechanisms, such as witch-resistant PoS systems like Tendermint or DAGs, can be used for the live protocol of L2. On the other hand, L1’s safe protocol involves multiple contracts that handle stake management, proof verification, and state updates.
The typical workflow of this double ledger consensus protocol is as follows:
1. First, the output of the L2 live ledger is used as the input of the L1 safe ledger to generate a checked live ledger.
2. Then take the checked live ledger as input and feed it back into the pure consensus protocol of L2, ensuring that the checked live ledger is always a prefix of the liveledger.
3. Repeat the above process.
There is a trade-off between cost and delay when building a dual ledger consensus protocol. The ideal solution aims to achieve low cost and fast final confirmation at the same time.
To reduce gas costs on L2, Starknet divides checkpoints into “minute-level” and “hour-level”. For “minute-level” checkpoints, only the state itself is submitted to the chain, while the remaining data (validity proof, data availability, etc.) is sent via the StarkNet L2 network. These data are stored and verified by StarkNet full nodes. On the other hand, “hour-level” checkpoints are publicly verified on L1. Both types of checkpoints provide the same final confirmation. For “minute-level” checkpoints, the validity proof is verified by StarkNet full nodes and can be published by any node on L1 to give “minute-level” checkpoints L1 finality. Therefore, the prover needs to generate a small proof for widespread propagation on the L2 network.
To further reduce delay, Starknet proposes a leader election protocol to pre-determine the leader. The basic logic is as follows: the leader of the current period i is pre-determined based on the L1 pledge amount and some randomness. Specifically, in period i-2, the leader_election method flattens the sorter in lexicographic order based on the pledge amount in period i-3. Then, a transaction is sent to update the random number and randomly select a point. The sorter corresponding to the position where the point falls will become the leader of period i.
Prover
Under the POE module, participants compete openly, which may result in a winner-takes-all situation. Starknet attempts to implement a decentralized risk competition mechanism. Here are some optional solutions:
- Round-robin system: This can partially solve the centralization problem, but may not be able to find the best candidate for proof work through incentive mechanisms.
- Based on pledge: The sorter’s probability of being elected as a proof provider is determined by the amount they pledged.
- Commit-Reveal scheme: The first submitter needs to stake tokens to gain a temporary monopoly opportunity, and then generate proof within that time window. To prevent DDoS attacks, if the former cannot generate proof in time, the required staked tokens for the latter will grow exponentially. Although the network may lose machines with the best performance under this mechanism, it can cultivate more proof providers.
In addition to the competition between verifiers, the entry threshold should be lowered so that more verifiers can participate in the network. Starknet has proposed a complex protocol that uses recursive proofs, called chain-based proof protocols.
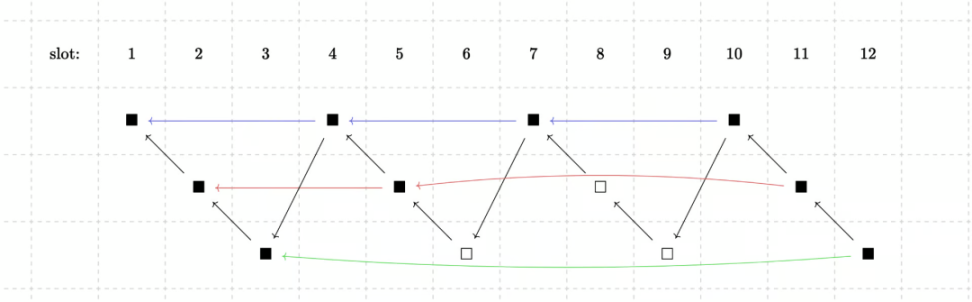
In chain-based proof protocols, the blockchain itself is divided into several different branches. This way the proof can not only be recursive, but the proof generation can also be concurrent. For example, in a setting of 3 branches, 12 black blocks are divided into 3 rows, each of which represents a branch. We can think of each branch as a subchain, and each block in the subchain should prove the previous block. From the perspective of the entire chain, slot n needs to prove slot n-3. The 3-block gap allows sorter to calculate and purchase proofs in advance. This is somewhat similar to sharding, where an attacker only needs to control one branch to control the entire verifier network.
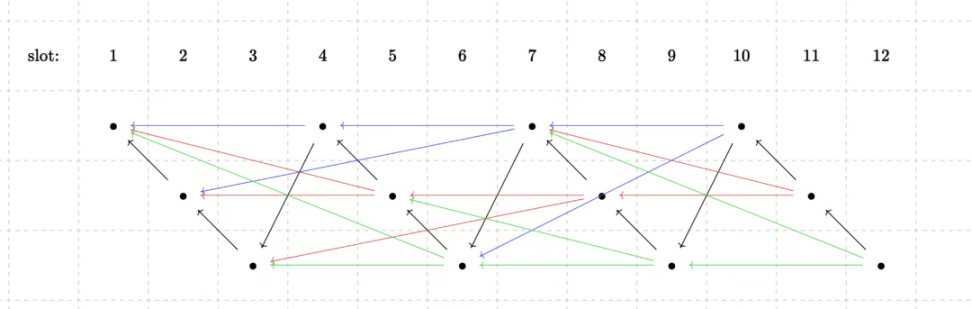
To interweave these branches together, Starknet has proposed a weaving technique that can merge multiple nodes together to collectively verify the legitimacy of transactions and ensure the consistency and reliability of transaction records.
One solution is to require each slot to merge with several branches at the same time. Another solution is to alternate each branch and try to merge with the remaining branches, thereby reducing the proof workload. Of course, this is also an open problem, and there may be better solutions in the future.
Coordination
In order to actively ensure that verifiers have enough profit space, Starknet has proposed a practice that refers to the EIP1559 scheme: setting the base fee as the lower limit of the verifier’s resource price, actively conducting price discovery, and allowing sorter to use tips to incentivize verifiers. This way, verifiers will always be overpaid, and only extreme cases will affect the proof process. Otherwise, if the reward received by verifiers is close to the market price, slight fluctuations may cause the verifier to stall.
Decentralization of Verifiers

From the perspective of Rollups, proof-of-workers are easier to implement than sorters for decentralization. Furthermore, the current proof-of-workers are a performance bottleneck and need to keep up with the sorter’s batch processing speed. In the absence of decentralized sorters, decentralized proof-of-workers can also serve centralized sorters.
In fact, not only Rollups, but zkBridge and zkOracle also need a proof-of-worker network. They all need a powerful distributed proof-of-worker network.
In the long run, a proof-of-worker network that can accommodate different computing capabilities is more sustainable, otherwise the machines with the best performance will monopolize the market.
Proof market
Some protocols do not coordinate the relationship between sorters and proof-of-workers, but directly abstract coordination into a proof market. In this market, proofs are goods, proof-of-workers are producers of proofs, and protocols are consumers of proofs. Under the “invisible hand”, market equilibrium is the most efficient.
Mina

Mina has established a proof-of-marketplace called Snarketplace, where Snark proofs are traded. The smallest unit here is a single transaction’s Snark proof. Mina uses a recursive proof of a state tree called Scan State.
Scan State is a binary tree forest, where each transaction is a node. A single proof is generated at the top of the tree that can prove all the transactions in the tree. Proof-of-workers have two tasks: first, to generate a proof, and second, to merge the proof.
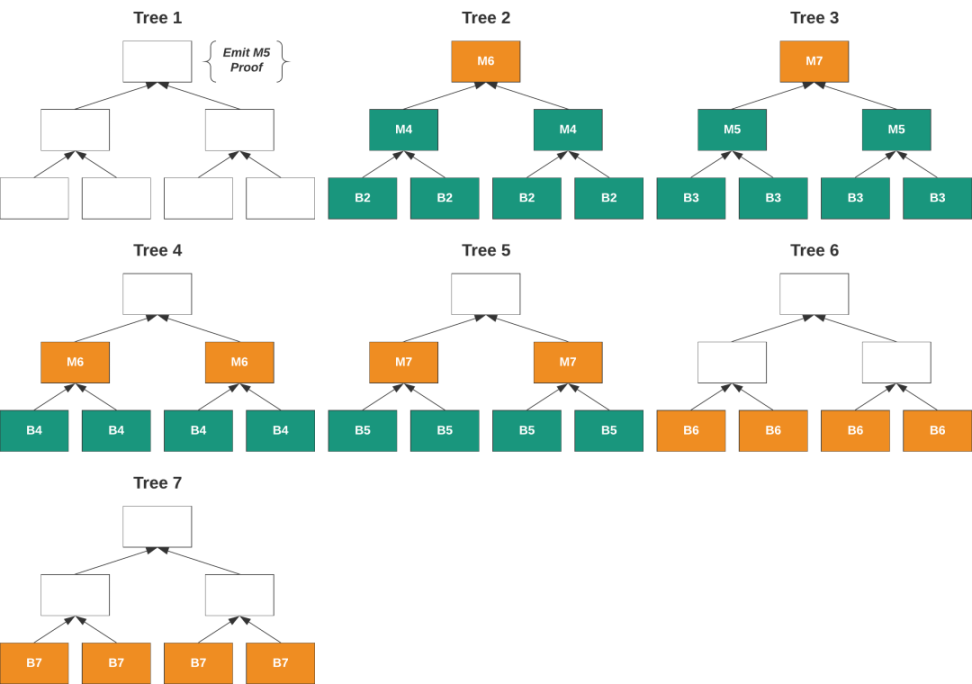
Once the proof-of-workers have completed their work and submitted their bids, the block producer of the Mina protocol will choose the lowest bidder. This is also an equilibrium price, as bidders will submit bids higher than the cost of the proof, and block producers will not buy unprofitable proofs.
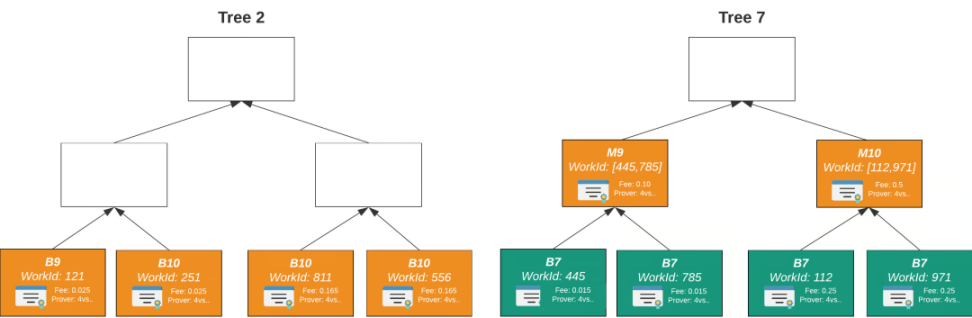
=Nil; Foundation

Mina’s proof-of-marketplace is designed specifically for its own protocol, while =nil; Foundation proposes a general proof market to serve the entire market.
The market’s service consists of three components: DROP DATABASE, zkLLVM, and Proof Market.
- DROP DATABASE: a database management system protocol that can be considered a DA layer.
- Proof Market: an application that runs on DROP DATABASE, similar to a “decentralized exchange” of zk proofs as some people call it.
- zkLLVM: a compiler that translates high-level programming languages into inputs for provable computation protocols.
Each proof is made up of its unique inputs and circuits, so each proof is unique. The circuit defines the type of proof, similar to the way financial terms define “trading pairs.” Furthermore, different proof systems introduce more circuits.
The workflow is as follows: proof requesters can write code in high-level programming languages, which is then fed to zkLLVM through a toolchain to generate a single circuit, which will become a unique trading pair in the market.
For proof requesters, they can make trade-offs between cost and time. The provers will also consider their own computing power and income. Therefore, in the market, there will be different computing powers, where high computing power will generate proofs faster but at higher costs, and low computing power will generate proofs slower but at lower costs.
Two-Step Commitment

Recently, Opside proposed a two-step commitment scheme for decentralized provers networks. The scheme divides proof submissions into two stages to avoid the situation where the fastest prover always wins.
- Step 1: Submit the hash of the zero-knowledge proof for block T.
- Starting from block T+11, no new provers are allowed to submit hashes.
- Step 2: Submit the zero-knowledge proof.
- After block T+11, any prover can submit the zero-knowledge proof. If at least one zero-knowledge proof passes the verification, it will be used to verify all submitted hashes, and verified provers will receive corresponding PoW rewards based on the proportion of their collateral. If there is no zero-knowledge proof that passes verification before block T+20, all provers who submitted hashes will be punished. Then the sorter is reopened, and new hashes can be submitted to go back to step 1.
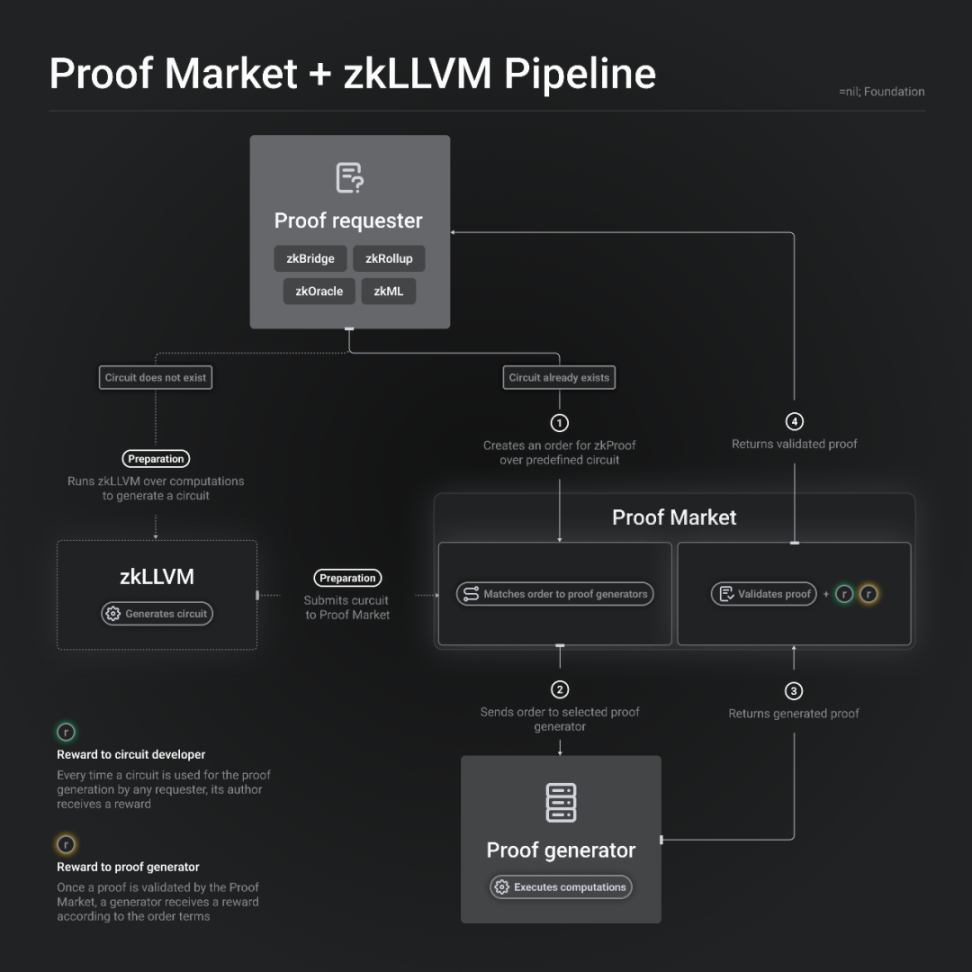
This approach can accommodate different levels of computing power. However, the required collateral still introduces a degree of centralization.
Decentralization of Sorters

Decentralizing sorters is more complicated than validators because sorters have the power to pack and arrange transactions, and issues such as MEV and revenue distribution need to be considered.
Given that Ethereum will prioritize responsiveness over liveness, L2 solutions should complement such trade-offs by prioritizing responsiveness over liveness. However, decentralized sorters themselves sacrifice responsiveness compared to centralized sorters. Therefore, various optimizations need to be implemented to address this dilemma.
Currently, there are three different schemes for decentralized sorters. The first scheme is achieved by optimizing the consensus mechanism. The second scheme involves a shared sorter network. The third scheme is based on L1 validators.
Consensus

The consensus protocol is primarily responsible for sorting transactions and ensuring their availability, rather than executing transactions. However, as mentioned earlier, adding another consensus layer directly is not a simple solution.
To improve responsiveness, a common approach is to rely on a smaller set of validators. For example, Algorand and Polkadot use a randomly sampled smaller committee to batch process transactions. All nodes use a random beacon and verifiable random function (VRF), where the probability of being included in the committee during a given period is proportional to their staked amount.
To reduce network traffic, smaller data availability (DA) committees can be used. Or, Verifiable Information Dispersal (VID) can be adopted. VID distributes the erasure code of the data to all participating consensus nodes, such that any subset of nodes holding a sufficiently high staked proportion can collaborate to recover the data. The trade-off of this approach is to reduce broadcast complexity but increase data recovery complexity.
Arbitrum instead opts for a sorter committee composed of reputable entities, such as ConsenSys, Ethereum Foundation, L2BEAT, Mycelium, Offchain Labs, P2P, the Distributed Ledger Research Center (DLRC) at IFF, and Unit 410. The trade-off of this approach is to compensate for quantity with decentralized quality.

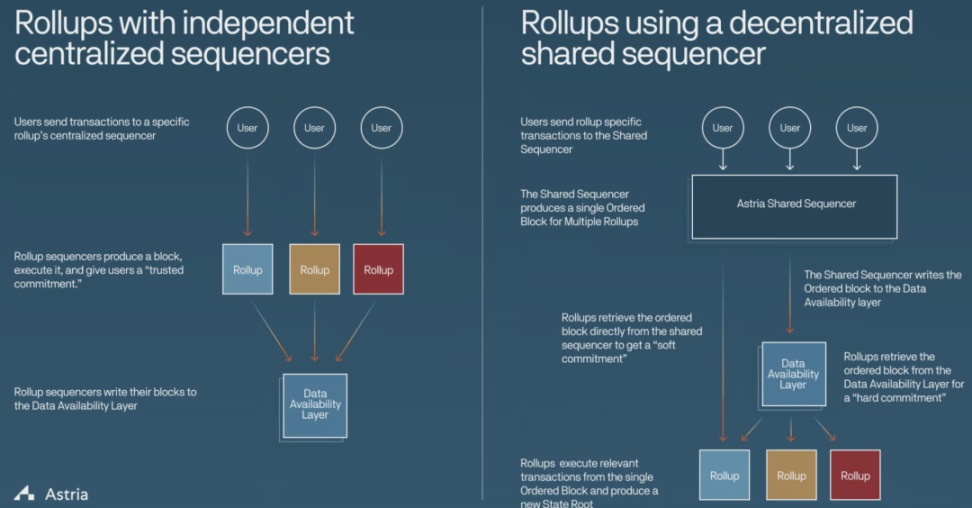
Shared Sorter Network

Sorters play a critical role in modular blockchains, especially in Rollups. Each Rollup typically builds its own sorter network, which not only leads to redundancy but also hinders composability. To address this problem, some protocols propose building a shared Rollup sorter network. This approach reduces the complexity of achieving atomicity, composability, and interoperability, which are urgently needed by users and developers in open, permissionless blockchains. In addition, it no longer requires a separate sorter network’s light client.
Astria

Astria is developing a middleware blockchain for Celestia’s Rollup ecosystem, which includes its own distributed sorter collection. This sorter collection is responsible for accepting transactions from multiple Rollups and writing them to the underlying layer without executing them.
Astria’s role is mainly focused on transaction sorting, operating independently of the underlying layer and Rollups. Transaction data is stored on the underlying layer (such as Celestia), while Rollup full nodes maintain the state and execute operations. This ensures that Astria is decoupled from Rollups.
For finality, Astria provides two levels of Commitment:
- Soft commitment: allows Rollups to provide fast block confirmations to their end-users.
- Firm commitment: same speed as the underlying layer, ensuring higher security and finality.
Espresso

Espresso has made significant contributions in zero-knowledge technology. They are currently developing a comprehensive solution for a decentralized sorter that can be applied to Optimistic Rollups and zkRollups.
The decentralized sorter network consists of:
- HotShot consensus: prioritizes high throughput and fast finality over dynamic availability.
- Espresso DA: combines committee-based DA solutions and VID, where high-bandwidth nodes provide data to all other nodes. The availability of each individual block is also supported by small randomly-elected committees. VID provides reliable but slower backups, guaranteeing availability as long as a sufficiently high proportion of the staking weight of all nodes is not threatened.
- Rollup REST API: Ethereum-compatible JSON-RPC.
- Sorter contract: verifies HotShot consensus (i.e., as a light client) and records checkpoints (i.e., cryptographic commitments to transactions), manages the HotShot staking table.
- P2P network: Gossip protocol.
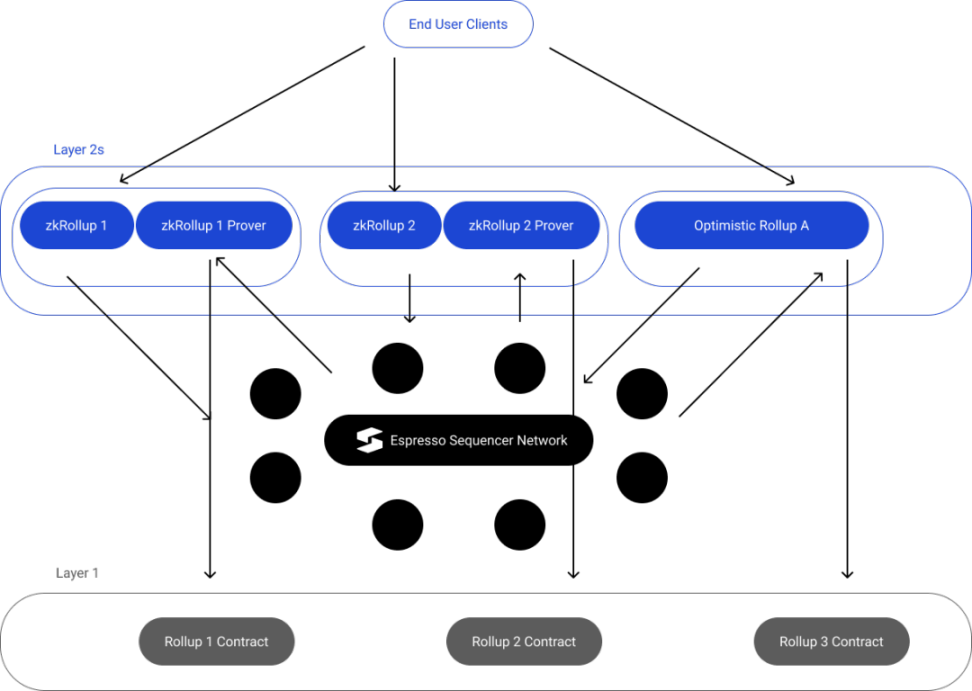
Compared to Astria, Espresso provides DA. Therefore, the workflow will be slightly different as described below:
1. User creates and submits transactions to the Rollup.
2. The transaction is propagated through the sorter network and kept in the memory pool.
3. Through the HotShot staking mechanism, a leader is designated, proposes a block, and propagates it back to the Rollup’s executors and verifiers.
4. The leader sends the transaction to the data availability committee and receives DA certificates as feedback.
5. The leader also sends the commitment to the block to the Layer 1 sorter contract, as well as the certificate used by the contract to verify the block.
Espresso introduces a Gossip protocol for proving, providing a more flexible user experience. It provides three options for transaction finality:
- Fast: Users can trust a Rollup server that has executed the transaction and generated a proof, or they can take advantage of HotShot’s low-latency execution of transactions.
- Moderate: Users can wait a short time to generate a proof and then check that proof.
- Slow: Users can wait for L1 verification status updates to get the updated state, without any trust assumptions or computation.
In addition to the above optimizations, Espresso plans to make the entire Ethereum validator set itself participate in running the Espresso sorter protocol. Using the same validator set will provide similar security, and sharing value with L1 validators will be more secure. Additionally, Espresso can leverage ETH re-staking solutions offered by EigenLayer.
Radius

Radius is building a trustless shared sorting layer based on zero-knowledge proofs that focuses on solving the MEV problem in L2, as L2’s revenue mainly comes from block space. The trade-off that needs to be considered is the balance between MEV and L2 revenue. Radius aims to eliminate harmful MEV and proposes a two-layer service.
The top layer is for regular user transactions and provides cryptographic protection against harmful MEV by using time-lock puzzles. Specifically, it adopts Practical Verifiable Delay Encryption (PVDE) technology, which generates zero-knowledge proofs for RSA-based time-lock puzzles within 5 seconds. This method provides a practical solution to protect users from harmful MEV. In short, the transaction content can only be known after the sorter determines the transaction order.
The bottom layer is designed for block builders and allows them to participate in revenue-generating activities while mitigating the negative impact of MEV.
Based Rollups

Based Rollup is a recent concept proposed by Justin Drake, in which L1 block proposers work with L1 searchers and builders to include rollup blocks in the next L1 block without permission. It can be viewed as a shared sorter network on L1. The pros and cons of Based Rollup are obvious.
On the positive side, Based Rollup leverages the activity and decentralization provided by L1, and its implementation is simple and efficient. Based Rollup also maintains economic consistency with L1. However, this does not mean that Based Rollup undermines its sovereignty. Although MEV is handed over to L1, Based Rollup can still have governance tokens and collect base fees. Based on assumptions, Based Rollup can leverage these advantages to achieve dominance and ultimately maximize profits.
Conclusion

Observing these proposals, it can be seen that the decentralization of Rollup still has a long way to go. Some of these proposals are still in the draft stage and need further discussion, while others have only completed preliminary specifications. All of these proposals need to be implemented and undergo rigorous testing.
While some Rollups may not explicitly propose corresponding decentralized solutions, they generally include emergency escape mechanisms to address single points of failure caused by centralized sequencers. For example, zkSync provides the FullExit method, allowing users to withdraw their funds directly from L1. When the system enters exodus mode and cannot process new blocks, users can initiate a withdrawal operation.
To achieve censorship resistance, these Rollups typically also allow users to submit transactions directly on L1. For example, zkSync uses a priority queue to handle this type of transaction sent on L1. Similarly, Polygon zkEVM includes a force batch method in L1 contract. When there is no aggregation within a week, users can call this method on L1 and provide the byte array and bathFee of the transaction to the prover.
It can be certain that the decentralization of Rollups will be a combination solution in the foreseeable future, which may include some of these important solutions or other innovative variants.
References
https://wiki.polygon.technology/docs/zkEVM/
https://ethresear.ch/t/proof-of-efficiency-a-new-consensus-mechanism-for-zk-rollups/11988/12
https://community.starknet.io/t/starknet-decentralization-kicking-off-the-discussion/711
https://docs.minaprotocol.com/node-operators/scan-state
https://blog.nil.foundation/2023/04/26/proof-market-and-zkllvm-pipeline.html
https://ethresear.ch/t/zkps-two-step-submission-algorithm-an-implementation-of-decentralized-provers/15504
https://ethresear.ch/t/shared-sequencer-for-mev-protection-and-profitable-marketplace/15313
https://hackmd.io/@EspressoSystems/EspressoSequencer
https://hackmd.io/@EspressoSystems/SharedSequencing
https://ethresear.ch/t/based-rollups-superpowers-from-l1-sequencing/15016
https://research.arbitrum.io/t/challenging-periods-reimagined-the-key-role-of-sequencer-decentralization/9189
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Deep Analysis: Exploring Hooked’s Ambitious Goals in Web3 Education through Collaboration with Animoca
- Is the ultimate goal of AI Web3? “Father of ChatGPT” launches encrypted wallet World App
- Why has Cosmos become the first choice for many developers in application chains?
- Dark Side of NFT History: Reviewing the Darkest Moments of 5 Blue Chip Tokens
- Conversation with Coinbase Protocol Director: How is Base, as a highly anticipated new Layer2, building its ecosystem step by step?
- How does ERC-6551 change the game by turning NFTs into Ethereum accounts?
- Embark on the Opside Value Exploration Journey: Pre-Alpha Incentive Test Network Countdown officially launched