Onion routing in the Lightning Network and how it works
How Onion Routing Works in the Lightning NetworkAuthor: LORENZO
A computer in a network communicates with others based on protocols. Here, “protocol” refers to a set of rule systems that specify how messages should be transmitted and interpreted. The payment message transmission part of the Lightning Network protocol is described by BOLT #4, also known as the “Onion Rounting Protocol”.
Onion routing is a technology that was born 25 years before the Lightning Network. It is also used in Tor, which is where the name “Tor” (The Onion Router) comes from. The Lightning Network uses a slightly modified version called “Source-routed Onion Routing”, abbreviated as “SPHINX”. In this article, we will describe how onion routing works.
Why use onion routing?
There are many different communication protocols in the world, but because the Lightning Network is a payment network, it is reasonable to choose a protocol that reveals as little information about the payment being forwarded as possible. If the Lightning Network were to use the same protocol as the Internet, every intermediary would know who the payment sender is, who the receiver is, and who the other intermediaries on the entire path are. Onion routing is a good choice because its characteristics ensure that the intermediate nodes:
- How to Participate in the zkSync Era Exploration Campaign?
- What Crypto applications are integrated into the Worldcoin App, which has 1.7 million users?
- Chainlink Engineer: How Oracles Connect Web2 and Web3
-
Only know their previous node (who sent them the message) and their next node (where to forward the message).
-
Do not know the length of the entire path.
-
Do not know their own position in the path.
Overview of onion routing
We will use the analogy of a package to explain how onion routing works. Suppose Alice wants to pay Dina. First, Alice needs to find a feasible path for her payment:
Alice → Bob → Chan → Dina
Then, she constructs an “onion”. She starts with Dina (at the end of the path). She puts a secret message (the payment content) in a package sent to Dina and locks it with a key known only to her and Dina. Now, she puts this package into another package that is ready to be sent to Chan and locks it with a key known only to her and Chan. And so on and so forth.
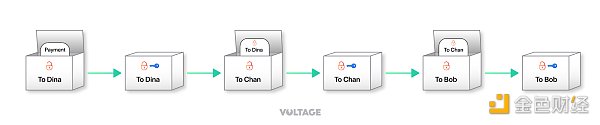
Alice sends the final onion (envelope) to the first middleman on the path, Bob. Bob uses his own key to unlock his envelope, and sees that the next one is to be sent to Chan. So he forwards the envelope to Chan. Chan does the same, and after unlocking the envelope, forwards the one inside it to Dina. Finally, Dina opens her own envelope and finds the payment message inside.
In onion routing, middlemen like Bob and Chan don’t know the contents of the information being sent to Dina, nor do they know the length of the payment path. The only thing they know is who forwarded the envelope to them and who the next recipient is. This ensures message privacy and path confidentiality. Each middleman can only touch the layer of messages specifically made for them.
In Lightning Network’s source-based onion routing, the sender selects the payment path and constructs a complete onion for that path. This can be seen as a privacy vulnerability (the receiver’s network location must be exposed to the sender). Other routing schemes, such as “blinded routing,” solve this problem by obscuring part of the payment path from the sender. However, in this article, we focus on SPHINX.
Assembling the Onion
Now, let’s look at the specification for onion routing. At the outset, we need to define these things:
-
The sender is the “origin node” (Alice);
-
The receiver is the “destination node” (Dina);
-
Each middle node on the payment path is a “hop” (Bob and Chan);
-
The communication information between each hop is called the “hop payload.”
Constructing the Hop Payload
Once Alice has selected a payment path, she obtains information about each payment channel from the gossip protocol in order to create the hop payload for each hop, essentially telling each hop how to create an HTLC (Hash Time-Locked Contract) for the payment being forwarded.
To establish an appropriate HTLC, each hop needs:
-
The amount to be forwarded;
-
The secret value for the payment;
-
The ID of the payment channel continuing to forward the onion;
-
The length of the time lock.
Most of this data comes from “channel updates” messages, which include information about routing fees, required events, and payment channel IDs. The total amount to be forwarded is the amount paid plus the sum of the fees charged by each subsequent hop, while the payment secret is calculated by Dina and embedded in the payment invoice (informed by the onion message every hop on the path).
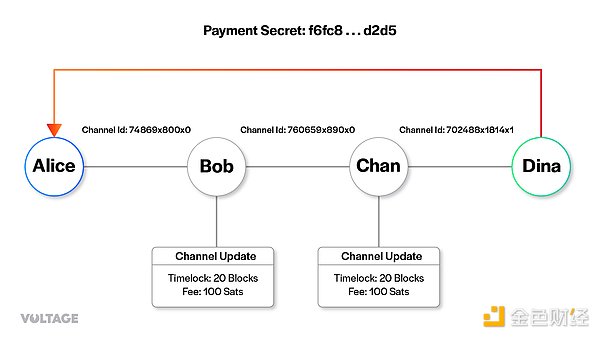

Alice starts from the final node Dina. She includes the forwarding amount, time lock duration value, payment secret value, and payment amount in the package. Note that she does not need to add the channel ID because Dina is the final node and does not need to forward the payment to anyone else.
At first glance, providing the forwarding amount is redundant because this amount is the same as the payment amount, but multi-path (multi-blockingth) payments will deliver the total payment amount through multiple paths, at which point the two values will be inconsistent.
In Chan’s payload, Alice adds the Chan to Dina’s channel ID. She also added the forwarding amount and time lock value. Finally, Alice creates a payload for Bob. Chan charges 100 satoshis for the payment through its own channel with Dina, so Alice needs to tell Bob that the forwarding amount is the payment amount plus the fee. According to Chan’s channel update message, the time lock value has also increased by 20 (in blocks). Finally, Alice also needs to consider Bob’s fees and time lock requirements and give him an HTLC with a time lock length of 700040 and a value of 100200 satoshis.
Shared Secret and Key Generation
Next, Alice prepares onions by generating a shared secret for each hop (including the final node). This shared secret can be generated by Alice and the destination hop by multiplying their own private keys by the other’s public key.
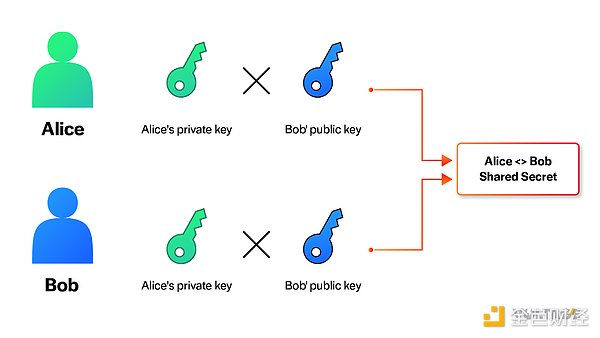
The shared secret is necessary for onion routing, allowing Alice and each hop to deduce the same key. Alice then uses these keys to obfuscate each layer of the onion, while the hop uses the key to unmask the obfuscation.
To protect Alice’s privacy, she creates a disposable session key for an onion instead of using her own node public key to deduce the shared secret. She uses this session key for the first hop and then deterministically randomizes the key by multiplying it by a blinding factor for each subsequent hop. These keys used to create shared secret keys are called “temporary keys”.

Bob, Chan, and Dina all need to obtain the same secret value from Alice, so they need to know the temporary key used in their own session. Alice only puts the first key in the onion to save message size. Each hop calculates the next temporary key and embeds it in the onion given to the next node. Each hop can use its own public key and shared secret value to calculate the blinding factor used by Alice to determine the next temporary key.
As mentioned earlier, the shared secret value is used to generate some keys that Alice and corresponding hops can use to perform some operations on the onion. Let’s take a look at the purpose of each key.
Rho key
Alice uses the Rho key to encrypt an onion layer; this confuses the content of the payload and prevents outsiders from reading it. Only the Rho key owner can decrypt the payload. This is what the node receiving the onion needs to do: use the shared secret value with Alice to derive the Rho key, then decrypt the onion and read the content.
Mu key
Alice uses the Mu key to create a checksum for each payload. She also hands the checksum to the next hop that receives the onion. In turn, this hop uses the Mu key to generate the checksum of the received payload and check if it matches the one provided by Alice. This is to check the integrity of the payload and verify that it has not been tampered with.
Blockingd key
This key is only used by Alice to generate random “garbage” data. This data is also part of the onion, and it is unrelated to the length of the payment path and how many hops the onion has passed through. It keeps the onion the same size, even if some of its content is irrelevant. This is how onion routing hides the length of the path, actually protecting the privacy of the sender and receiver.
Um key
This key is also used to check the integrity of the data contained in the onion, but only when an error is returned. Yes, it is called “um” because it is the reverse of “mu”. In the case of payment failure, the hop that discovers the error uses the Um key to create a checksum. When the previous node receives the error message, it also uses the Um key to verify the integrity of the message.
Encapsulating Onion Layers
Here is what the final onion packet looks like:
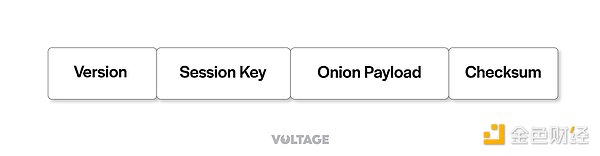
Now, Alice has the payload for each hop and the shared secret value for each hop. Let’s see how Alice turns this information into the final onion. She starts at the final node and works backwards step by step.
She starts by creating an empty field that is 1300 bytes long, which is the total length of all the onion payloads. Then, she uses the Blockingd key to create a random string that is 1300 bytes long, which is just garbage that is useless for any hop. This step is done to ensure that each layer of the onion looks the same, so you can’t tell how long the path is (how many hops there are) or who the sender or receiver is.
Then, she creates a checksum for the payload she needs to use and puts it at the end of the payload. In the message sent to the final node, all the checksums are 0 to tell Dina that she is the final recipient of this onion. After adding the checksum to the end of the payload, Alice puts the payload (and the checksum) at the beginning of the garbage and removes any part of the message that is over 1300 bytes to ensure that the entire message is exactly 1300 bytes long.
Then, Alice uses the rho key to create a random byte string and uses XOR operation on the onion payload obtained in the previous step to get the obfuscated payload. The plaintext of the payload can be obtained by XORing the random byte string used in this step with the obfuscated text (translator’s note: in other words, XOR here is a symmetric encryption algorithm, and the random byte string is the key). XOR operation compares each bit of the onion payload with the random byte string generated by rho key, and outputs 1 only when one of the data bits is 1; this produces an obfuscated payload. The clever part of XOR operation is that as long as you get the right random byte string and the obfuscated payload, you can use both to perform XOR operation again and get the original payload before obfuscation.
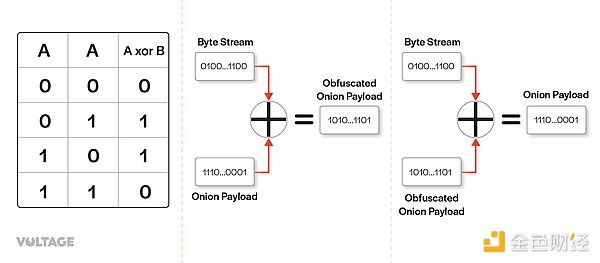
Because the node that receives the onion can deduce the same rho key, they can generate the same random byte string as Alice. This is how each node along the way can unravel the obfuscation and read the contents.
After preparing the onion routing, Alice repeats the same steps for the next node. The key difference is that after completing Dina’s onion, she no longer needs to generate garbage. She only needs to attach the obfuscated onion generated in the previous step after the useful payload and checksum, and then trim off the part exceeding 1300 bytes.
Finally, Alice gets the final obfuscated onion and adds a checksum so that Bob can verify the integrity of the onion. Then, she adds the session public key so that Bob can use this key to calculate the shared secret value. Finally, she adds a byte indicating the version, informing other nodes how to interpret the data. For the version described in BOLT#4, the version byte should be 0.

Forward Onion
To send this onion package, the sender creates an update_add_htlc message containing the following fields:
-
Channel ID: The specific channel related to this message.
-
ID: The identifier of this HTLC.
-
Amount: The value of this HTLC.
-
Payment Hash: Created by the payee.
-
Expiration Time: This HTLC will expire after a certain number of blocks.
-
Onion Package: The onion created for this payment, as mentioned above.
-
Extra Data: Used to specify additional data.
After preparing the message, Alice sends it to Bob. After receiving the message, Bob can start decoding his own onion. He first obtains the session key from the onion package and then uses it to derive the shared secret value with Alice.
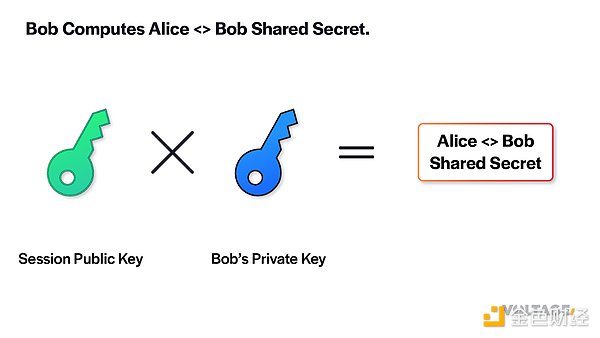
With the shared secret value, Bob generates the mu key to verify the checksum of the payload embedded in the onion package. If the payload has not been tampered with, the checksum should match.
To prevent other nodes in the path from knowing how long the path is, Bob adds a 1300-byte field filled with 0s in the onion package. Then, Bob generates a 2600-byte random byte string from the rho key. Bob uses this random byte string to perform an XOR operation on the onion payload filled with 0s.
Do you remember how I told you about onion routing? Using an obfuscated onion payload as input and performing an “XOR” operation with the same byte string yields the original onion payload. Bob can decode the obfuscation because he uses the same shared secret as Alice to generate the same rho key. An added benefit of this approach is that it turns the 1300-byte padding characters into random bytes.
Bob’s decoded payload includes his own hop data and a fingerprint. Bob saves this fingerprint to add it to the onion packet he sends to Chan. After Bob separates his own payload from the onion message, he converts the onion packet back to its original 1300-byte size and randomizes his session key like Alice. Finally, Bob adds the version byte, session key, and the fingerprint he prepared for the onion payload to forward the onion packet to Chan via an update_add_htlc message.
This process continues until the message reaches the final node, Dina. When Dina receives an update_add_htlc message, she can stash it in the hash value of the secret value she generated, which indicates the HTLC is intended for her. Therefore, Dina only needs to check the fingerprint, decode the onion message, and reveal her own payload.
Failure Recovery
We have described a success story, where everything goes according to plan, but if something goes wrong, a message must be sent back along the entire path to notify all nodes of the problem. This process is similar to conventional onion routing. The failure node needs to derive a um key from the shared secret value, generate a random byte string using it, and then obfuscate the returned onion packet using XOR.
The error node sends a message back to the previous node on the payment path. Each hop performs the same operation with um key and ammag key until the sender receives the packet. Finally, the sender decodes and verifies the obfuscation using ammag key and um key respectively.
Errors can be caused by onion packets, nodes, or channels. If you use the Lightning Network often, you may have encountered errors such as “Channel not available” or “Insufficient fee”.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- What is Schnorr Signature?
- Evening Reading | Why won’t there be a bull market for 23 years?
- Proposal from Synthetix Founder: Opportunities I’ve Discovered and Synthetix’s Next Plans
- Complete Guide to On-chain Wallet Tracking: Practical Tools and Wallet Trackers
- Interpretation of Hong Kong’s “Virtual Asset Consultation Conclusion”: Can mainland retail investors enter the market?
- Discussion on ZK Mining and ZKR Performance
- From ERC20, 721, 1155 to 3525: A detailed account of RWA’s journey towards Web3 mass adoption






