The only way for Web3.0 to land: the scalability and interoperability of blockchain
Source: Wanxiang Blockchain
Editor's note: The original title was "[Wangxiang Blockchain Hive College Issue 13] Jia Yaoqi: The Only Way to Web 3.0 Landing-Blockchain Scalability and Interoperability". This article has been deleted without changing the author's original intention.
This article is the 13th issue of Wanxiang Blockchain Hive Academy, Dr. Jia Yaoqi, technical director of Parity Asia, expert in blockchain and information security technology (organized from field shorthand). In his speech, Dr. Jia introduced the definition and application of Web 3.0, and shared the technologies and methods of implementing Web 3.0.

- 2020: Nonprofits fall in love with Bitcoin?
- Stolen up to $ 1.2 million, Foundation shuts down IOTA network
- Nearly 200,000 bitcoins, only "selling" 180 million, how can the US and Australia miss the big bull market of cryptocurrencies?
Hello everyone! My name is Yaoqi Jia, Director of Engineering at Parity Asia. I am mainly responsible for technical R & D and ecological development of Substrate developers. Today I will share with you two difficult but interesting topics in the blockchain, one is scalability, and the other is interoperability. Today's content is more technical. I will give some examples to help you understand the technical details.

Web 3.0 is currently a relatively popular concept. Many people who are engaged in the blockchain industry will also consider that applications developed by themselves are oriented towards Web 3.0. What exactly is Web 3.0? There are many different definitions of Web 3.0, one of which is adopted in the figure above. In the Web 1.0 era, web pages were read-only, and users could only collect and browse information. The Web2.0 era is the era of social networks, such as Facebook, Twitter, Renren, Sina, WeChat, and the latest fast hand, Douyin, and so on. As users, we can not only browse, but also create content ourselves and upload it online. Web3.0 is a step forward. In addition to publishing content, we can do more de-intermediation in the future. This has to mention some of the methods needed, including some ideas.
In the Web 2.0 era, data is controlled by big companies like Google, Facebook and Amazon. When you use their services, the agreement states that you can use your data without liability. Although Google's early slogan was don't do evil, sometimes it provided its data to third parties. In the era of Web 3.0, we don't need them to guarantee don't do evil, but to make them can't do evil through code.
In the Web 3.0 era, what technologies are needed to realize the vision? Blockchain is a foundation. Blockchain can provide features, one is immutable, the other is open and transparent, and the third is a peer-to-peer network.
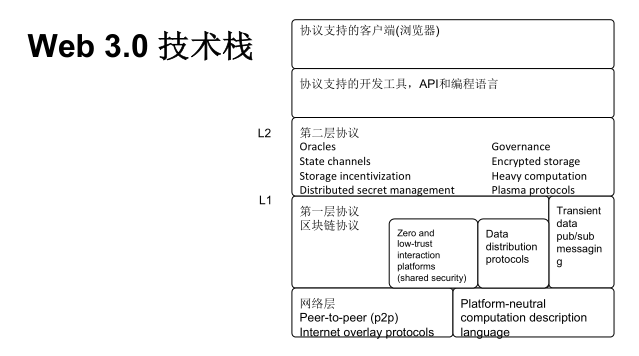
And then specific to some details such as the Web3.0 technology stack, can be divided into these simple layers, the uppermost layer is the client, such as a decentralized browser. Underneath this are some development tools supported by the protocol, corresponding APIs and specific programming languages. Facebook's Libra has its own programming language, Move, and Ethereum has its own programming language, Solidity. The next layer is the Layer 2 protocol, such as Government, State channels, etc. A blockchain application cannot arbitrarily obtain information on the Internet. For example, if you want to watch the weather forecast, the blockchain cannot directly provide such data. Here we need the oracle protocol in the Layer 2 protocol stack to obtain the Internet through the oracle mechanism of the protocol itself The information on it is placed on the blockchain. The Layer1 protocol is a well-known underlying protocol of the blockchain. Bitcoin, Ethereum, and other various public chains. The alliance chain uses a similar underlying protocol, which provides the foundation to support the entire Web3.0 vision. Further down is the network layer, such as P2P network transmission.
With such a technology stack, the road to web 3.0 becomes more realistic. Among the many Layer1 protocols, Polkadot's cross-chain protocols have many advantages, such as shared security and interoperability. Polkadot itself was developed based on Parity's open source Substrate. Substrate, as a general blockchain development framework, can be used to develop the Layer1 protocol such as cross-chain operations, or to implement the Layer2 protocol such as the oracle.
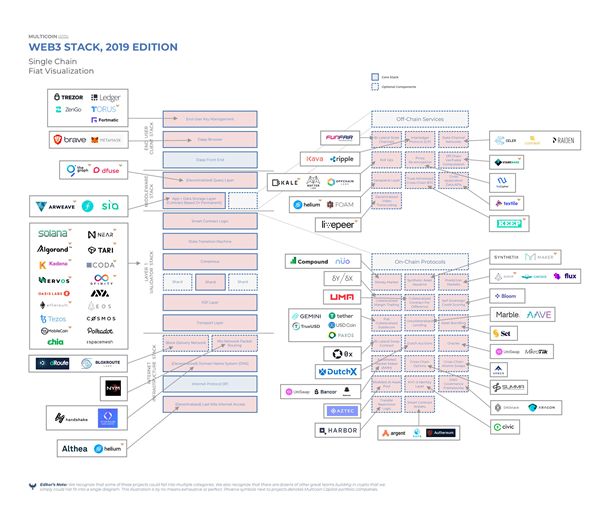
What are the early applications based on the technology stack described above? The figure above lists some typical Web 3.0 applications. In addition to the public chain system that everyone is familiar with, there are also some network protocol layer projects, which are more in the application layer, such as decentralized financial services such as lending. But is there a real mainstream application for users in the non-blockchain field? Actually not. What is causing the lack of mainstream applications? Here are a few examples to explain.
Case one, an ethereal monster. This is a game application that was particularly popular on Ethereum a year or two ago. The method is the same as the electronic monster. You buy such a monster to fight other monsters, and you can upgrade if you win. The game was very hot in the early days, but later it was found that the game was too expensive. If you raise a little monster to the fourth level, it will cost him 15 dollars in transaction fees, and always support him to fight monsters or train.
Case two, an ether cat. One or two years ago, it was very popular. You can buy all kinds of encryption cats. Two encryption cats can generate a new encryption cat. At the hottest point, some crypto cats were worth $ 100,000. But there are problems. The more people play, the higher the fee increases, because Ethereum has only so much throughput. If you want to play, you need to buy such a crypto cat with a higher fee, and the birth fee will increase accordingly. Now the crypto cat application has faded out of sight.
One conclusion that is summed up is that, for the blockchain industry, due to the high processing fees brought by low throughput, it has brought many functional restrictions to the development of DApps.
Scalability
Both academics and industry are committed to solving the problem of low throughput of the blockchain. One way is to increase the block size. If you increase the block size, there will be an improvement in throughput. But due to bandwidth limitations, this is not an efficient (100x) solution to increase throughput.
Option two, through off-chain transactions. All transactions are processed off-chain, and the settlement part is on-chain. Because you can use a centralized server to process transactions, you can easily achieve tens of thousands of transactions per second. In this way, throughput can be effectively improved. But there are disadvantages, because not all transactions are completed on the chain, so will the centralized server itself cheat? Transparency is a problem.
In the third solution, we no longer use a chained data structure, but a graph structure. Different nodes can produce different blocks for broadcasting. When a node wants to pack blocks, it can build a directed acyclic graph based on past blocks, and then package and distribute to other nodes. The benefit is that you can include multiple transactions while increasing throughput. There may be many transactions in the graph structure that are in conflict, and there are differences on the smart contracts to be executed eventually. This is the problem encountered by the graph structure.
Option 4, the agent mechanism. The fewer nodes participating in the consensus protocol, the faster it runs and the higher the throughput. Only a small number of super nodes can participate in the consensus protocol to achieve a high throughput, but it is easy to be criticized whether a small number of proxy nodes can represent the entire community. If there are fewer nodes, these nodes do not like certain transactions or certain applications, but can actually reject transactions submitted by this application. This goes back to the disadvantages of centralization.
Also, it is fragmentation and multi-chain. This solution represents a trend that can achieve better throughput without losing a lot of decentralization characteristics. Everyone sees the latest Ethereum 2.0 and new sharding projects, as well as some cross-chain projects. You will find that the difference between these has become very blurred. Many times you can think of a shard as a homogeneous chain. The atomic protocol mentioned in the multi-chain cross-chain transaction and the atomic protocol mentioned in the fragmentation protocol are not much different, and some adopt the same technology. Just the multi-chain technology and sharding technology, sometimes there will be a relay chain or relay shard to coordinate different shards or different chains. But in the final analysis, the technology itself has many similarities, and they are unified here to explain.
Sharding is to divide and conquer transactions, thereby increasing throughput. For example, there are a thousand questions and a hundred people solve them at the same time. Now you can divide into groups, one hundred people are divided into ten groups, and one thousand questions are divided into ten groups. Ten people in each group handle one hundred questions, and a consensus is formed based on the answers of the vast majority of people, then we can actually guarantee Each group correctly solved one hundred problems, so that the overall solution time was reduced from one thousand to one hundred. If there are more listeners in the future, for example, one thousand, we can divide one thousand people into one hundred groups, one hundred groups solve one thousand problems, one group only solves ten problems, and eventually only ten questions Time has solved a thousand problems. However, there may be some attack situations. If there are ten attackers, they conspired to divide into the first group, and did not follow some principles when reaching consensus, such as scoring a penny into 10,000 yuan for a double-spend attack. . If an attacker can control a shard, the attack generated in some protocols cannot be prevented by other shards.
How to avoid such attacks?
First, a high threshold must be established to prevent attackers from easily joining the network and prevent witch attacks. One method is proof of work, which requires a specific miner to do enough calculations to submit a block as a node. The second method is proof of equity.
Once there are a hundred listeners (or nodes), random grouping can ensure that the listeners are divided into different groups. What kind of random number do we need to group? One method is to use the result of the previous proof of work as a random number to divide everyone into different groups. Another method, in the proof of stake, uses a random number generation protocol (such as VRF) to let everyone divide into different shards.
If there are already reasonable groupings, and each group can guarantee that the normal nodes account for the vast majority, then how to divide the thousand problems mentioned above into different groups. In order to ensure data consistency and validity of different shards or the entire system, we need a method to prevent the same transaction from being processed multiple times by different shards or the same data being changed multiple times. A common solution is to use two-phase commit protocols to ensure data consistency.
I just mentioned network sharding. Nodes can be safely divided into different shards or chains. Later transactions can also be divided into different shards and then processed for transactions, while ensuring the validity and consistency of data. If you do state sharding, such as ETH2.0, each shard has its own data storage, and different shards store different data, so there is a risk of data loss of a single shard.
The more intuitive solution is to encourage nodes to stay online for a long time through some equity rewards, and to do a lot of transaction verification and consensus protocols to ensure that they will not be punished. If it goes offline for a long time, it will be removed from the shard, and the mortgaged interest will be taken away by the system. When we have a robust sharding system, then we can integrate the throughput of multiple shards or chains, thereby greatly improving the throughput of the entire system.
With the sharding and multi-chain methods, what do we think more about are the methods for a single chain to further increase its throughput? A faster solution is to change the consensus protocol. Currently Bitcoin or Ethereum uses the Satoshi consensus protocol. Nodes pass the proof of work and generate a block every time and broadcast the block to other nodes. When other nodes see this block, they choose to own it. The longest chain of blocks to confirm. The advantages of Satoshi consensus protocol are decentralization and asynchronous. Even if there are tens of thousands of nodes in the network, and there are different network delays, the Satoshi consensus protocol can still reach a consensus on the entire network. Of course the disadvantage is that the throughput is too low.
The Byzantine Consensus Agreement (BFT) is a consensus protocol commonly used in academia and industry. To put it simply, for example, now that I am going to buy a ticket, I want to ensure that the vast majority of the one hundred people at the scene know that I want to buy a ticket, and everyone agrees that I will buy a ticket. My approach is to broadcast the message to everyone that I am going to buy a ticket. After others received such a message, they agreed to the message, and then broadcast the message. When everyone receives the confirmation information from 2/3 nodes, they broadcast a confirmation message that they have received confirmation from most people. After everyone received the final confirmation information of 2/3 nodes, it was confirmed that the entire network has agreed and confirmed the purchase of the ticket.
The advantage of the Byzantine consensus protocol is that it is fast. If you implement such a BFT control protocol, it is easy to reach more than 1000TPS, and it has absolute finality. Once the agreement is completed, the transaction can immediately confirm the finality.
The disadvantage is that the traditional Byzantine consensus protocol can only be used for less than a hundred nodes, more than a hundred nodes, and the amount of information exchange is too large to allow network congestion to improve throughput. At the same time, it is not completely asynchronous. Each stage has a waiting time, for example, you can wait ten seconds in the middle, and if not, proceed to the next stage. If the long-term agreement does not move forward, a view change is performed and the switch commander re-runs the agreement.
Polkadot integrates and improves the Satoshi consensus agreement and the Byzantine consensus agreement. It uses a hybrid algorithm, GRANDPA protocol and BABE protocol. The BABE protocol is responsible for block generation, and the GRANDPA protocol is final. The BABE protocol is the same as the traditional Bitcoin and Ethereum protocols. Every few seconds, a node is selected for block generation. After the node has generated a block, a broadcast is performed. After a few seconds, a second node is selected for a block generation. Different nodes also select blocks for confirmation based on the longest chain principle.
GRANDPA algorithm, which is an improved version based on BFT, is a non-asynchronous consensus protocol. The block generated by the BABE protocol will be finalized by the GRANDPA protocol. The BABE protocol generates chains of different lengths. The GRANDPA protocol will choose the valid chain that contains the most votes for confirmation. In the previous blockchain, if a consensus protocol was performed, it was usually finalized block by block, but Polkadot was finalized according to different chains. For example, after a period of time, ten blocks or twenty blocks are generated, then the GRANDPA protocol is run to directly confirm the twenty blocks at one time. In this way, GRANDPA can confirm more blocks in a limited time.
Through the above explanation, we can see that we want a high-throughput blockchain solution and have good decentralization characteristics. The best way is to choose a high-throughput single-chain solution plus a safe and efficient analysis. Chip or cross-chain solution.
Interoperability
In addition to the perspective of scalability, we also need to think from a practical perspective, why we need interoperability, or why we need cross-chain. Traditionally, blockchain can solve the problem of trust. If scalability can be solved, then the problem of performance will also be solved. Interoperability can actually solve the broader problem of trust when the above two issues are resolved.
At present, different application scenarios have different alliance chains and public chains. With these chains in place, we need to use interoperability to communicate useful data. This will involve different approaches to cross-chain or interoperability. In the future, we will see a blockchain system with extremely blurred boundaries, that is, private chains, alliance chains, and public chains are interconnected in some way.
The interoperability in the blockchain field, why is it not explicitly mentioned in traditional Internet applications? Because the Internet infrastructure now provides these functions, such as various SDKs and APIs. If you make an application and want to call the data on WeChat, then you can get the data down through the SDK and interface on WeChat. If you want to make a payment, Alipay also has a corresponding payment channel. When you write the code, you can call the API to make the payment. At present, the reason why it cannot be done on the blockchain is that our data is still in an isolated state due to the different consensus and block structures of various blockchains. In order for the data on different islands to communicate, we must connect different blockchains through interoperability and cross-chain systems.
What are the specific ways of interoperability and cross-chain protocols? The first way is the notary model. There is a notary between different chains. The second way to relatively decentralize is the side chain pattern. Through the side chain method, on the chain B, it can be verified which transactions on the chain A are written into the block, then the chain B can verify the operations on A and perform corresponding operations on B such as transfer. The third method is hash time lock. This is a relatively complex protocol. It is a cross-chain operation that integrates decentralized and transparent transaction assets conversion. To put it simply, if I trade bitcoin for Ethereum, I put a lock on Bitcoin, and at the same time, the other party also puts a lock on Ethereum. I give him the key, and I can get the corresponding Ethereum with the same key, and at the same time he can get the corresponding Bitcoin based on the key. There is also a time lock, which guarantees that both parties can only unlock Ethereum and Bitcoin within a limited time, otherwise the agreement will automatically terminate and neither party will obtain the assets of the other.
The methods just mentioned are all good cross-chain solutions for digital assets, both in terms of efficiency and decentralization. If we want to achieve cross-chain data and logic, we need more complex systems, such as the relay chain in a multi-chain system. Specifically on Polkadot, the system uses relay chains to coordinate cross-chain operations of different parallel chains. According to different business environments, developers can use Substrate to develop and build different parachains. The verification node of the relay chain is used to verify the correctness of the parallel chain block to ensure that each parallel chain has the same security, and at the same time coordinate the communication between different parallel chains. Some existing blockchains, such as Ethereum and Bitcoin, currently do not have a parallel version based on Substrate. The current method is to use bridges, bridge them into parallel chains, and then communicate with other chains through relay chains.
In such a frame structure, the most central is the relay chain, which connects different parallel chains. Just mentioned the bridge chain, the bridge chain is not directly connected to the relay chain, but through a bridge, first connected to the parallel chain, and then communicate with other chains through the relay chain.
Each parachain has light nodes in the relay chain that are used to receive and verify messages from the relay chain. At the same time, the parallel chain has its own proofreading node called collator. The proofreading node collects the data on the corresponding parallel chain and passes these data to the relay chain. The relay chain will assign different verification nodes to verify whether the blocks on the parallel chain are correct and whether there are double-spend attacks. If some blocks have problems, the relay chain will confiscate the corresponding parallel chain slots according to the protocol. Or punish some nodes.
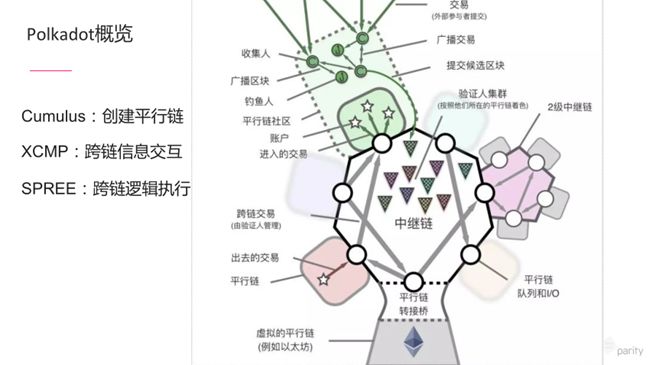
The above picture is from the white paper of Polkadot, which includes different roles, including different parachains and how they work in parallel chains, such as processing transactions, broadcasting transactions, and final transactions as blocks. Wait inside the relay chain.
If the relay chain wants to support tens of thousands of parallel chains, how can we achieve higher horizontal expansion? The method is to use the secondary relay chain as a parallel link into the relay chain to build a more decentralized cross-chain platform connecting the relay chain.
Parity is currently developing three vital features. The first is Cumulus. The parachain needs a connector to connect to the relay chain. This connector is Cumulus. The code developed with Substrate now requires only a few changes in the future, and you can use Cumulus to connect to the relay chain, provided you get the corresponding socket.
The second is the XCMP cross-chain information exchange protocol. If different parachains want to call or send messages to other parachains, they need to transmit through such a protocol.
The third is SPREE. When it comes to cross-chain, everyone usually defaults to asset cross-chain, and asset A is placed on chain B, and a little can be done to make it decentralized. What's even better is that the different chains mentioned now can send information through the relay chain or other methods, and the other chain can execute the corresponding transaction or smart contract. But the premise is that different parachains are relatively homomorphic architectures. Isomorphism is that the logic of processing transactions by different parallel chains is roughly the same. Chain A uses EVM to process smart contracts, and Chain B also uses EVM to process transactions. Then Chain A sends transactions to Chain B, and Chain B can process. If chain A is EVM and chain B is WASM, then chain B does not know how to handle transactions received by A. SPREE can support the interaction of cross-chain execution code. That is, chain A packages its own execution logic. After packaging, it generates an executable runtime and sends it to chain B through some channels. After receiving it, chain B can execute the transactions of chain A. Even if the chain A and B process transactions differently, because B receives the code and data of A, then B can process the transaction on A. These three functions are under intense development. With these three protocols in place, we perform any cross-chain transactions and data processing operations.
In the past two years, Substrate has more than 200,000 lines of code and many community contributors. In the first quarter, Substrate will be upgraded from 1.0 to 2.0, which will have better performance and more stable components. At the same time, more than 80 teams have developed based on Substrate / Polkadot. Everyone is welcome to build interesting alliance chains and parachains on Substrate / Polkadot.
That's it for today's sharing, thank you!
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Monthly Data Report | The plan for the year lies in the spring, and the plan for reducing production lies in the stockpile
- Ronaldo is followed by Messi, FC Barcelona will issue fan tokens
- Beware of the "sequelae" of anti-epidemic, can blockchain protect personal privacy data?
- Comment: IRS doesn't consider Bitcoin as a virtual currency at all
- Bobby Lee: Bitcoin will eventually reach $ 1 million
- Hardcore | 2040: A World Without Bitcoin
- Crypto company BlockFi secures $ 30 million in funding, Silicon Valley legend Peter Thiel's venture capital agency leads again