Want to do a good job of blockchain data analysis? First look at how to solve the big problem of "deanonymization"
Author | Brain in a New Tank
Editor | Carol
In recent conference speeches I often get asked: What is the biggest challenge of blockchain data analysis? My answer is just one word: deanonymization.
I firmly believe that identifying different types of participants and understanding their behavior is a core challenge to unlock the potential of blockchain analysis. We have spent considerable time thinking about this issue to identify the right boundaries that do not conflict with the ethics of the digital currency movement. In this article, I want to explore this idea further.
- What happened to the netizen who "lost" 4 bitcoins on the Lightning Network?
- U.S. lawmakers seek to classify stable currencies like Libra as securities
- Introduction to Blockchain | Advanced Understanding of Smart Contracts-Implementation
The architecture of most blockchains in the market relies on anonymous or pseudo-anonymous mechanisms to protect the privacy of their nodes and achieve decentralization. The data obfuscation mechanism can record encrypted asset transaction data on a public ledger for everyone to access, but it also makes it extremely difficult to analyze this data.
Without identifying the participants, it is difficult to understand the blockchain data set and analyze meaningful results, and blockchain analysis can only linger at the initial stage. However, it is important to understand that deanonymizing the blockchain data set is not to know the true identity of each address in the ledger. This direction is basically not scalable.
Instead, we can identify and understand the behavior of known participants in the blockchain, such as exchanges, OTC counters, miners, and other core members that make up the blockchain ecosystem.
The number of addresses will unknowingly mislead you
Network metrics are an ubiquitous indicator in blockchain analysis, and an indicator that clearly demonstrates the power of deanonymization .
The number of addresses is the most common misleading indicator because not all addresses are equally important. The address created by the transaction for temporary transfers obviously cannot be compared with another wallet address that holds assets for a long time.
Similarly, the hot wallets of exchanges like Binance are definitely different from my personal wallet using the same methods and indicators for analysis. Treating the anonymity of all addresses equally is bound to lead to limited interpretation and often leads to misleading conclusions.
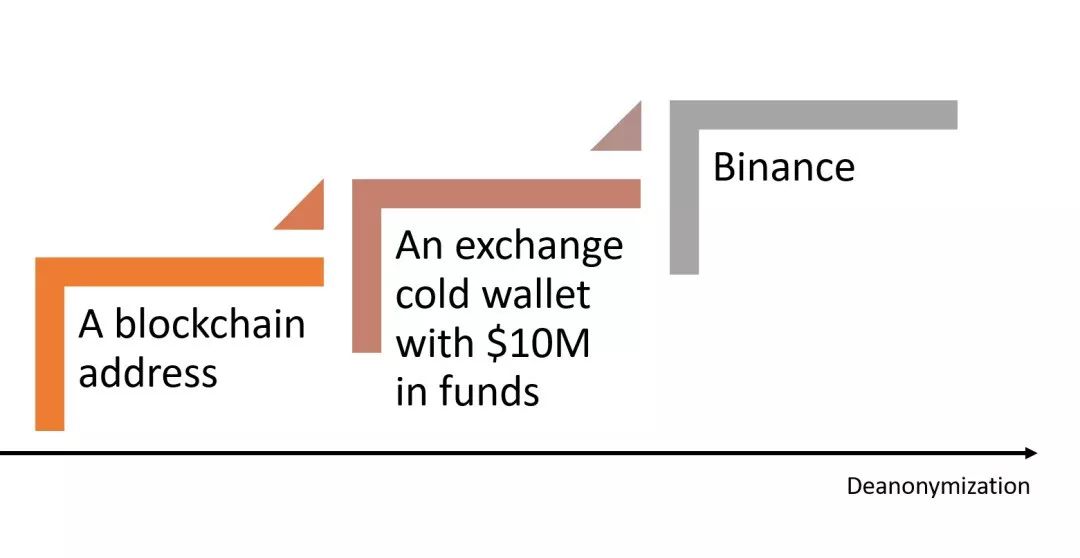
Anonymity vs. Interpretability
Anonymous or pseudo-anonymous identities are one of the key factors of a scalable decentralized architecture, but this also makes it extremely difficult to obtain valuable information from blockchain data sets. One way to understand this is to consider anonymity as a counter-factor to the interpretability of blockchain analysis.
The friction between anonymity and interpretability in blockchain data sets is relatively small. The higher the anonymity of a blockchain data set, the more difficult it is to obtain meaningful information from it. Participants' identities provide the context in which they act, and context is a key building block of interpretability.
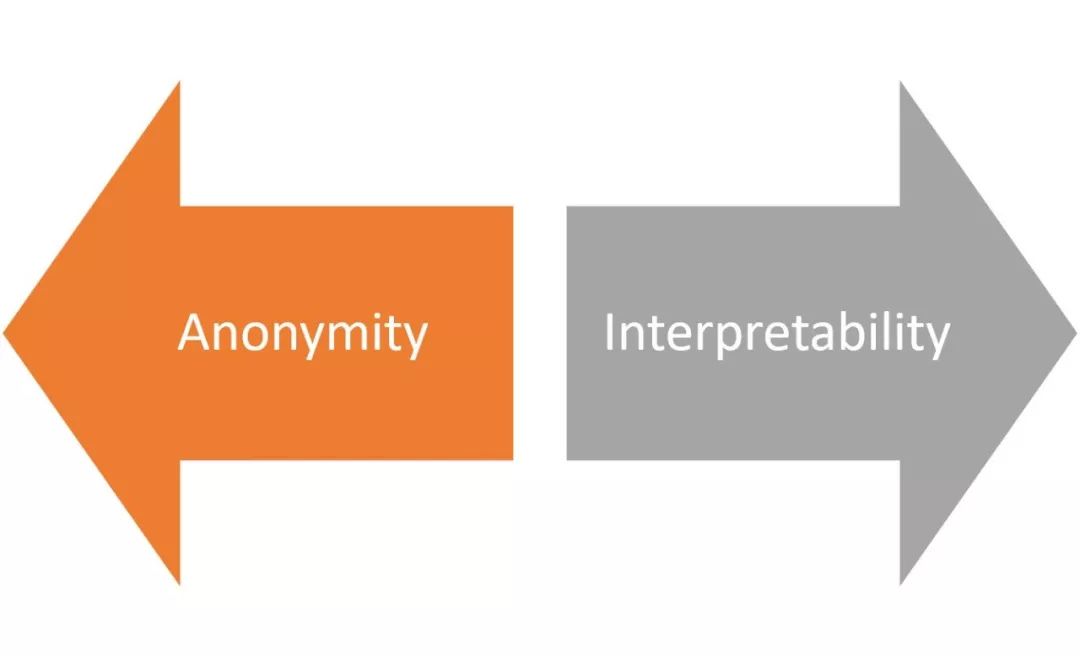
Deanonymization vs. Tagging
"What are you" is more important than "who are you?"
Deanonymizing the blockchain dataset does not involve knowing the true identity of each participant. Trying to understand the true identity of each user is not only a significant task, but it also makes it difficult for analytics to break through a certain scale.
Instead, we can try to understand the key characteristics of a participant to make our analysis to a certain degree of interpretability. Therefore, instead of clearly identifying the real identity of each address, we can tag the address or attach some descriptive metadata to make its behavior in a certain context.
In large-scale data, labeling is often more effective than individual identification. Understanding the behavior of specific individuals in the blockchain ecosystem will of course allow the analysis to reach a more personalized level, but the tendency to understand behavior at a macro level is relatively limited.
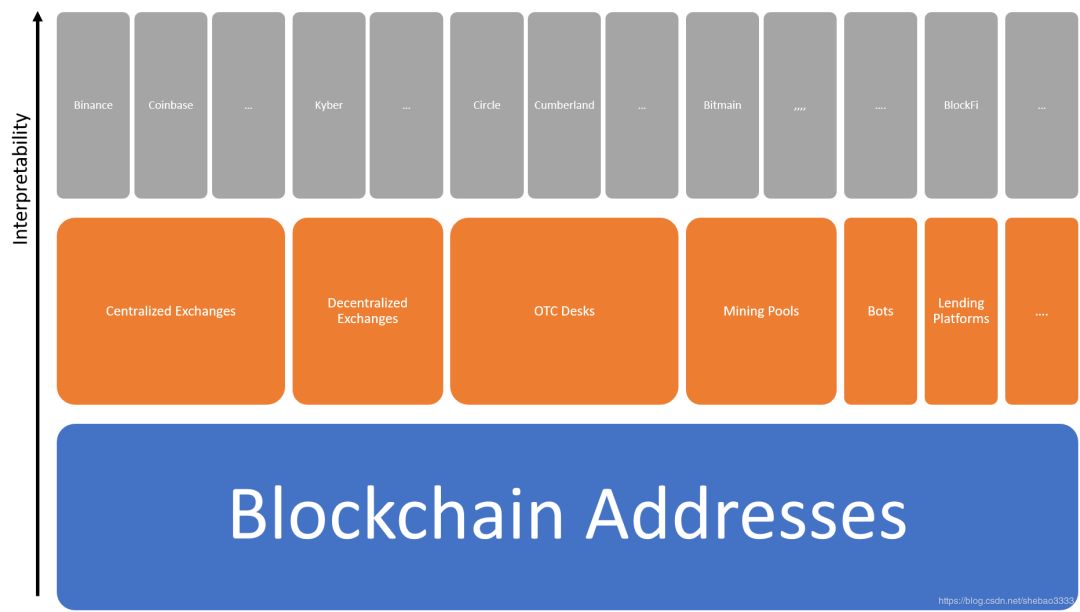
Therefore, compared with the identification of the individual's real identity of the blockchain address, the challenge of de-anonymity is more related to the labeling of key attributes of the address. How can we achieve this?
Machine learning would be an excellent solution
The idea of labeling or deanonymizing the blockchain can allow blockchain analysis to better understand the behavior patterns and characteristics of known participants in the ecosystem. Intuitively we can consider creating some rules to analyze different members in the blockchain ecosystem, such as:
"If an address holds a large number of Bitcoin addresses and executes 100 transactions at a time, then this is an exchange address …"
Although attractive, rule-based methods will quickly fail and no longer provide useful information. Some reasons are listed below:
- Prerequisite knowledge integrity : Rule-based classification assumes that we have sufficient knowledge about how to identify different participants in the blockchain ecosystem. This is obviously an incorrect assumption.
- Continuous change : The architecture of blockchain solutions is constantly evolving, which is a challenge for any embedded rules.
- Number of feature attributes : It is easy to create a rule with two or three parameters, but it is not so simple to try to create a rule with dozens or even hundreds of parameters. There are a lot of features to identify an address like an exchange or OTC counter.
Therefore, we cannot use preset rules. We need a mechanism that can learn patterns from the blockchain data set to automatically infer meaningful rules so that we can label relevant participants. Conceptually, this is a classic machine learning problem.
From a machine learning perspective, we should consider addressing the challenge of deanonymization in two main ways:
- Unsupervised learning : Unsupervised learning focuses on learning patterns that exist in a given data set and identifying related groups. In the context of a blockchain dataset, an unsupervised learning model can be used to match address-based features into different groups and label these groups.
- Supervised learning : Supervised learning methods can use existing knowledge to learn new features in a given data set. In the context of the blockchain, supervised learning methods can be used to train a model based on an existing exchange address data set to identify new exchange addresses.
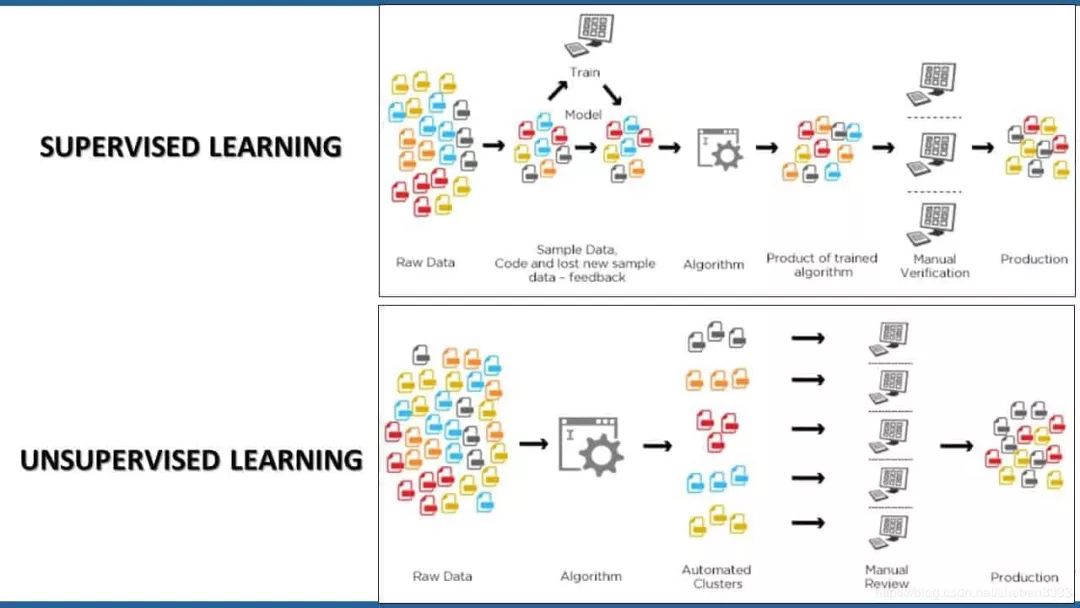
Deanonymization or labeling of blockchain data sets rarely uses supervised learning or only unsupervised learning. In most cases, a combination of the two methods is required. Machine learning models can effectively learn the characteristics of specific participants in the blockchain ecosystem and use these characteristics to understand their behavior.
After using the blockchain ETL tool to load the original blockchain data into a database or big data analysis platform, introducing the annotation layer into the blockchain dataset is a key challenge for more valuable blockchain data analysis.
These tags provide a better context and make the blockchain analysis model more readable. But even though we have the opportunity to learn such a powerful tool, deanonymity is still a major roadblock that cannot be ignored in the analysis and understanding of the blockchain ecosystem.
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Interview 丨 Chain Node CEO Qu Zhaoxiang: To make the blockchain popular, it should be made a trend symbol
- Every year, more than 700,000 people die from taking fake medicines in the world. How can blockchain change the rules of the medical field?
- 1/3 of the blockchain application is contracted by this trillion market
- Ethereum 2.0 is about to start the transition, these issues are worth paying attention to
- Ethereum will be upgraded this Saturday, and developers have agreed to delay the launch of the difficulty bomb
- Computing Power is King: Global Treasure Map
- Popular Science | Crypto War, Blockchain Technology