How can Google’s StyleDrop compete with the AI drawing tool Midjourney?
Can Google's StyleDrop compete with Midjourney's AI drawing tool?Author: New Wisdom
Google StyleDrop has become an instant sensation online.
By using Van Gogh’s Starry Night as reference, the AI transforms itself into the master and creates numerous paintings in a similar style.

- LD Capital: Analysis on Customized DEX Mechanism for L2 Top-tier Liquidity
- Deciphering the new regulations from the Monetary Authority of Singapore: Will cryptocurrency firms face stricter supervision?
- Is this the darkest moment for the NFT leader? Multidimensional interpretation of Yuga Labs’ performance in May
It can even accurately handle details and design original-style logos.

The charm of StyleDrop lies in its ability to deconstruct and replicate any complex art style with just one image as a reference.
Netizens have expressed that this is another AI tool that eliminates designers.

StyleDrop’s popularity comes from being the latest product from Google’s research team.

Paper link: https://arxiv.org/pdf/2306.00983.pdf
Now, with tools like StyleDrop, not only can one paint more controllably, but also complete fine work that was previously unimaginable, such as designing logos.
Even NVIDIA scientists call it a “phenomenal” achievement.

“Custom” master
The authors of the paper state that StyleDrop’s inspiration comes from an eyedropper tool.
Similarly, StyleDrop hopes that people can quickly and effortlessly “pick” styles from a single/few reference images to generate images of that style.

A sloth can have 18 styles:

A panda can have 24 styles:

A watercolor painting by a child is perfectly controlled by StyleDrop, even the wrinkles of the paper are restored.
It’s too powerful.

StyleDrop also refers to the design of English letters in different styles:

The letters of the Van Gogh style are the same.

There are also line drawings. Line drawings are highly abstracted images, and the requirements for the generation of reasonable composition in the picture are very high. The past methods have been difficult to succeed.

The brushstrokes of the cheese shadow in the original picture are restored to each object of each picture.

Reference Android logo creation.

In addition, researchers have expanded the capabilities of StyleDrop. It can not only customize styles, but also customize content in combination with DreamBooth.
For example, in the style of Van Gogh, a painting similar to that style is generated for a small Corgi:
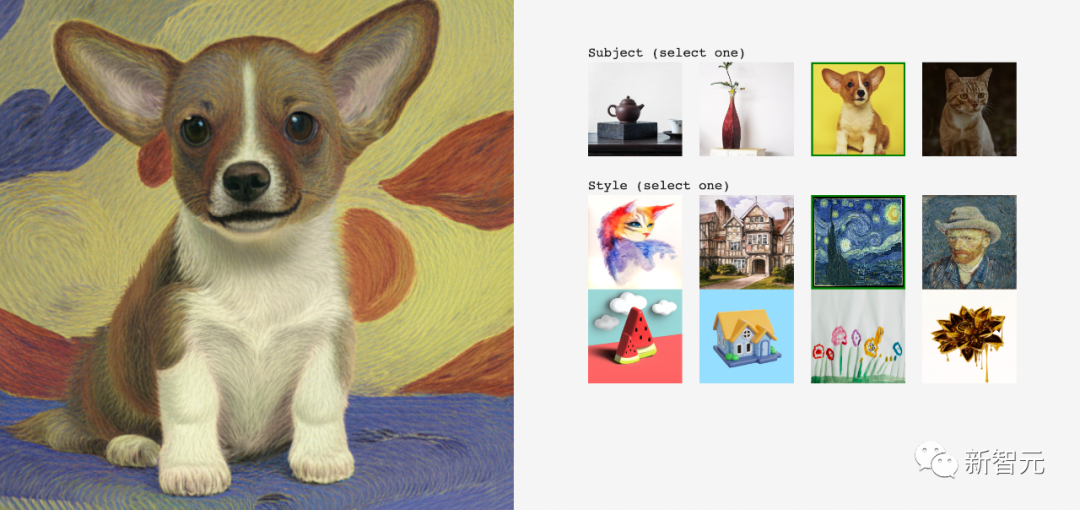
Here’s another one. This Corgi below feels like the “lion-headed figure on the pyramid” in Egypt.

How does it work?
StyleDrop is built on Muse and consists of two key parts:
one is parameter-efficient fine-tuning of the visual transformer, and the other is feedback-empowered iterative training.
Researchers then synthesize images from the two fine-tuned models.
Muse is a state-of-the-art text-to-image synthesis model based on a masked generative image transformer. It contains two compositional modules for base image synthesis (256×256) and super-resolution (512×512 or 1024×1024).

Each module consists of a text encoder T, a transformer G, a sampler S, an image encoder E, and a decoder D.
T maps text prompts t∈T to continuous embedding space E. G processes text embedding e∈E to generate log-likelihoods l∈L for a visual token sequence. S iteratively decodes visual token sequences v∈V from the logits, running transformer inference for several steps conditioned on the text embedding e and the visual tokens decoded from previous steps.
Finally, D maps the discrete token sequence to pixel space I. Overall, given a text prompt t, the image I is synthesized as follows:
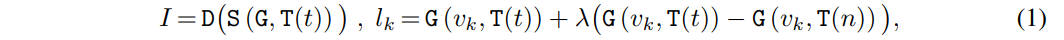
Figure 2 is a simplified architecture of the Muse transformer layer, modified in part to support parameter-efficient fine-tuning (PEFT) and adapters.
The transformer with L layers processes the visual token sequence shown in green under the condition of the text embedding e. The learned parameters θ are used to construct adapter weights for fine-tuning.

To train θ, in many cases, researchers may only be given an image as a style reference.
Researchers need to manually attach text prompts. They propose a simple, templated method to construct text prompts, consisting of a description of the content followed by a phrase describing the style.
For example, researchers describe an object as “cat” in Table 1 and add “watercolor” as a style description. Including content and style descriptions in text prompts is crucial because it helps to separate content from style, which is the main goal of the researchers.
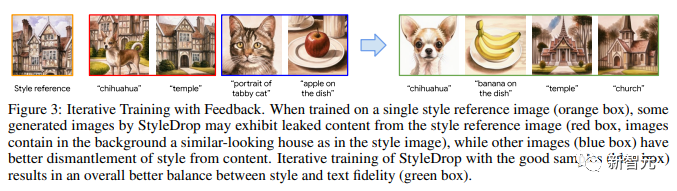
Figure 3 shows iterative training with feedback. When training on a single style reference image (orange box), some of the images generated by StyleDrop may show content extracted from the style reference image (red box, with a house in the background similar to the style image). Other images (blue box) better separate style from content. Iterative training of StyleDrop on good samples (blue box) resulted in better balance between style and textual fidelity (green box).
Researchers also used two methods here:
-CLIP Score
This method is used to measure the alignment between images and text. Hence, it can evaluate the quality of the generated images by measuring the CLIP score (i.e., the cosine similarity between visual and textual CLIP embeddings). Researchers can choose the highest scoring CLIP image. They call this method CLIP feedback iterative training (CF).
In experiments, researchers found that using CLIP scores to evaluate the quality of synthesized images is an effective way to improve recall (i.e., textual fidelity) without sacrificing style fidelity too much. However, on the other hand, CLIP scores may not fully align with human intentions and cannot capture subtle style attributes.
-HF
Human feedback (HF) is a more direct way of injecting user intent into the evaluation of synthesized image quality. In the reinforcement learning of LLM fine-tuning, HF has proven its strength and effectiveness. HF can be used to compensate for the problem that CLIP scores cannot capture subtle style attributes. Currently, a lot of research has focused on the personalization of text-to-image diffusion models to synthesize images with multiple personal styles.

Researchers demonstrated how DreamBooth and StyleDrop can be combined in a simple way to achieve personalized style and content. This was accomplished by sampling from two modified generative distributions guided by the style parameter θs and content parameter θc, which were separately trained on style and content reference images, respectively. Unlike existing approaches, the team’s method does not require joint training of learnable parameters across multiple concepts, which brings greater combinatorial power as the pre-trained adapters are trained separately on individual themes and styles. The researchers’ overall sampling process follows iterative decoding of Equation (1), with the way logarithmic sampling is performed differing at each decoding step. Let t be the text prompt and c be the text prompt with no style descriptors. The logarithms are calculated at step k as follows:
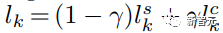
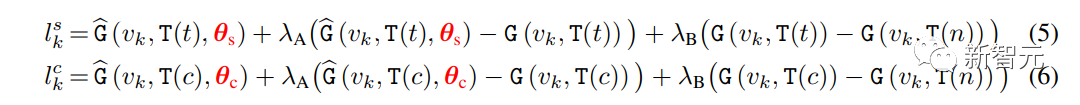
where γ is used to balance StyleDrop and DreamBooth – if γ is 0, we get StyleDrop, and if it’s 1, we get DreamBooth. By setting γ appropriately, we can get the desired image.
Experimental Setup
So far, there has been limited research on style adaptation of text-to-image generation models. Therefore, the researchers proposed a novel experimental setup:
-Data collection
The researchers collected dozens of images with different styles, ranging from watercolor and oil paintings, flat illustrations, 3D rendering to sculptures of different materials.
-Model configuration
The researchers fine-tuned Muse-based StyleDrop using adapters. For all experiments, the adapter weights were updated with the Adam optimizer for 1000 steps with a learning rate of 0.00003. Unless otherwise specified, the researchers used StyleDrop to denote the second round model, which was trained on more than 10 synthetic images with human feedback.
-Evaluation
The quantitative evaluation in the research report was based on CLIP, measuring style consistency and text alignment. In addition, the researchers conducted a user preference study to evaluate style consistency and text alignment.
As shown in the figure, the results of StyleDrop processing 18 different styled images collected by researchers can be seen. StyleDrop is able to capture subtle differences in texture, shadow, and structure of various styles, allowing for better control of style than before.
For comparison, researchers also introduced the results of DreamBooth on Imagen, LoRA implementation on Stable Diffusion, and text inversion. The specific results are shown in the table, which is the evaluation index of human scores (upper) and CLIP scores (lower) for image-text alignment (Text) and visual style alignment (Style).
Here, researchers applied two indicators of CLIP scores mentioned above-text and style scores. For the text score, researchers measured the cosine similarity between the image and text embeddings. For the style score, researchers measured the cosine similarity between the style reference and synthesized image embeddings.
Researchers generated a total of 1520 images for 190 text prompts. Although the researchers hoped that the final score would be higher, these indicators are not perfect. However, iterative training (IT) improved the text score, which is in line with the researchers’ goals.
However, as a trade-off, their style score on the first-round model was reduced because they were trained on synthesized images, and style may shift due to selection bias.
DreamBooth on Imagen has a lower style score than StyleDrop (HF’s 0.644 vs. 0.694).
Researchers noticed that the style score increase of DreamBooth on Imagen was not significant (0.569 → 0.644), while the increase of StyleDrop on Muse was more significant (0.556 → 0.694).
(a) DreamBooth, (b) StyleDrop, and (c) qualitative comparison of DreamBooth + StyleDrop:
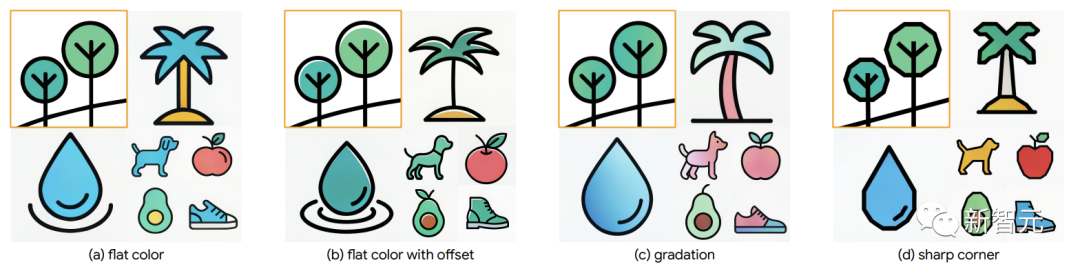
According to researchers, style fine-tuning on Muse is more effective than on Imagen. Additionally, with fine-grained control, StyleDrop captures subtle style differences such as color shifts, layering, or sharp angles.
User Reviews
If designers had StyleDrop, they would work 10 times faster and already take off.
AI in one day, 10 years in the world, AIGC is developing at the speed of light, that kind of dazzling speed!
Tools only follow the trend, those that should be eliminated have already been eliminated long ago.
This tool is much more useful than Midjourney for making logos.
Reference:
https://styledrop.github.io/
We will continue to update Blocking; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Integration of Crypto and AI: Four Key Intersection Points
- SharkTeam: On-Chain Data Analysis of RWA Raceway
- LD Capital: Analysis of L2 Head Liquidity Customization DEX Mechanism of Trader Joe, Izumi, and Maverick
- Aave community initiates a temperature check proposal to integrate MakerDAO’s DSR into Aave V3 Ethereum pool.
- Everything you need to know about LSD Summer
- Decoding Tornado Governance Attack: How to Deploy Different Contracts on the Same Address
- Evening Must-Read | Reasons, Impacts, and Solutions to the Crisis of American Banks






